5. Tips for Training GANs
1. Normalize the inputs
- 이미지는 픽셀 값이 0 ~ 255값을 가지고 있는데 이 값을 가지는 이미지를 -1 ~ 1로 노멀라이즈 하는것이 학습시에 유리하다.
- Generator의 output layer에는 tanh를 사용
</br> </br>
2. A modified loss function (수정된 손실함수)
- GAN 논문에서 G를 최적화 하기 위한 손실함수는 $min(log 1- D)$ 이지만, 실제로 사람들은 대부분 $max(log(D))$ 를 사용.
- 이는 첫번째 수식이 초기에 그래디언트 소실 문제를 가지고 있기 때문
- 실제로, 다음과 같은 접근 방식이 잘 작동
- 생성자를 훈련할 때 레이블을 뒤집는다. 실제 = 가짜, 가짜 = 실제 (즉 실제 데이터 레이블을 가짜 데이터에 적용하고, 가짜 데이터 레이블을 실제 데이터에 적용)
- 이는 생성자가 판별자를 더욱 효과적으로 속이도록 만들어, 생성자가 더 현실적인 데이터를 생성하도록 장려하는데 도움.
이러한 수정된 손실 함수는 초기에 사라지는 그래디언트 소실 문제를 해결하기 위해 사용한다. 생성자를 훈련할 때 레이블을 뒤집음으로써 이러한 접근 방식이 실제로 잘 동작하는것으로 나타남
</br> </br>
3. Use a spherical Z(구 형태의 Z 사용)
Uniform distribution 이 아닌 Gaussian distribution을 사용

- 균일 분포에서 샘플링 하지 않음
- 가우시간 분포에서 샘플링
- 보간시 직선이 아닌 큰 원을 통해 보간을 수행
이 접근 방식은 생성자의 입력인 잠재 공간 벡터 Z를 균일하게 분포에서 샘플링 하는 대신 가우시간 분포에서 샘플링 하는 것을 제안. 이로 인해 작은 원 형태의 분포가 만들어지며, 보간을 할 때는 직선대신 큰 원을 따라 보간을 수행. 이러한 방식은 생성된 이미지의 다양성을 증대시키고 더 자연스러운 보간을 가능하게 함.
</br> </br>
4. Batch normalization
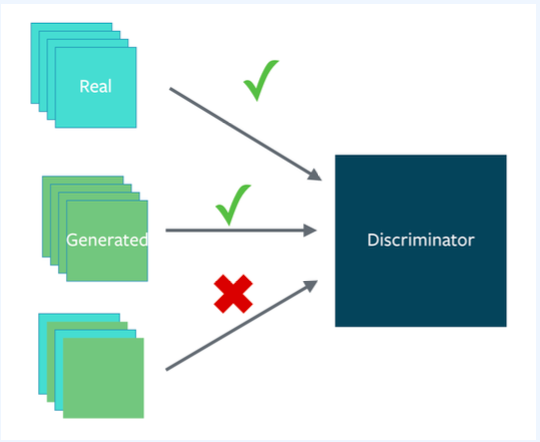
- 실제와 가짜에 대해 서로 다른 미니 배치 구성
- 즉, 각 미니 배치는 모두 실제 이미지 또는 생성된 이미지만을 포함해야 함.
- 배치 정규화를 사용할 수 없을땐 인스턴스 정규화 사용 (배치 정규화는 배치 4부터 사용 가능)
- 각 샘플마다 평균을 빼고 표준편차로 나눔으로써 수행
이러한 접근 방식은 GAN의 훈련 과정에서 발생할 수 있는 문제를 해결하기 위한 기법들로 실제 이미지와 생성된 이미지를 구분하여 각각 다른 미니 배치를 형성함으로써 모델의 훈련을 안정화시키고, 배치 정규화 대신 인스턴스 정규화를 사용해 모델의 성능을 향상시킨다.
- 인스턴스 정규화(Instance Normalization)는 배치 정규화(Batch Normalization)와 다른 정규화 기법
배치 정규화: 배치 정규화는 각 feature map의 값들을 정규화할 때 전체 배치에 대한 평균과 분산을 사용하여 모든 데이터에 대해 동일한 분포를 갖도록 조정
인스턴스 정규화: 각각의 샘플(instance)에 대해 feature map의 값들을 정규화. 이는 배치 단위가 아닌 각각의 데이터 샘플에 대한 분포를 정규화
</br> </br>
5. Avoid sparse gradients: ReLU, MaxPool
- GAN 게임의 안정성이 희소 그래디언트를 가질 때 저하됨
- LeakyReLU는 좋음(생성자와 판별자 양쪽에서)
- 다운샘플링에는 다음을 사용: Average pooling, Conv2d + Stride
- 업샘플링에는 다음을 사용: PixelShuffle, ConvTranspose2d + Stride
이러한 접근 방식은 GAN의 훈련 안정성을 향상시키기 위한 기법. ReLU대신 LeakyReLU를 사용해 희소 그래디언트를 방지하고, 다운 샘플링에는 Average Pooling이나 Conv2d와 Stride를 사용하여 희소성을 감소. 업샘플링에는 PixelShuffle이나 ConvTranspose2d와 Stride를 사용해 희소 그래디언틀르 피한다. PixelShuffle은 업샘플링에 사용되는 효율적인 방법 중 하나로, 고 해상도 이미지를 생성하기 위해 픽셀을 섞는 방식을 제안
- 희소 그래디언트 : 학습 과정 중에 일부 가중치가 거의 업데이트되지 않거나 업데이트가 거의 이루어지지 않는 현상
- 이는 주로 ReLU와 MaxPool과 같은 활성화 함수나 layer에서 발생. 이러한 함수들은 입력의 일부에 대해 출력을 생성하지 않기 때문에 해당 영역에 대한 그래디언트 업데이트가 거의 없게된다.
</br> </br>
6. Use soft and noisy labels
- Label Smoothing 적용: 예를 들어, 두 가지 목표 레이블이 있는 경우(Real = 1, Fake = 0), 각각의 샘플에 대해 실제 샘플인 경우 레이블을 0.7에서 1.2사이의 임의의 숫자로 대체하고, 가짜 샘플인 경우, 0.0에서 0.3 사이의 임의의 숫자로 대체
- 판별자의 학습을 위해 label을 noisy하게 만들기: 판별자를 훈련할 때 레이블을 가끔씩 뒤집는다.
이러한 접근 방식은 GAN의 훈련을 안정화시키고, 모델이 특정 라벨에 과도하게 의존하는 것을 방지하기 위한 것이다. Label Smoothing은 실제와 가짜 라벨 간의 간격을 줄여서 모델을 더 부드럽게 훈련시키고, Noisy Labels은 판별자가 다양한 유형의 입력에 대해 더 견고하게 학습하도록 돕는다. 이러한 기법들은 특히 모드 붕괴와 같은 문제를 완화하기 위해 사용된다.
</br> </br>
7. DCGAN / Hybrid models
- 가능하면 DCGAN사용.
- DCGAN을 사용할 수 없거나 모델이 안정적이지 않은 경우, KL+GAN 또는 VAE+GAN과 같은 하이브리드 모델을 사용
이러한 접근 방식은 GAN의 훈련 안정성과 생성 품질을 향상시킬 수 있는 방법을 제공한다. DCGAN은 이미지 생성에 있어서 안정적이고 효과적인 방법으로 알려져 있으며, 대부분의 경우에 사용될 수 있다. 그러나 DCGAN이 적절하지 않은 경우에는 KL divergence나 VAE(Variational Autoencoder) 와 GAN을 결합한 하이브리드 모델을 사용할 수 있다. 이러한 모델은 다양한 손실함수 및 생성 네트워크 구조를 결합하여 안정적이고 다양한 종류의 데이터 생성에 적합한 모델을 만들 수 있다.
</br> </br>
8. Use stability tricks from RL (강화학습에서의 안정성 트릭 활용)
- 경험 재생(Experience Replay)
- 과거의 생성물의 재생 버퍼를 유지하고 때때로 이들을 보여준다
- 과거의 G와 D의 체크포인트를 유지하고 때떄로 몇 번의 반복동안 이들을 교체한다
- Deep Deterministic Policy Gradients 적용되는 모든 안정성 트릭
이러한 안정성 트릭은 GAN의 훈련 안정성을 향상시키고 모드 붕괴와 같은 문제를 완화하는 데 도움이 될 수 있다. 경험 재생(Experience Replay)은 이전 생성물을 기록하여 훈련에 사용함으로써 생성자와 판별자의 학습을 안정화시키고 다양성을 증가시킨다. 또한, 과거의 체크포인트를 유지하고 교체함으로써 훈련 과정을 안정화시키는 것도 중요한 전략이다. 이러한 트릭들은 강화 학습에서의 안정성에 관한 연구에서 영감을 받았으며, GAN의 훈련에도 유용하게 적용될 수 있다.
</br> </br>
9. Use the Adam optimizer
- Adam optimizer가 좋다
- Discriminator에는 SGD를 Generator에는 Adam을 사용것이 좋다고 함
</br> </br>
10. Track failurse early (초기에 실패를 추적)
- D손실이 0으로 감 : 실패 모드
- 그래디언트의 Norm 체크 : 그 값이 100을 초과하면 문제가 발생할 수 있음
- 작업이 잘 되고 있을 때, D 손실의 분산이 낮고 시간이 지남에 따라 감소하는 경향이 있다. vs 큰 분산과 급증이 있는 경우
- 생성자의 손실이 지속적으로 감소하는 경우, 그것은 D를 쓰레기로 속이고 있다고 함
이러한 접근 방식은 GAN의 훈련을 모니터링하고 초기에 문제를 감지하여 조치할 수 있도록 도와준다. 생성자와 판별자의 손실을 모니터링하여 이상 현상을 식별하고, 그래디언트의 Norm을 확인하여 훈련의 안정성을 판단할 수 있다. 이러한 신호들은 훈련 과정에서 발생하는 문제를 신속하게 파악하여 조치를 취할 수 있도록 도와준다.
</br> </br>
11. Don’t balance loss via statistics (unless you have a good reason to)
1
통계를 통한 손실 균형화를 피하라 (합당한 이유가 없는 경우) - G의 loss와 D의 loss의 균형을 맞추려고 시도하지 마라 - 이것은 어렵고 우리가 모두 시도해 봤다 - 시도한다면 직관보다 원칙적인 접근 방식을 가져라 예를들어
1
2
3
4
5
while lossD > A:
train D
while lossG > B:
train G
이것은 GAN의 훈련을 안정화하기 위해 손실의 균형을 맞추는 데 있어서 통계적인 방식을 사용하는것을 권장하지 않는다는 것을 강조. 손실의 균형을 맞추는 것은 종종 복잡하고 효과적인 방법이 아닐 수 있으며, 대부분의 경우에는 원칙적인 접근 방식이 더 나은 결과를 가져올 수 있다. 만약 이 방법을 시도한다면, 손실 값에 기반해 훈련 과정을 동적으로 조정하는 것이 중요하다.
</br> </br>
12. If you have labels, use them
- label이 있는 경우, 판별자가 샘플을 분류하는 것 또한 훈련시키는 것이 좋다: 보조 GANs
이것은 GAN의 훈련에 있어서 레이블 정보를 활용하는 방법 중 하나로 레이블이 제공된다면, 판별자가 생성된 샘플을 분류하는 데 도움이 되도록 훈련시키는 것이 가능하다. 이러한 방식을 보조 GANs라 한다. 이것은 레이블 정보를 활용해 생성자와 판별자의 훈련을 더욱 효율적으로 만들어 줄 수 있다.
</br> </br>
13. Add noise to inputs, decay over time
1
(입력에 노이즈를 추가하고 시간이 지남에 따라 감쇠시킨다.)
- D에 인위적인 노이즈를 추가한다.
- 생성자의 각 레이어에 가우시안 노이즈를 추가한다.
- 개선된 GANs: OpenAI 코드에도 포함되어 있다
이 방법은 GAN훈련을 안정화하기 위한 기술 중 하나이다. 판별자의 입력에 인위적인 노이즈를 추가함으로써 GAN의 학습 과정을 안정화시킬 수 있다. 노이즈는 시간이 지남에 따라 점차적으로 감쇠되어야 한다. 또한 생성자의 각 레이어에 가우시안 노이즈를 추가함으로써 GAN의 안정성을 향상시킬 수 있다. 이러한 방법은 GAN의 훈련을 더욱 강력하고 안정적으로 만들어주는 데 도움이 될 수 있다.
</br> </br>
14. Conclusion
- 이런 연구 및 기술들은 임시 방편이고 이후에 다양하게 실험적으로 또는 이론적으로 증명 된 트릭들이 공개 되었다.