Seq2Seq 논문 리뷰
| 태그 | #NLP |
|---|---|
| 한줄요약 | Seq2Seq |
| Journal/Conference | #Arxiv |
| Link | Seq2Seq |
| Year(출판년도) | 2014 |
| 저자 | Jeffrey Pennington, Richard Socher, and Christopher Manning |
| 원문 링크 | Seq2Seq |
Abstract
심층 신경망은 다양한 task에 대해서 놀라운 성능을 내왔지만, sequence와 sequence를 맵핑할수 없다. 저자들은 sequence의 구조에 대한 가정을 최소한으로 한 end-to-end sequence학습 방법을 제안한다. 이 모델은 한 multilayered LSTM으로 입력 sequence를 고정된 차원의 벡터로 인코딩하고, 또다른 LSTM으로 인코딩되니 벡터를 target sequence로 디코딩하는 구조를 가지고 있다. LSTM이 단어 순서에 민감하고, 수동태와 능동태에 대해 차이가 없는 특징을 가짐을 보였고, source 문장 내 단어들의 순서를 역순으로 바꿔 학습하여 성능 향상으로 이끌었다.
Introduction
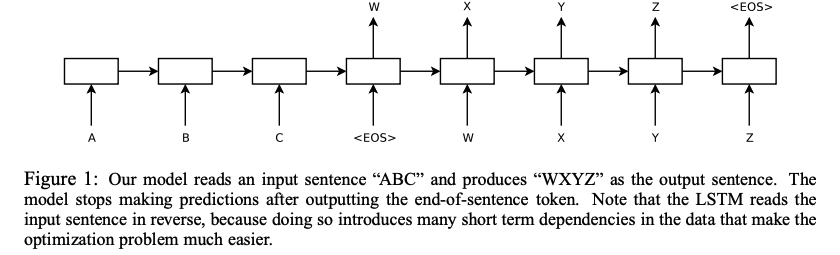
어려운 문제에도 뛰어난 성능을 보이고, 큰 모델 학습도 가능한 유연성에도 불구하고, 심층 신경망은 고정된 크기의 input과 output에 대해서만 적용될 수 있다. 저자들은 LSTM을 이용하여 sequence to sequence 문제를 해결하였다. 하나의 LSTM으로 input sequence를 timestep마다 하나씩 읽어서 크고 고정된 차원의 벡터 representation을 만든다. 또다른 LSTM을 이용하여 representation를 output sequence로 맵핑한다. input과 output의 큰 시차가 존재하기 때문에 long range temporal dependecy의 데이터도 잘 학습하는 LSTM를 선택하였다.
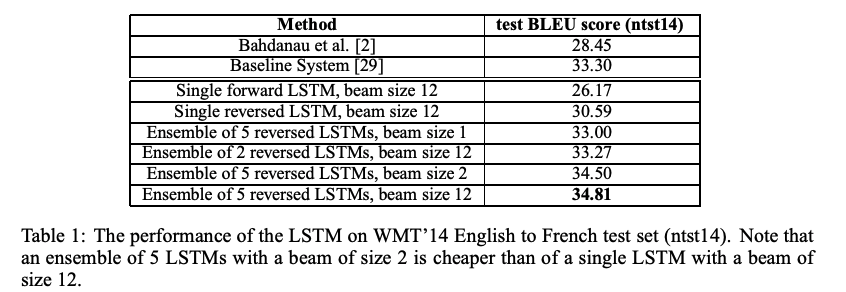
해당 모델은 5개의 LSTM영어에서 불어로 번역하는 WMT’ 14 데이터셋에서 34.81의 BLEU score을 얻었는데, 이는 기존 모델들보다 훨씬 앞선 성능이다.
모델을 source 문장을 역순으로 학습시키고 target 문장은 정방향으로 학습시켰기 때문에 LSTM을 사용했음에도 불구하고 긴 문장에도 좋은 성능을 보였고, 이는 이 논문의 큰 기술적 기여 중 하나이다. 또한, 제안된 번역 목적함수는 LSTM이 의미를 파악하는 문장 representation을 찾게끔 유도하기 때문에 모델이 단어 순서를 학습하고 수동태, 능동태에 잘 변하지않는 장점을 가진다.
The model
Recurrent Neural Network(RNN)은 sequence를 학습하는 feedforward 신경망이다. input sequence $(x_1, \cdots, x_T)$가 주어졌을 때, RNN은 output sequence $(y_1, \cdots , y^T)$를 출력하기 위해 다음의 식을 반복적으로 거친다.
$h_t = sigm(W^{hx}x_t+ W^{hh}h_{t-1})$
$y_t=W^{yh}h_t$
RNN은 학습 이전에 sequence의 길이를 알았을 때 적용가능하지만, input, output길이가 달라지는 경우에 사용할 수없다. 기존에 두 RNN을 각각 인코딩, 디코딩에 사용하여 이 문제를 해결한 연구가 있었지만, RNN이 long term dependency로 인해 학습이 어려웠다. 따라서 저자는 LSTM을 사용하였다.
LSTM은 길이가 다른 input sequence $(x_1, \cdots, x_T)$ 와 output sequence $(y_1,\cdots, y_{T’})$에 대해 조건부 확률 $p(y_1, \cdots, y_{T’}\vert x_1,\cdots , x_T)$ 를 추정하는 것을 목표로 한다. 이 조건부 확률을 구하기 위해 input sequence가 주어졌을 때 고정된 크기의 representation $v$ 를 구하고, $v$ 를 초기 hidden state로 가지는 LSTM-LM으로 $y_1,\cdots, y_{T’}$ 의 확률을 구한다.
$p(y_1,\cdots, y_{T’}\vert x_1,\cdots,y_{T})= \prod_{t=1}^{T’}p(y_t\vert v,y_1,\cdots,y_{t-1})$
($p(y_t\vert v,y_1,\cdots,y_{t-1})$ 는 softmax로 계산한다)
하지만 기존 LSTM과는 다르게, 저자가 제안한 모델은 input sequence와 output sequence에 사용하는 LSTM을 각각 따로 두어 두 개의 LSTM을 사용하였다. 또한, 깊은 LSTM은 얕은 것보다 훨씬 좋은 성능이 나오므로, 4 layer짜리 LSTM을 사용했다. 마지막으로, input sequence를 역순으로 입력에 넣어 input의 앞부분이 output의 앞부분과 가장 가깝게 있도록 해서 SGD가 input과 ouput이 “소통”을 하게 만들 수 있게 했다. 이러한 간단한 방법들이 성능을 크게 증가시켰다.
Experiments
저자는 WMT’14 영어-불어 번역 task에 두 가지 방법을 평가했다.
- reference SMT시스템 없이 input sequence를 바로 번역
- SMT baseline의 n-best 리스트를 다시 재점수 매기기
Decoding and Rescoring
모델을 주어진 source 문장 $S$ 에 대해 target 문장 $T$ 의 로그 확률을 최대화하면서 학습한다.
목적함수 : $1/\vert mathcal{S}\vert \sum_{(T,S)\in\mathcal{S}}\log p(T\vert S)$ ($\mathcal{S}$ 는 학습데이터이다.)
학습이 끝난 후, 가장 높은 확률을 가진 번역을 선택하는 방식으로 번역문장을 만들어낸다.
$\hat{T}=\text{argmax}_T p(T\vert S)$
높은 확률의 번역을 탐색하는 것은 left-to-right beam search 디코더를 사용한다. beam size를 1로 지정해도 좋은 성능을 보이고, 2만 해도 beam search의 효과가 최대화 된다.
Reversing the source sentences
source 문장을 역순으로 하는 것만으로도 성능이 크게 오르는데, 이렇게 함으로써 데이터에 많은 short term dependencies를 주는 효과를 가진다. source 문장의 앞 단어들이 target 문장의 앞 단어들과 가까워지면서 기존 LSTM이 가지는 큰 최소시차를 줄여준다. 따라서, backpropagation시에 source와 target문장들이 잘 “소통”하도록 만들어 주며, 이는 성능 향상으로 이어진다.
또한 이 모델이 긴 문장에 대해 LSTM보다 더 좋은 성능이 났기 때문에, 이러한 학습 방식은 메모리를 보다 더 잘 활용하는 방법임을 알 수 있다.
Training details
저자들은 1000개의 cell을 가진 4 layer짜리 deep LSTM을 사용했으며, 이는 shallow LSTM보다 좋은 성능을 보였다. 1000 차원의 임베딩을 사용했고, 160000개의 input vocab와 80000개의 output vocab을 사용했다. 문장들의 길이가 서로 다르기 때문에, 미니배치 내에 있는 문장들은 모두 같은 길이가 되도록 했고, 학습시간이 2배 빨라지는 효과가 있었다. 또한 LSTM의 gradient exploding 문제를 해결하기 위해 gradient clipping을 적용했다.
Experimental Results

번역의 평가 지표는 BLEU를 사용하였다. 가장 높은 결과를 낸 모델은 여러 다른 random initialization과 minibatch 순서를 학습한 LSTM 모델들을 앙상블한 것이다. 온전이 신경망 모델만을 사용하여 큰 스케일의 번역 문제에서 SMT baseline의 성능을 뛰어넘은 것은 처음이라는 의의를 가진다. LSTM은 baseline system의 1000-best list를 재스코어하는 데 사용될 경우, 최상의 WMT’14 결과에서 0.5 BLEU 이내이다.
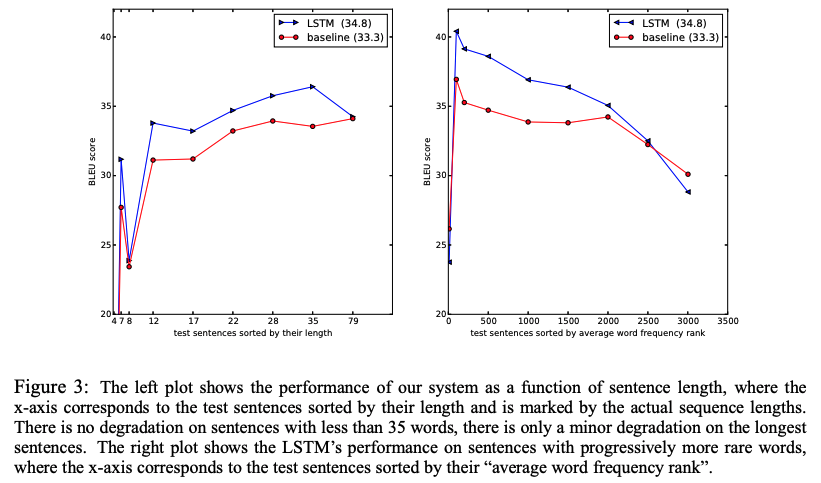
Performance on long sentences
LSTM이 긴 문장에 대해서도 잘 작동하는 것을 발견하였다. Table 3는 긴 문장과 번역된 문장의 예시를 보여준다.

Model Analysis
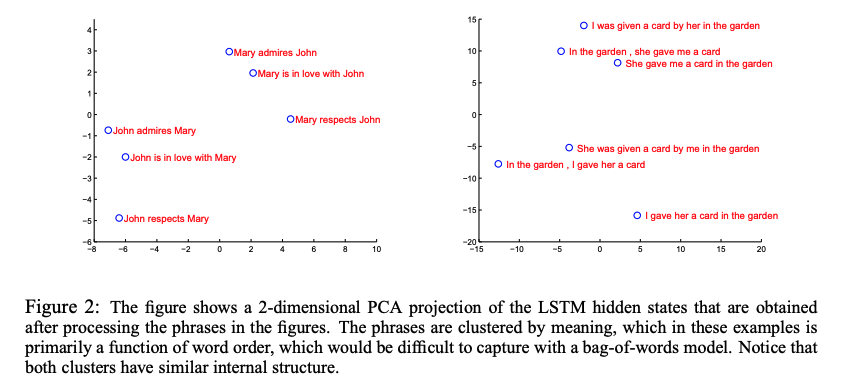
제안된 모델의 매력 중 하나는 input sequence를 고정된 차원의 representation으로 바꿔준다는 것이다. PCA를 통해 그린 다음 그림을 통해 representation이 단어의 순서에 민감하고 수동태-능동태 변화에 민감하지 않다는 것을 알 수 있다.
Conclusion
이 논문에서 저자들은 크고 깊은 LSTM이 큰 스케일의 기계번역 문제에서 SMT기반 시스템을 크게 뛰어넘을 수 있다는 것을 보였다. 또한 단순히 source문장을 역순으로 학습하는 것이 큰 성능향상을 보였고, LSTM이 긴 문장을 잘 번역함을 보였다. 이러한 발견을 통해 해당 모델이 다른 sequence to sequence문제에 잘 적용될 것이라고 유추해볼 수 있다.