YOLOv1 이론 및 구현
YOLOv1 Architecture
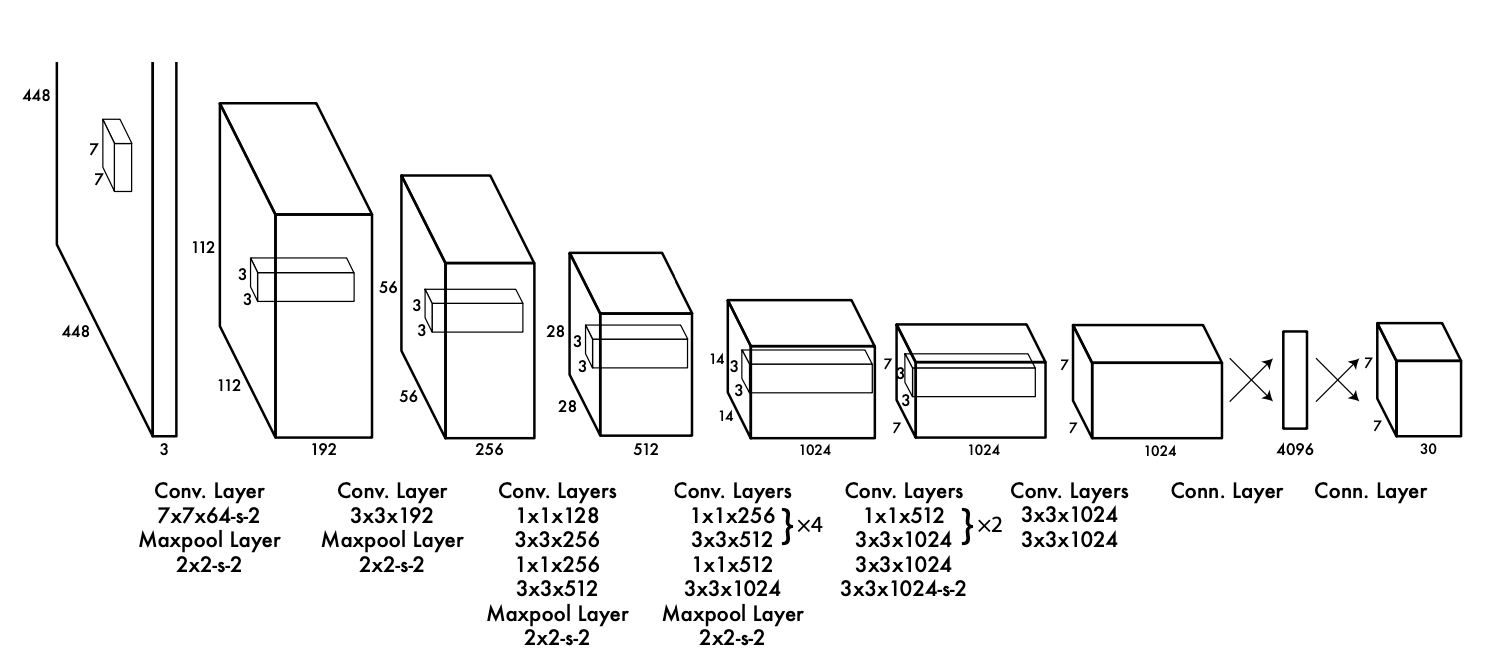
448x448 크기의 이미지를 입력받아 여러층의 Layer를 거쳐 이미지에 있는 객체 위치와 객체의 정체를 알아내는 구조이다.
Object Detection 을 수행하는 모델은 크게 2가지 구조로 나뉜다.
- Backbone
- Head
Backbone은 입력받은 이미지의 특성을 추출하는 역할을 하고 head 에서는 특성이 추출된 특성 맵을 받아 object detection 역할을 수행한다.
Backbone
Backbone은 특성 추출이 목적이기 때문에 특성 추출에 최적화된 모델, 즉 classification을 목적으로 만들어진 모델을 사용한다. Yolo의 저자들은 기존의 Backbone(Ex. VGG16)을 사용하지 않고 DarkNet이라는 모델을 만들었다.
Head
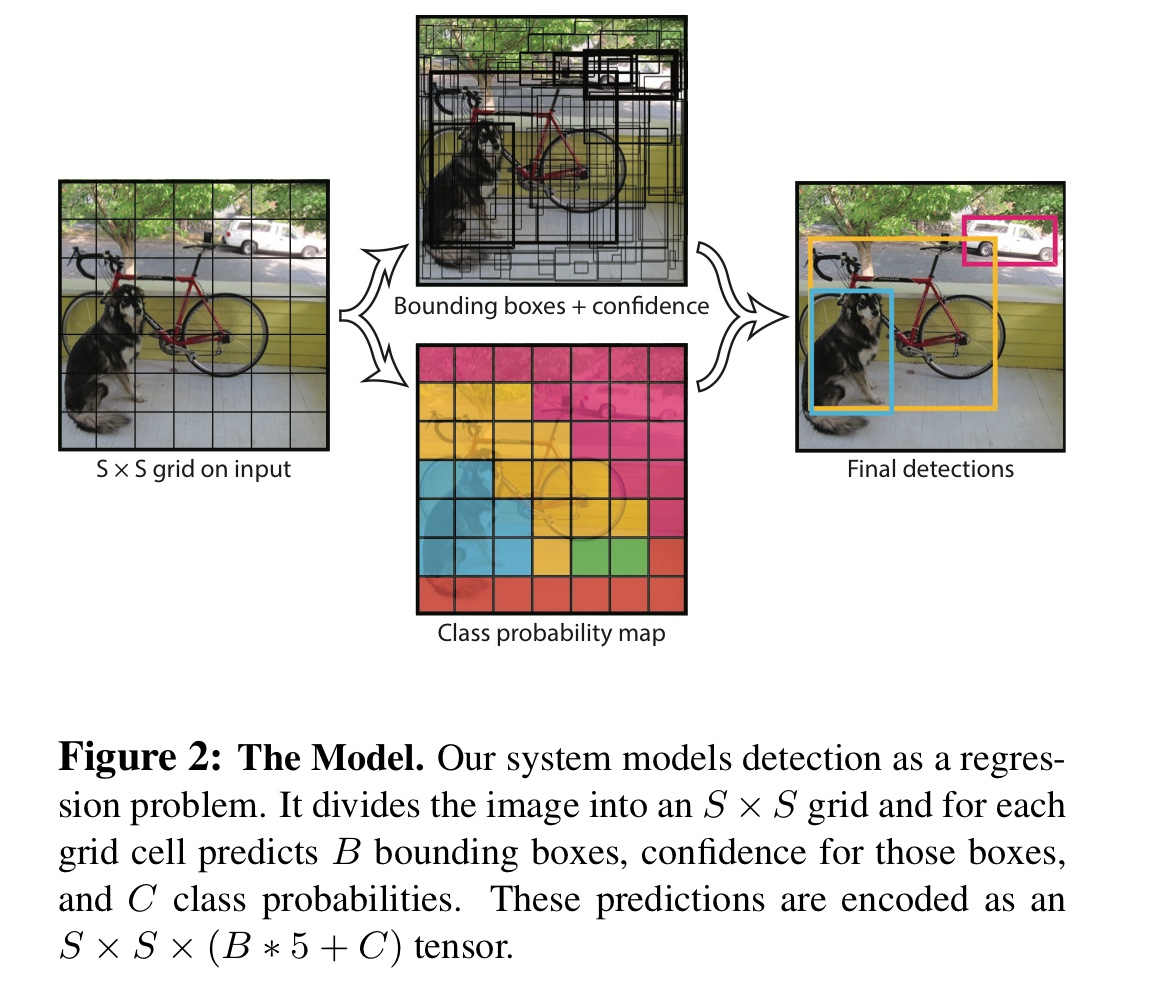
448x448 해상도의 이미지를 입력받을 때 7, 7, 30 사이즈의 3차원 텐서를 출력으로 내놓는다.
측, 출력값의 셀 하나가 원본 이미지의 64x64영역을 대표하고 이 영역에서 검출된 30개의 데이터가 담겨있다는 뜻이다. (448 / 7 = 64)
30개의 데이터는 다음과 같다.
- 해당 영역을 중점으로 하는 객체의 Bounding Box 2개 (x, y, w, h, confidence)
- 해당 영역을 중점으로 하는 객체의 class score 20개
한 셀에서 2개의 bounding box를 검출하기 때문에 총 검출되는 박스는 7 x 7 x 2 = 98개 이다. 이 98개의 박스는 각각의 confidence를 가지고 있다. confidence 는 bounding box를 얼마나 신뢰할 수 있는가를 나타낸 점수라고 볼 수 있다.
confidence = Pr(Object) * IoU
x, y는 해당 셀에 대해 normalize된 값이고 w, h는 전체 이미지에 대해 normalize된 값이다. 예를 들어 (0, 0)셀에서 나온 bounding box의 [x, y, w, h] 가 [0.5, 0.5, 0.2, 0.2]라면 변환 했을 때 x = 31, y = 31, w = 448 * 0.2 = 96, h= 96이다.
(0, 0) 셀은 원본 이미지의 (0, 0) <-> (63, 63)인 사각형을 대표하기 때문이다.
20개의 class score는 해당 영역에서 검출된 객체가 어떤 클래스의 객체일 확률을 클래스 별로 나타낸 것이다. 20은 YOLO를 훈련시킬 때 사용할 PASCAL VOC 2007 dataset에 있는 클래스가 20종류라 20을 사용한 것이다.
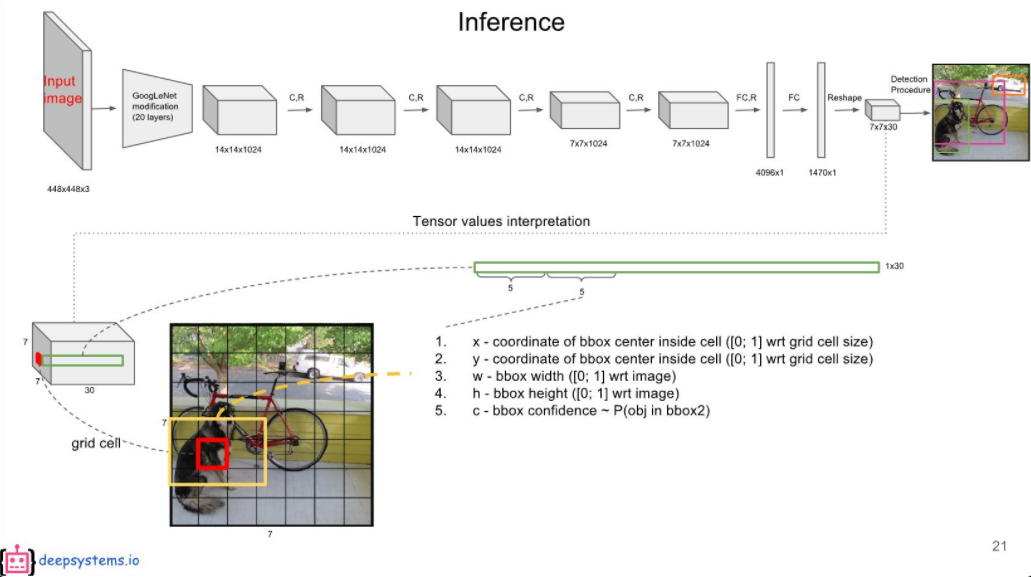
- 입력 이미지 먼저, 448x448 픽셀 크기의 이미지를 입력으로 받는다. 예를 들어, 강아지와 고양이가 있는 사진이라고 가정해보자.
- 그리드 분할 이 이미지를 7x7 그리드로 나눕니다. 각 그리드 셀은 64x64 픽셀(448/7=64) 영역을 담당한다.
- 그리드 셀의 출력 각 그리드 셀은 30개의 값을 출력한다. 이 30개의 값을 자세히 살펴보면:
a) 바운딩 박스 1 (5개 값): - x1: 박스 중심의 x 좌표 (0~1 사이 값, 셀 내에서의 상대적 위치) - y1: 박스 중심의 y 좌표 (0~1 사이 값, 셀 내에서의 상대적 위치) - w1: 박스의 너비 (0~1 사이 값, 전체 이미지 대비 상대적 크기) - h1: 박스의 높이 (0~1 사이 값, 전체 이미지 대비 상대적 크기) - c1: 신뢰도 점수 (0~1 사이 값)
b) 바운딩 박스 2 (5개 값): - x2, y2, w2, h2, c2 (위와 동일한 의미)
c) 클래스 점수 (20개 값): - 각 클래스에 대한 확률 (0~1 사이 값) 예: [개, 고양이, 새, 말, 양, 소, 코끼리, 곰, 얼룩말, 기린, 백팩, 우산, 핸드백, 넥타이, 여행가방, 프리스비, 스키, 스노우보드, 스포츠 공, 연]
구체적인 예시 그리드의 (2,3) 위치에 있는 셀을 예로 들어보면. 이 셀이 다음과 같은 값을 출력했다고 가정해보자:
[0.3, 0.4, 0.5, 0.6, 0.8, 0.2, 0.3, 0.4, 0.5, 0.7, 0.9, 0.05, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
이를 해석하면:
a) 첫 번째 바운딩 박스:
- x1 = 0.3, y1 = 0.4 (셀 내에서의 상대적 위치)
- w1 = 0.5, h1 = 0.6 (전체 이미지 대비 크기)
- c1 = 0.8 (높은 신뢰도)
b) 두 번째 바운딩 박스:
- x2 = 0.2, y2 = 0.3 (셀 내에서의 상대적 위치)
- w2 = 0.4, h2 = 0.5 (전체 이미지 대비 크기)
- c2 = 0.7 (꽤 높은 신뢰도)
c) 클래스 점수:
- [0.9, 0.05, 0, 0, …, 0] 이는 첫 번째 클래스(개)에 대해 90% 확률, 두 번째 클래스(고양이)에 대해 5% 확률을 나타낸다.
실제 좌표 계산 (2,3) 셀의 실제 좌표는 (128, 192)에서 시작한다. (2_64, 3_64). 첫 번째 바운딩 박스의 실제 좌표는:
- 중심 x = 128 + (64 * 0.3) = 147.2
- 중심 y = 192 + (64 * 0.4) = 217.6
- 너비 w = 448 * 0.5 = 224
- 높이 h = 448 * 0.6 = 268.8
최종 해석 이 셀은 개(90% 확률)를 포함하고 있을 가능성이 높으며, 그 개의 위치는 대략 (147, 218)을 중심으로 하고 크기가 224x269 픽셀인 영역에 있을 것으로 예측한다.
이런 방식으로 모든 7x7=49개의 셀에 대해 예측을 수행하고, 이를 종합하여 전체 이미지에서의 객체 검출 결과를 얻게 된다.
활성화 함수
저자는 Linear Activation function과 Leaky ReLU를 사용했다. Linear Activation function는 맨 마지막 Layer에 사용했다. 즉 마지막 레이어를 Logit으로 출력한다. Leaky ReLU는 마지막 Layer를 제외한 모든 레이어에서 사용했다.
Loss function
손실 함수는 multi-task loss를 사용한다.
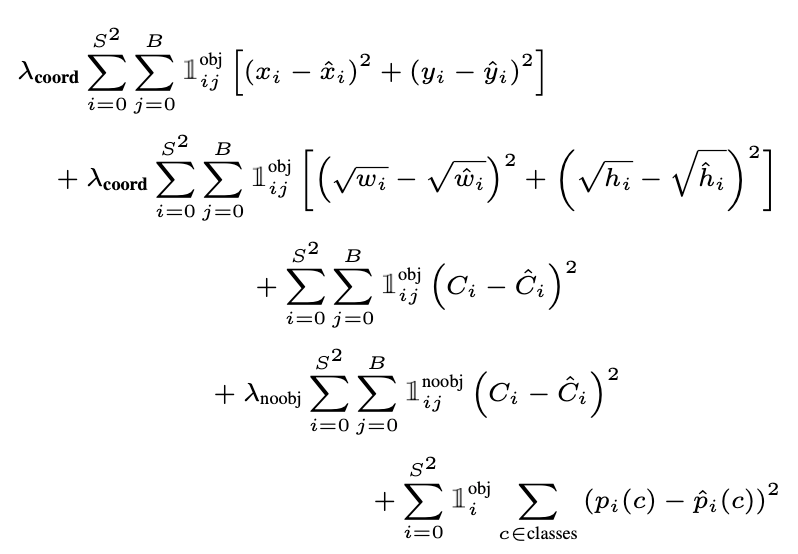
위에서 2줄은 bbox의 위치에 대한 손실(localization loss), 중간 3, 4번째 줄은 confidence score에 관한 손실(confidence loss), 마지막 한줄은 class score에 관한 에러이다 (classification loss)
$\Sigma ^{S^2}$ 에서 $S^2$ 은 전체 cell의 갯수 = 49 이고 B는 각 셀에서 출력하는 bounding box의 갯수 = 2이다. 즉, localization loss, confidence loss는 해당 셀에 실제 객체의 중점이 있을 때 해당 셀에서 출력한 2개의 bounding box 중 Ground Truth Box와 IoU가 더 높은 bounding box와 Ground Truth Box와의 loss를 계산한 것들이다.
그리고 classification loss는 해당 셀에서 실제 객체의 중점이 있을 때 해당 셀에서 얻은 class score와 label data 사이의 loss를 나타낸 값이다.
훈련
- Backbone: ImageNet 2012 dataset으로 1주일간 훈련
- Head : Weight decay = 0.0005, momentum = 0.9, batch size = 65, epoch = 135로 설정. learning rate를 0.001로 맞춘 뒤 epoch=75까지 0.01로 조금씩 상승시킴. 그 후 30회는 0.001로 훈련시키고 마지막 30회는 0.0001로 훈련
- 데이터 증강(Data Augmentation): 전체 이미지 사이즈의 20%만큼 random scaling수행. 그 후 translation도 하며 원본 이미지의 1.5배 만큼 HSV 증가시킴