5. U-Net (Image Segmentation)
데이터 소개
- portrait 데이터로 유명한 PFCN dataset 사용

이미지는 다음과 같은 것을 보여준다.
- 800 x 600의 사람 portrait 이미지
- 사람 영역에 대한 흑백 portrait 이미지
- pfcn_original
- 원본 800 x 600 이미지들
- pfcn_small
- colab용 100 x 75 이미지들
최종 목표
- 작게 줄인 PFCN 데이터를 이용해 사람 영역 추출
- 코앱에 구글 drive 연동
- 큰 사진을 작게 줄이기
- 이미지에 대한 오토인코더식 접근 방법
전처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
"""
데이터 불러오기 (train, test 파일 위치만 바뀜)
"""
import os
import imageio
import numpy as np
# 이미지 파일이 있는 경로
folder_path = 'datasets/pfcn_original/training'
# 이미지 파일 목록 얻기
image_files = os.listdir(folder_path)
# train_images와 train_mattes 배열 초기화
train_images = []
train_mattes = []
# 이미지 파일을 순회하면서 처리
for image_file in image_files:
if image_file.endswith('.png'):
# 이미지 파일 이름에서 '_matte'가 포함된 파일이 있는지 확인
if '_matte' in image_file:
matte_path = os.path.join(folder_path, image_file)
image_id = image_file.split('_matte')[0] # [0] 파일 번호, [1] .png
image_path = os.path.join(folder_path, f'{image_id}.png')
# 이미지와 매트 이미지를 로드
image = imageio.imread(image_path)
matte = imageio.imread(matte_path)
# train_images와 train_mattes 배열에 추가
train_images.append(image)
train_mattes.append(matte)
# NumPy 배열로 변환
train_images = np.array(train_images)
train_mattes = np.array(train_mattes)
1
2
3
4
5
6
7
8
9
10
11
"""
1channel to 3channel
3channel to 1channel
"""
from skimage import color
train_mattes_small = np.array([color.gray2rgb(img) for img in train_mattes_small]) # 1channel to 3channel
test_mattes_small = np.array([color.gray2rgb(img) for img in test_mattes_small])
train_mattes_small = np.array([color.rgb2gray(img).reshape(100, 75, 1) for img in train_mattes_small]) # 3channel to 1channel
test_mattes_small = np.array([color.rgb2gray(img).reshape(100, 75, 1) for img in test_mattes_small])
1
2
3
4
5
6
7
8
9
10
"""
이미지 5장 출력
"""
plt.imshow(np.hstack(train_images[:5]))
plt.show()
# (1700, 800, 600, 3)
plt.imshow(train_images[:5].transpose(1, 0, 2, 3).reshape(800, -1, 3))
plt.show()
모델링 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
"""
train_images train_mattes
(1700, 800, 600, 3) (1700, 800, 600, 1)
"""
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Conv2DTranspose, Input, Reshape
def ae_like_original():
inputs = Input(shape = (800, 600, 3))
x = Conv2D(filters = 32, kernel_size = 3, strides = 2, padding = 'same', activation = 'relu')(inputs)
x = Conv2D(filters = 64, kernel_size = 3, strides = 2, padding = 'same', activation = 'relu')(x)
x = Conv2D(filters = 128, kernel_size = 3, strides = 2, padding = 'same', activation = 'relu')(x)
x = Conv2D(filters = 256, kernel_size = 3, strides = 2, padding = 'same', activation = 'relu')(x)
x = Conv2D(filters = 512, kernel_size = 3, strides = 2, padding = 'same', activation = 'relu')(x)
x = Flatten()(x)
latent_vector = Dense(units = 50)(x)
x = Dense((25 * 20 * 512))(latent_vector)
x = Reshape((25, 20, 512))(x)
x = Conv2DTranspose(filters = 512, kernel_size = 3, strides = (2, 2), padding = 'same', activation = 'relu')(x)
x = Conv2DTranspose(filters = 256, kernel_size = 3, strides = (2, 3), padding = 'same', activation = 'relu')(x)
x = Conv2DTranspose(filters = 128, kernel_size = 3, strides = (2, 5), padding = 'same', activation = 'relu')(x)
x = Conv2DTranspose(filters = 64, kernel_size = 3, strides = (2, 1), padding = 'same', activation = 'relu')(x)
x = Conv2DTranspose(filters = 32, kernel_size = 3, strides = (2, 1), padding = 'same', activation = 'relu')(x)
x = Conv2DTranspose(filters = 1, kernel_size = 3, strides = (1, 1), padding = 'same', activation = 'sigmoid')(x)
model = Model(inputs, x)
return model
model_original = ae_like_original()
model_original.summary()
"""
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 800, 600, 3)] 0
conv2d (Conv2D) (None, 400, 300, 32) 896
conv2d_1 (Conv2D) (None, 200, 150, 64) 18496
conv2d_2 (Conv2D) (None, 100, 75, 128) 73856
conv2d_3 (Conv2D) (None, 50, 38, 256) 295168
conv2d_4 (Conv2D) (None, 25, 19, 512) 1180160
flatten (Flatten) (None, 243200) 0
dense (Dense) (None, 50) 12160050
dense_1 (Dense) (None, 256000) 13056000
reshape (Reshape) (None, 25, 20, 512) 0
conv2d_transpose (Conv2DTr (None, 50, 40, 512) 2359808
anspose)
conv2d_transpose_1 (Conv2D (None, 100, 120, 256) 1179904
Transpose)
conv2d_transpose_2 (Conv2D (None, 200, 600, 128) 295040
Transpose)
conv2d_transpose_3 (Conv2D (None, 400, 600, 64) 73792
Transpose)
conv2d_transpose_4 (Conv2D (None, 800, 600, 32) 18464
Transpose)
conv2d_transpose_5 (Conv2D (None, 800, 600, 1) 289
Transpose)
=================================================================
Total params: 30711923 (117.16 MB)
Trainable params: 30711923 (117.16 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
"""
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
"""
축소한 이미지
input (100, 75, 3), output (100, 75, 1)
"""
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Conv2D, Flatten, UpSampling2D, Input, Reshape
def ae_like():
inputs = Input(shape = (100, 75, 3))
x = Conv2D(filters = 32, kernel_size = 3, strides = 2, padding = 'same', activation = 'relu')(inputs)
x = Conv2D(filters = 64, kernel_size = 3, strides = 2, padding = 'same', activation = 'relu')(x)
x = Conv2D(filters = 128, kernel_size = 3, strides = 2, padding = 'same', activation = 'relu')(x)
x = Flatten()(x)
latent_vector = Dense(units = 10)(x)
x = Dense(13 * 10 * 128)(latent_vector)
x = Reshape((13, 10, 128))(x)
x = UpSampling2D(size = (2, 2))(x)
x = Conv2D(128, (2, 2), (1, 1), activation = 'relu', padding = 'valid')(x)
x = UpSampling2D(size = (2, 2))(x)
x = Conv2D(64, (1, 1), (1, 1), activation = 'relu', padding = 'valid')(x)
x = UpSampling2D(size = (2, 2))(x)
x = Conv2D(32, (1, 2), (1, 1), activation = 'relu', padding = 'valid')(x)
x = Conv2D(1, (1, 1), (1, 1), activation = 'sigmoid')(x)
model = Model(inputs, x)
return model
model = ae_like()
model.summary()
"""
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) [(None, 100, 75, 3)] 0
conv2d_34 (Conv2D) (None, 50, 38, 32) 896
conv2d_35 (Conv2D) (None, 25, 19, 64) 18496
conv2d_36 (Conv2D) (None, 13, 10, 128) 73856
flatten_3 (Flatten) (None, 16640) 0
dense_6 (Dense) (None, 10) 166410
dense_7 (Dense) (None, 16640) 183040
reshape_3 (Reshape) (None, 13, 10, 128) 0
up_sampling2d_3 (UpSamplin (None, 26, 20, 128) 0
g2D)
conv2d_37 (Conv2D) (None, 25, 19, 128) 65664
up_sampling2d_4 (UpSamplin (None, 50, 38, 128) 0
g2D)
conv2d_38 (Conv2D) (None, 50, 38, 64) 8256
up_sampling2d_5 (UpSamplin (None, 100, 76, 64) 0
g2D)
conv2d_39 (Conv2D) (None, 100, 75, 32) 4128
conv2d_40 (Conv2D) (None, 100, 75, 1) 33
=================================================================
Total params: 520779 (1.99 MB)
Trainable params: 520779 (1.99 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
"""
모델 학습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
model.complie(loss = 'mse', optimizer = 'adam', metrics = ['accuracy'])
model.original.compile(loss = 'mae', optimizer = 'adam', metrics = ['accuracy'])
ea_hist = model.fit(
train_images_small,
train_mattes_small,
validation_data = (
test_images_small,
test_mattes_small
),
epochs = 25,
batch_size = 128,
verbose = 1
)
결과 확인
1
2
3
4
5
res = model.predict(test_images_small[1:2])
# res, test_mattes[1]를 width 방향으로 결합하여 (100, 75 * 3, 1) 의 이미지를 만들어 plt로 출력
plt.imshow(np.concatenate([res[0], test_mattes_small[1]], axis = 1))
plt.show()
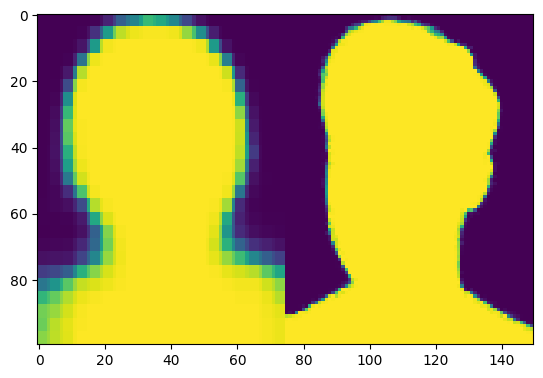
1
2
3
# res를 0.5 기준으로 0, 1의 값으로 이원화 시킨 뒤 출력
plt.imshow(np.concatenate([res[0] > 0.5, test_mattes_small[1]], axis = 1))
plt.imshow()
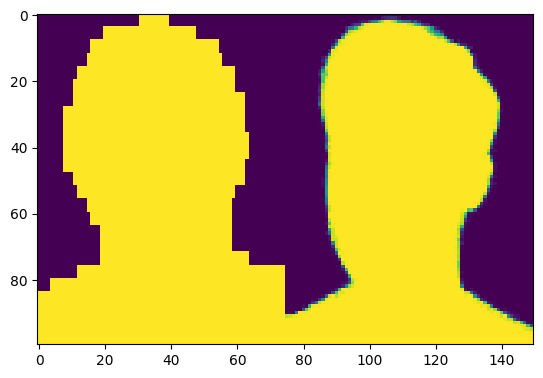
1
2
3
4
5
6
# 5장의 이미지를 모델에 넣고 결과를 22번과 같은 방식으로 비교하는 코드 작성
res_five = (model.predict(test_images_small[:5]) > 0.5).astype(np.float64)
plt.imshow(np.concatenate([res_five, test_mattes_small[:5]], axis = 2).transpose(1, 0, 2, 3).reshape(100, -1), cmap = 'gray')
plt.imshow()
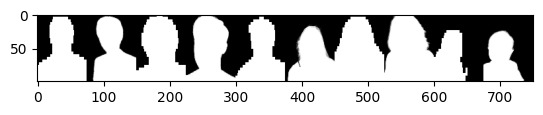
1
2
3
# 예측 이미지와 원본 이미지를 곱해 배경 제거
plt.imshow(res_five[1].reshape(100, 75, 1) * test_images_small[1])
plt.show()
U-Net 모델링
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
# input (100, 75, 3), output (100, 75, 1)을 처리할 수 있는 모래시계 모양의 모델
from keras.models import Model
from keras.layers import Input, Conv2D, Conv2DTranspose
from keras.layers import BatchNormalization, Dropout, Activation, MaxPool2D, concatenate
def conv2d_block(x, channel):
x = Conv2D(filters = channel, kernel_size = 3, padding = 'same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters = channel, kernel_size = 3, padding = 'same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
return x
def unet_like():
inputs = Input(shape = (100, 75, 3))
c1 = conv2d_block(inputs, 16)
p1 = MaxPool2D(pool_size = (2, 2))(c1)
p1 = Dropout(0.1)(p1)
c2 = conv2d_block(p1, 32)
p2 = MaxPool2D(pool_size = (2, 2))(c2)
p2 = Dropout(0.1)(p2)
c3 = conv2d_block(p2, 64)
p3 = MaxPool2D(pool_size = (2, 2))(c3)
p3 = Dropout(0.1)(p3)
c4 = conv2d_block(p3, 128)
p4 = MaxPool2D(pool_size = (2, 2))(c4)
p4 = Dropout(0.1)(p4)
c5 = con2d_block(p4, 256)
u6 = Conv2DTranspose(filters = 128, kernel_size = 2, strides = 2, output_padding = (0, 1))(c5)
u6 = concatenate([u6, c4])
u6 = Dropout(0.1)(u6)
c6 = conv2d_block(u6, 128)
u7 = Conv2DTranspose(filters = 64, kernel_size = 2, strides = 2, output_padding = (1, 0))(c6)
u7 = concatenate([u7, c3])
u7 = Dropout(0.1)(u7)
c7 = conv2d_block(u7, 64)
u8 = Conv2DTranspose(filters = 32, kernel_size = 2, strides = 2, output_padding = (0, 1))(c7)
u8 = concatenate([u8, c2])
u8 = Dropout(0.1)(u8)
c8 = conv2d_block(u8, 32)
u9 = Conv2DTranspose(filters = 16, kernel_size = 2, strides = 2, output_padding = (0, 1))(c8)
u9 = concatenate([c9, c1])
u9 = Dropout(0.1)(u9)
c9 = conv2d_block(u9, 16)
outputs = Conv2D(filters = 1, kernel_size = 1, activation = 'sigmoid')(c9)
model = Model(inputs = outputs)
return model
model_unet = unet_like()
model_unet.summary()
"""
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_4 (InputLayer) [(None, 100, 75, 3)] 0 []
conv2d_15 (Conv2D) (None, 100, 75, 16) 448 ['input_4[0][0]']
batch_normalization (Batch (None, 100, 75, 16) 64 ['conv2d_15[0][0]']
Normalization)
activation (Activation) (None, 100, 75, 16) 0 ['batch_normalization[0][0]']
conv2d_16 (Conv2D) (None, 100, 75, 16) 2320 ['activation[0][0]']
batch_normalization_1 (Bat (None, 100, 75, 16) 64 ['conv2d_16[0][0]']
chNormalization)
activation_1 (Activation) (None, 100, 75, 16) 0 ['batch_normalization_1[0][0]'
]
max_pooling2d (MaxPooling2 (None, 50, 37, 16) 0 ['activation_1[0][0]']
D)
dropout (Dropout) (None, 50, 37, 16) 0 ['max_pooling2d[0][0]']
conv2d_17 (Conv2D) (None, 50, 37, 32) 4640 ['dropout[0][0]']
batch_normalization_2 (Bat (None, 50, 37, 32) 128 ['conv2d_17[0][0]']
chNormalization)
activation_2 (Activation) (None, 50, 37, 32) 0 ['batch_normalization_2[0][0]'
]
conv2d_18 (Conv2D) (None, 50, 37, 32) 9248 ['activation_2[0][0]']
batch_normalization_3 (Bat (None, 50, 37, 32) 128 ['conv2d_18[0][0]']
chNormalization)
activation_3 (Activation) (None, 50, 37, 32) 0 ['batch_normalization_3[0][0]'
]
max_pooling2d_1 (MaxPoolin (None, 25, 18, 32) 0 ['activation_3[0][0]']
g2D)
dropout_1 (Dropout) (None, 25, 18, 32) 0 ['max_pooling2d_1[0][0]']
conv2d_19 (Conv2D) (None, 25, 18, 64) 18496 ['dropout_1[0][0]']
batch_normalization_4 (Bat (None, 25, 18, 64) 256 ['conv2d_19[0][0]']
chNormalization)
activation_4 (Activation) (None, 25, 18, 64) 0 ['batch_normalization_4[0][0]'
]
conv2d_20 (Conv2D) (None, 25, 18, 64) 36928 ['activation_4[0][0]']
batch_normalization_5 (Bat (None, 25, 18, 64) 256 ['conv2d_20[0][0]']
chNormalization)
activation_5 (Activation) (None, 25, 18, 64) 0 ['batch_normalization_5[0][0]'
]
max_pooling2d_2 (MaxPoolin (None, 12, 9, 64) 0 ['activation_5[0][0]']
g2D)
dropout_2 (Dropout) (None, 12, 9, 64) 0 ['max_pooling2d_2[0][0]']
conv2d_21 (Conv2D) (None, 12, 9, 128) 73856 ['dropout_2[0][0]']
batch_normalization_6 (Bat (None, 12, 9, 128) 512 ['conv2d_21[0][0]']
chNormalization)
activation_6 (Activation) (None, 12, 9, 128) 0 ['batch_normalization_6[0][0]'
]
conv2d_22 (Conv2D) (None, 12, 9, 128) 147584 ['activation_6[0][0]']
batch_normalization_7 (Bat (None, 12, 9, 128) 512 ['conv2d_22[0][0]']
chNormalization)
activation_7 (Activation) (None, 12, 9, 128) 0 ['batch_normalization_7[0][0]'
]
max_pooling2d_3 (MaxPoolin (None, 6, 4, 128) 0 ['activation_7[0][0]']
g2D)
dropout_3 (Dropout) (None, 6, 4, 128) 0 ['max_pooling2d_3[0][0]']
conv2d_23 (Conv2D) (None, 6, 4, 256) 295168 ['dropout_3[0][0]']
batch_normalization_8 (Bat (None, 6, 4, 256) 1024 ['conv2d_23[0][0]']
chNormalization)
activation_8 (Activation) (None, 6, 4, 256) 0 ['batch_normalization_8[0][0]'
]
conv2d_24 (Conv2D) (None, 6, 4, 256) 590080 ['activation_8[0][0]']
batch_normalization_9 (Bat (None, 6, 4, 256) 1024 ['conv2d_24[0][0]']
chNormalization)
activation_9 (Activation) (None, 6, 4, 256) 0 ['batch_normalization_9[0][0]'
]
conv2d_transpose_9 (Conv2D (None, 12, 9, 128) 131200 ['activation_9[0][0]']
Transpose)
concatenate (Concatenate) (None, 12, 9, 256) 0 ['conv2d_transpose_9[0][0]',
'activation_7[0][0]']
dropout_4 (Dropout) (None, 12, 9, 256) 0 ['concatenate[0][0]']
conv2d_25 (Conv2D) (None, 12, 9, 128) 295040 ['dropout_4[0][0]']
batch_normalization_10 (Ba (None, 12, 9, 128) 512 ['conv2d_25[0][0]']
tchNormalization)
activation_10 (Activation) (None, 12, 9, 128) 0 ['batch_normalization_10[0][0]
']
conv2d_26 (Conv2D) (None, 12, 9, 128) 147584 ['activation_10[0][0]']
batch_normalization_11 (Ba (None, 12, 9, 128) 512 ['conv2d_26[0][0]']
tchNormalization)
activation_11 (Activation) (None, 12, 9, 128) 0 ['batch_normalization_11[0][0]
']
conv2d_transpose_10 (Conv2 (None, 25, 18, 64) 32832 ['activation_11[0][0]']
DTranspose)
concatenate_1 (Concatenate (None, 25, 18, 128) 0 ['conv2d_transpose_10[0][0]',
) 'activation_5[0][0]']
dropout_5 (Dropout) (None, 25, 18, 128) 0 ['concatenate_1[0][0]']
conv2d_27 (Conv2D) (None, 25, 18, 64) 73792 ['dropout_5[0][0]']
batch_normalization_12 (Ba (None, 25, 18, 64) 256 ['conv2d_27[0][0]']
tchNormalization)
activation_12 (Activation) (None, 25, 18, 64) 0 ['batch_normalization_12[0][0]
']
conv2d_28 (Conv2D) (None, 25, 18, 64) 36928 ['activation_12[0][0]']
batch_normalization_13 (Ba (None, 25, 18, 64) 256 ['conv2d_28[0][0]']
tchNormalization)
activation_13 (Activation) (None, 25, 18, 64) 0 ['batch_normalization_13[0][0]
']
conv2d_transpose_11 (Conv2 (None, 50, 37, 32) 8224 ['activation_13[0][0]']
DTranspose)
concatenate_2 (Concatenate (None, 50, 37, 64) 0 ['conv2d_transpose_11[0][0]',
) 'activation_3[0][0]']
dropout_6 (Dropout) (None, 50, 37, 64) 0 ['concatenate_2[0][0]']
conv2d_29 (Conv2D) (None, 50, 37, 32) 18464 ['dropout_6[0][0]']
batch_normalization_14 (Ba (None, 50, 37, 32) 128 ['conv2d_29[0][0]']
tchNormalization)
activation_14 (Activation) (None, 50, 37, 32) 0 ['batch_normalization_14[0][0]
']
conv2d_30 (Conv2D) (None, 50, 37, 32) 9248 ['activation_14[0][0]']
batch_normalization_15 (Ba (None, 50, 37, 32) 128 ['conv2d_30[0][0]']
tchNormalization)
activation_15 (Activation) (None, 50, 37, 32) 0 ['batch_normalization_15[0][0]
']
conv2d_transpose_12 (Conv2 (None, 100, 75, 16) 2064 ['activation_15[0][0]']
DTranspose)
concatenate_3 (Concatenate (None, 100, 75, 32) 0 ['conv2d_transpose_12[0][0]',
) 'activation_1[0][0]']
dropout_7 (Dropout) (None, 100, 75, 32) 0 ['concatenate_3[0][0]']
conv2d_31 (Conv2D) (None, 100, 75, 16) 4624 ['dropout_7[0][0]']
batch_normalization_16 (Ba (None, 100, 75, 16) 64 ['conv2d_31[0][0]']
tchNormalization)
activation_16 (Activation) (None, 100, 75, 16) 0 ['batch_normalization_16[0][0]
']
conv2d_32 (Conv2D) (None, 100, 75, 16) 2320 ['activation_16[0][0]']
batch_normalization_17 (Ba (None, 100, 75, 16) 64 ['conv2d_32[0][0]']
tchNormalization)
activation_17 (Activation) (None, 100, 75, 16) 0 ['batch_normalization_17[0][0]
']
conv2d_33 (Conv2D) (None, 100, 75, 1) 17 ['activation_17[0][0]']
==================================================================================================
Total params: 1946993 (7.43 MB)
Trainable params: 1944049 (7.42 MB)
Non-trainable params: 2944 (11.50 KB)
__________________________________________________________________________________________________
"""
모델 학습
1
2
3
4
5
6
7
8
9
10
11
12
13
model_unet.compile(loss = 'mse', optimizer = 'adam', metrics = ['accuracy'])
unet_hist = model_unet.fit(
train_images_small,
train_mattes_small,
validation_data = (
test_images_small,
test_mattes_small
),
epochs = 25,
batch_size = 128,
verbose = 1
)
결과 확인
1
2
3
res = model_unet.predict(test_images_small[1:2])
# Auto-Encoder보다 성능 좋음
This post is licensed under CC BY 4.0 by the author.