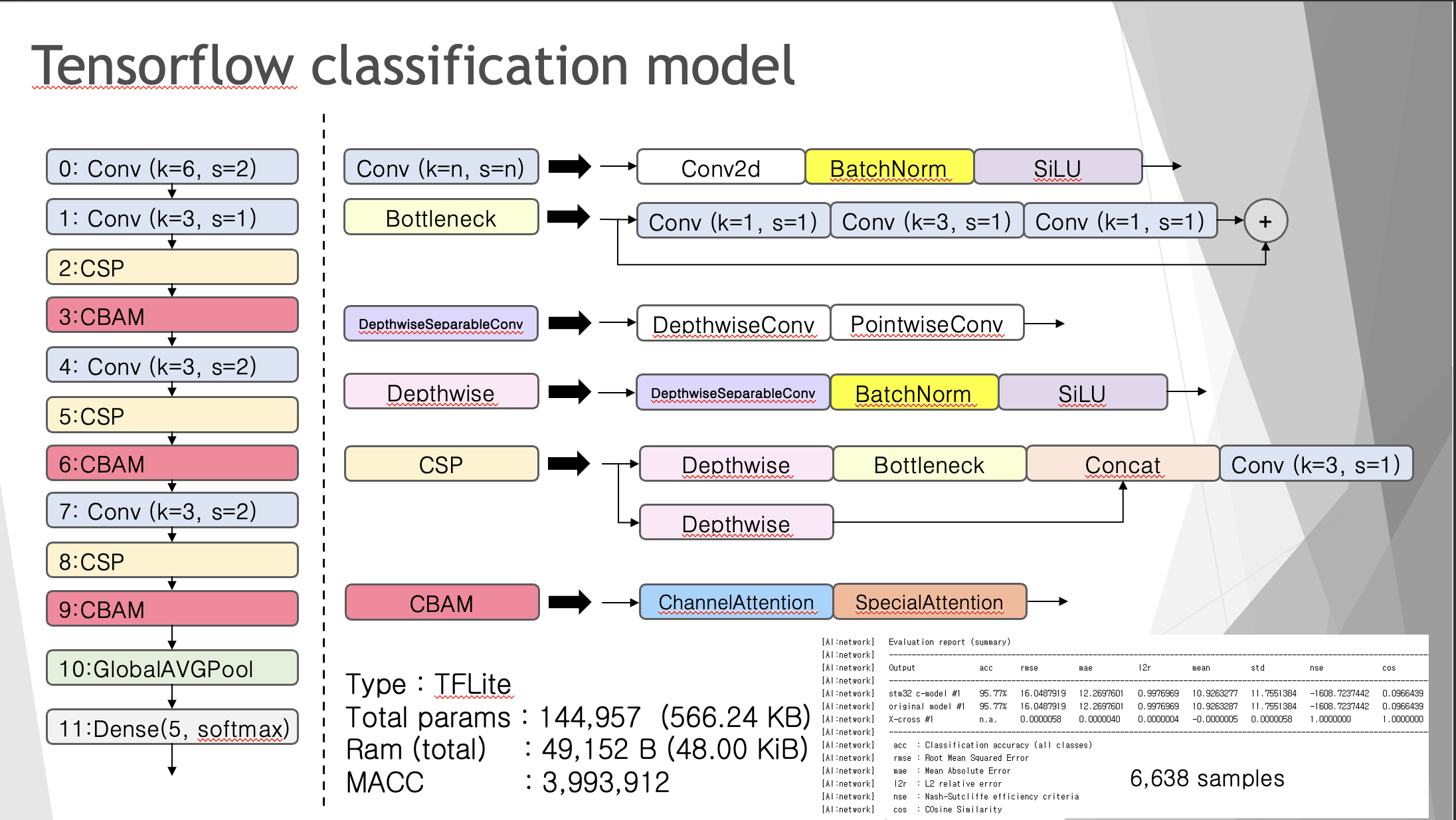
STM32에서 열화상 센서를 통한 DeepLearning Classification 구현
활성화 데이터
모델의 활성화 데이터는 모델 내부에서 연산되는 중간 결과(즉 각 계층(layer)의 출력값)들을 저장하기 위한 메모리 공간을 의미한다. 이 데이터는 모델의 다음 계층으로 전달되며, 최종 출력을 생성하는 데 필요한 정보를 포함하고 있다. 즉 모델이 복잡한 함수를 계산하고 최종적으로 예측을 수행하는 과정에서 생성되는 동적 데이터이다.
활성화 데이터의 역할
- 중간 계산 저장: 모델을 실행하는 동안 각 계층의 출력은 다음 계층의 입력으로 사용된다. 이 과정에서 각 계층의 출력값, 즉 활성화 데이터는 다음 계층의 연산을 위해 임시로 저장되어야 한다.
- 역전파를 위한 정보: 신경망을 훈련시킬 때, 역전파 알고리즘이 오류 신호를 입력층 방향으로 전달하면서 가중치를 조정한다. 이 과정에서 각 계층의 활성화 데이터는 오류를 계산하고 가중치를 업데이트하는 데 필수적인 정보를 제공한다.
활성화 데이터의 메모리 관리
- 메모리 할당: 모델의 실행을 위해서는 각 계층의 활성화 데이터를 저장할 충분한 메모리 공간이 필하다. 이 메모리는 모델의 구조와 크기에 따라 미리 정의되어야 한다.
- 효율적인 접근: 활성화 데이터는 추론 과정에서 빠르게 읽고 쓰여야 한다. 따라서, 데이터의 메모리 정렬과 접근 방식은 모델의 성능에 직접적인 영향을 미친다.
메모리 정렬
메모리 주소를 4바이트 단위로 증가. 즉, 각 주소가 4, 8, 12, 16 등으로 증가한다고 가정. AI_ALIGNED(4) 지시어는 데이터가 이러한 주소 중 하나에서 시작되도록 한다. 예를 들어, 어떤 변수가 메모리 주소 4에서 시작한다면, 그 변수는 4바이트 경계에 정렬된 것.
정렬되지 않은 경우
1
2
주소: 0x01 0x02 0x03 0x04 0x05 0x06 0x07 0x08
데이터: [A] [A] [A] [B] [B] [B] [B] [C]
[A]는 주소 0x01에서 시작하는 3바이트 데이터. 이 데이터는 4바이트 경계에 맞춰져 있지 않다.[B]는 주소 0x04에서 시작하는 4바이트 데이터. 이 데이터는 4바이트 경계에 정렬된다.[C]는 0x08 주소에 있는 단일 바이트 데이터.
4바이트 경계에 정렬된 경우
1
2
주소: 0x04 0x08 0x0C 0x10 0x14 0x18 0x1C 0x20
데이터: [D] [D] [D] [D] | [E] [E] [E] [E]
[D]는 주소 0x04에서 시작하는 4바이트 데이터. 이 데이터는 4바이트 경계에 정확히 맞춰져 있다.[E]는 주소 0x14에서 시작하는 다른 4바이트 데이터. 이 데이터 역시 4바이트 경계에 정확히 맞춰져 있다.
부족한 부분에 대한 패딩 (Padding)
1
2
메모리 주소: 0x04 0x05 0x06 0x07 0x08
데이터: [A] [A] [A] [ ] ...
- 데이터가 정렬을 위해 요구되는 크기에 도달하지 못하는 경우, 나머지 공간은 패딩으로 채워진다. 예를 들어, 3바이트 데이터를 4바이트 경계에 맞추어 저장하려고 할 때, 1바이트의 패딩이 추가된다. 이 패딩은 해당 데이터의 일부로 처리되지 않으며 단순히 메모리를 채우는 역할만 한다.
넘치는 부분에 대한 처리
- 데이터가 특정 경계를 넘어설 경우, 즉 데이터 크기가 정렬 크기의 배수가 아닐 경우, 데이터는 여전히 시작점에서 정렬 경계에 맞춰 저장된다. 예를 들어, 5바이트 데이터를 4바이트 경계에 맞춰 저장하려고 할 때, 처음 4바이트는 첫 번째 4바이트 경계에 저장되고, 나머지 1바이트는 다음 4바이트 경계에 저장된다. 이 경우, 다음 데이터는 이 1바이트 뒤의 다음 4바이트 경계에서 시작된다. 여기서는 “넘치는” 부분에 대해 특별히 처리할 필요가 없으며, 데이터는 자연스럽게 연속적으로 메모리에 배치된다.
1
[4바이트 데이터] [3바이트 데이터 + 1바이트 패딩] [5바이트 데이터 + 3바이트 패딩] ...
- 4바이트 데이터는 그대로 4바이트 경계에 맞춰 저장
- 3바이트 데이터는 1바이트의 패딩이 추가되어 다음 4바이트 경계에 맞춰 저장
- 5바이트 데이터는 첫 4바이트가 첫 번째 4바이트 경계에 저장되고, 나머지 1바이트는 다음 4바이트 경계의 시작에 저장. 이후 데이터는 이 5바이트 데이터 뒤의 3바이트 패딩을 고려하여 다음 4바이트 경계에서 시작.
왜 메모리 정렬이 중요한가?
메모리 정렬은 프로세서가 메모리에 접근하는 효율성을 개선한다. 많은 프로세서는 특정 바이트 경계에 정렬된 데이터를 더 빠르게 읽고 쓸 수 있으며, 때로는 정렬되지 않은 데이터에 접근하려고 할 때 추가적인 성능 비용이 발생할 수 있다. 따라서, 데이터를 적절히 정렬하는 것은 시스템의 전반적인 성능을 향상시키는 중요한 방법 중 하나이다.
4바이트 경계에 정렬한다는 것은 메모리 주소가 4의 배수인 위치에서 데이터가 시작되도록 하는 것을 의미한다. 즉, 데이터의 시작 주소를 4, 8, 12, 16 등과 같이 4의 배수로 설정하는 것이다. 이런 방식으로 정렬하면, 데이터의 시작 주소는 항상 4로 나누어 떨어지게 된다.
이러한 정렬은 컴퓨터의 하드웨어와 메모리 아키텍처가 데이터를 더 효율적으로 처리할 수 있게 해주어, 메모리 액세스 시간을 단축시키고 전반적인 성능을 개선할 수 있다. 예를 들어, 많은 CPU 아키텍처에서는 4바이트(또는 해당 CPU에 최적화된 다른 바이트 크기) 경계에 정렬된 데이터를 한 번에 읽어들일 수 있어, 데이터 처리 속도가 빨라진다.
이는 특히 큰 데이터 구조체나 배열을 메모리에 할당할 때 중요한데, 이렇게 하면 CPU가 각 데이터 요소를 더 빨리 액세스하고, 결과적으로 프로그램의 전체 실행 시간을 단축할 수 있다.
MACC (Multiply-Accumulate 연산)
모델이 수행해야 하는 총 MAC 연산의 수. 이는 모델의 계산 복잡도를 나타내는 지표 중 하나
Multiply-Accumulate (MAC) 연산은 딥 러닝과 같은 컴퓨터 연산에서 매우 일반적으로 사용되는 기본 연산이다. 하나의 MAC 연산은 곱셈 한 번과 덧셈 한 번을 수행한다. 예를 들어, 신경망에서 한 뉴런의 출력을 계산할 때, 입력 피처(feature)들과 해당 가중치(weights)들의 곱의 합을 구하는 것은 MAC 연산을 여러 번 수행하는 것과 같다.
C_MACC
c_macc는 해당 계층까지의 누적 Multiply-Accumulate 연산의 비율을 나타낸다. 이는 모델의 전체 연산량에서 각 계층이 차지하는 비율을 퍼센테이지(%)로 표현한 것이다.
c_macc 값은 해당 계층까지 모델이 수행해야 하는 전체 MAC 연산의 양을 퍼센트로 나타낸 것으로, 모델의 성능 및 복잡성을 평가하는 데 사용될 수 있다. 높은 c_macc 값은 그 계층이 모델 내에서 상대적으로 더 많은 연산을 수행함을 의미한다. 이는 해당 계층이 모델의 계산 비용에 큰 영향을 미친다는 것을 나타내며, 최적화의 대상이 될 수 있다.
Model
main.c
include
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include "main.h"
#include "crc.h"
#include "i2c.h"
#include "usart.h"
#include "gpio.h"
#include <stdint.h>
#include <stdlib.h>
#include <stdio.h>
#include <inttypes.h>
#include <string.h>
#include <float.h>
#include <math.h>
#include "ai_datatypes_defines.h"
#include "model.h"
#include "model_data.h"
#include "dataset.h"
#include "MLX90640_API.h"
#define HEIGHT 24
#define WIDTH 32
입력 및 출력을 위한 메모리 할당
1
2
3
4
5
6
7
8
9
// 입력 데이터가 활성화 배열에 저장되는지 여부에 따라 모델 입력 데이터 배열을 조건부로 정의
// 입력 데이터 배열을 4바이트 경계에 맞춰 효율적인 액세스를 위해 정렬
#if !defined(AI_MODEL_INPUTS_IN_ACTIVATIONS)
AI_ALIGNED(4) ai_i8 data_in_1[AI_MODEL_IN_1_SIZE_BYTES];
ai_i8* data_ins[AI_MODEL_IN_NUM] = {data_in_1};
#else
ai_i8* data_ins[AI_MODEL_IN_NUM] = {NULL};
#endif
- 조건부 컴파일 (
#if !defined(AI_MODEL_INPUTS_IN_ACTIVATIONS)): 이 지시어는AI_MODEL_INPUTS_IN_ACTIVATIONS가 정의되어 있지 않은 경우에만 컴파일러가 해당 코드 블록을 컴파일하도록 한다. 즉, 입력 데이터가 모델의 활성화 배열에 저장되지 않을 때만 입력 데이터를 별도로 할당하도록 하는 것.
- 메모리 정렬 (
AI_ALIGNED(4)):data_in_1배열을 4바이트 경계에 정렬하라는 지시. 이는 데이터 접근 속도를 최적화하기 위한 것으로, 많은 하드웨어 아키텍처에서 정렬된 메모리 접근이 더 빠르기 때문이다.
- 입력 데이터 배열 (
ai_i8 data_in_1[AI_MODEL_IN_1_SIZE_BYTES]): 이 배열은 모델의 첫 번째 입력 데이터를 저장하기 위한 공간.AI_MODEL_IN_1_SIZE_BYTES는 필요한 바이트 수를 정의.
- 입력 데이터 포인터 배열 (
ai_i8* data_ins[AI_MODEL_IN_NUM]):data_ins는 입력 데이터 배열의 포인터를 저장하는 배열. 이 배열을 통해 모델의 다양한 입력에 접근할 수 있다. 배열의 첫 번째 요소는data_in_1배열을 가리킨다.
1
2
3
4
5
6
7
8
9
10
// 출력 데이터가 활성화 배열에 저장되는지 여부에 따라 모델 출력 데이터 배열을 조건부로 정의
// 출력 데이터 배열을 4바이트 경계에 맞춰 효율적인 액세스를 위해 정렬합니다.
#if !defined(AI_MODEL_OUTPUTS_IN_ACTIVATIONS)
AI_ALIGNED(4) ai_i8 data_out_1[AI_MODEL_OUT_1_SIZE_BYTES];
ai_i8* data_outs[AI_MODEL_OUT_NUM] = {data_out_1};
#else
ai_i8* data_outs[AI_MODEL_OUT_NUM] = {NULL};
#endif
- 조건부 컴파일 (
#if !defined(AI_MODEL_OUTPUTS_IN_ACTIVATIONS)): 출력 데이터가 활성화 배열에 저장되지 않을 때만 출력 데이터를 별도로 할당하도록 한다.
- 메모리 정렬 (
AI_ALIGNED(4)):data_out_1배열을 4바이트 경계에 정렬
- 출력 데이터 배열 (
ai_i8 data_out_1[AI_MODEL_OUT_1_SIZE_BYTES]): 이 배열은 모델의 첫 번째 출력 데이터를 저장.AI_MODEL_OUT_1_SIZE_BYTES는 필요한 바이트 수를 정의.
- 출력 데이터 포인터 배열 (
ai_i8* data_outs[AI_MODEL_OUT_NUM]):data_outs는 출력 데이터 배열의 포인터를 저장하는 배열. 이 배열을 통해 모델의 다양한 출력에 접근할 수 있다. 배열의 첫 번째 요소는data_out_1배열을 가리킨다.
활성화를 위한 메모리 할당
1
2
3
4
5
6
// 모델 활성화를 위한 풀을 32바이트 경계에 맞춰 정렬
// 이 풀은 신경망의 중간 계산 및 활성화를 저장하는 데 사용
AI_ALIGNED(32) static uint8_t pool0[AI_MODEL_DATA_ACTIVATION_1_SIZE];
// 활성화 풀을 가리키는 핸들 배열을 정의
ai_handle data_activations0[] = {pool0};
AI_ALIGNED(32): 특정 CPU 아키텍처에 매우 중요한 효율적인 액세스를 위해 활성화 배열을 32바이트 경계에 정렬.
uint8_t: 부호 없는 8비트 정수 타입으로, 양자화된 활성화 값 저장에 적합
AI_MODEL_DATA_ACTIVATION_1_SIZE: 활성화에 필요한 메모리의 크기를 바이트 단위로 나타낸다.
모델 및 버퍼 초기화
1
2
3
4
5
6
// null 값으로 초기화된 모델 핸들을 선언.
static ai_handle model = AI_HANDLE_NULL;
// 입력 및 출력을 위한 ai_buffer 구조체 포인터 선언.
static ai_buffer* ai_input;
static ai_buffer* ai_output;
AI_HANDLE_NULL: 일반적으로 null 또는 유효하지 않은 핸들 값을 정의하는 매크로. 여기서는 model 핸들을 초기화하는 데 사용.
ai_buffer: 데이터 포인터, 크기, 가능하면 데이터 타입을 포함하는 정보를 캡슐화하는 구조체. 이 구조체는 AI 모델이 입력 데이터의 출처와 출력을 쓸 위치를 알 수 있도록 인터페이스 역할을 한다.
오류 로깅
1
2
3
4
5
6
7
8
9
10
11
12
static void ai_log_err(const ai_error err, const char *fct)
{
// 함수 이름이 제공되었는지 확인
if (fct)
// 함수 이름과 함께 오류 정보 출력
printf("TEMPLATE - Error (%s) - type=0x%02x code=0x%02x\r\n", fct, err.type, err.code);
else
// 오류 타입과 코드만 출력
printf("TEMPLATE - Error - type=0x%02x code=0x%02x\r\n", err.type, err.code);
do {} while (1);
}
err파라미터는 오류 타입과 코드를 포함하는ai_error구조체fct파라미터는 오류가 발생한 함수의 이름. 파라미터가NULL이 아니면, 함수 이름도 함께 출력
AI모델 초기화
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
static int ai_boostrap(ai_handle *act_addr)
{
ai_error err;
// 모델 인스턴스 생성 및 초기화 시도
err = ai_model_create_and_init(&model, act_addr, NULL);
if (err.type != AI_ERROR_NONE) {
// 오류 발생 시 오류 로깅 함수 호출
ai_log_err(err, "ai_model_create_and_init");
return -1; // 오류 코드 반환
}
// 모델 입력 버퍼 참조 얻기
ai_input = ai_model_inputs_get(model, NULL);
// 모델 출력 버퍼 참조 얻기
ai_output = ai_model_outputs_get(model, NULL);
// 이후 코드는 입력 및 출력 버퍼 할당 로직
}
ai_boostrap함수는 AI 모델을 생성하고 초기화하는 과정을 담당ai_model_create_and_init함수를 호출하여 모델 인스턴스를 생성하고 초기화. 오류가 발생하면 해당 오류를ai_log_err함수를 통해 로깅하고 함수에서 -1을 반환.ai_model_inputs_get과ai_model_outputs_get함수를 호출하여, 모델의 입력과 출력에 대한 참조를 각각ai_input과ai_output에 저장. 이는 모델과 데이터를 연결하는 단계
입력 및 출력 버퍼 할당 로직
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#if defined(AI_MODEL_INPUTS_IN_ACTIVATIONS)
// 입력 버퍼를 활성화 버퍼에서 할당하는 경우
for (int idx=0; idx < AI_MODEL_IN_NUM; idx++) {
data_ins[idx] = ai_input[idx].data;
}
#else
// 별도의 입력 버퍼를 사용하는 경우
for (int idx=0; idx < AI_MODEL_IN_NUM; idx++) {
ai_input[idx].data = data_ins[idx];
}
#endif
#if defined(AI_MODEL_OUTPUTS_IN_ACTIVATIONS)
// 출력 버퍼를 활성화 버퍼에서 할당하는 경우
for (int idx=0; idx < AI_MODEL_OUT_NUM; idx++) {
data_outs[idx] = ai_output[idx].data;
}
#else
// 별도의 출력 버퍼를 사용하는 경우
for (int idx=0; idx < AI_MODEL_OUT_NUM; idx++) {
ai_output[idx].data = data_outs[idx];
}
#endif
- 이 부분은 모델의 입력 및 출력 데이터 버퍼를 활성화 버퍼 내에 할당할지, 아니면 별도로 할당할지 결정하는 로직을 포함.
- 매크로
AI_MODEL_INPUTS_IN_ACTIVATIONS와AI_MODEL_OUTPUTS_IN_ACTIVATIONS의 정의 여부에 따라 조건부 컴파일을 사용. - 입력 및 출력 버퍼는 모델의 동작에 필요한 데이터를 저장하기 위한 공간
모델 초기화 진입
1
2
3
4
5
6
7
8
void MX_X_CUBE_AI_Init(void)
{
// 초기화 시작 로깅
printf("\r\nTEMPLATE - initialization\r\n");
// AI 모델 부트스트랩 함수 호출
ai_boostrap(data_activations0);
}
MX_X_CUBE_AI_Init함수는 전체 AI 모델 초기화 과정의 진입.- 초기화 과정이 시작됨을 알리는 로그 메시지를 출력한 후,
ai_boostrap함수를 호출하여 모델을 초기화. 이 과정에서 모델의 인스턴스 생성, 입력 및 출력 버퍼의 할당 등 필요한 모든 설정이 수행.
argmax
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int argmax(float* array, int size) {
// 가장 큰 요소의 인덱스를 저장하기 위한 변수 초기화
int max_index = 0;
// 배열의 두 번째 요소부터 마지막 요소까지 순회
for (int i = 1; i < size; i++) {
// 현재 요소가 이전까지의 최대 값보다 크면
if (array[i] > array[max_index]) {
// 최대값의 인덱스를 현재 인덱스로 업데이트
max_index = i;
}
}
// 최대값의 인덱스 반환
return max_index;
}
argmax함수는 주어진 실수 배열에서 최대 값을 갖는 요소의 인덱스를 찾아 반환.- 배열의 첫 번째 요소(
index 0)를 가장 큰 값으로 가정하고 시작. - 배열의 나머지 요소들을 순회하면서, 현재 요소가 이전의 최대값보다 크다면, 그 요소의 인덱스를 최대값의 인덱스로 갱신.
- 모든 요소를 검사한 후, 최대값의 인덱스를 반환.
transform_to_4d
1
2
3
4
5
6
7
8
9
10
void transform_to_4d(const float input[][WIDTH], float transformed_input[1][HEIGHT][WIDTH][1]) {
// 입력 이미지의 높이만큼 반복
for (int h = 0; h < HEIGHT; h++) {
// 입력 이미지의 너비만큼 반복
for (int w = 0; w < WIDTH; w++) {
// 각 픽셀 값을 255.0으로 나누어 0에서 1 사이의 값으로 정규화
transformed_input[0][h][w][0] = input[h][w] / 255.0f;
}
}
}
transform_to_4d함수는 2차원 이미지 데이터를 4차원 텐서로 변환하며, 동시에 0에서 255 사이의 픽셀 값을 0에서 1 사이로 정규화- 이 함수는 딥러닝 모델의 입력으로 사용하기 위한 이미지 데이터의 전처리 과정
- 입력 이미지는
HEIGHT와WIDTH차원을 가지는 2차원 배열로 주어지며 이를 4차원 배열[1][HEIGHT][WIDTH][1]로 변환하여 모델의 입력 형식에 맞춘다. 첫 번째와 마지막 차원은 각각 배치 크기와 채널 수를 나타내며, 여기서는 둘 다 1로 설정 - 이미지의 모든 픽셀 값은 255.0으로 나누어 정규화.
main
CPU 캐시 활성화: 이 부분에서는 CPU의 명령어 캐시(I-Cache)와 데이터 캐시(D-Cache)를 활성화. 이를 통해 프로그램의 실행 속도를 향상
MCU 구성: 여기에서는 하드웨어 추상화 레이어(HAL) 라이브러리의
HAL_Init함수를 호출하여 모든 주변장치를 리셋하고, 플래시 인터페이스 및 SysTick 타이머를 초기화시스템 클럭 구성:
SystemClock_Config함수를 호출하여 시스템 클럭을 구성.주변장치 초기화:
MX_GPIO_Init,MX_USART3_UART_Init,MX_CRC_Init,MX_I2C1_Init함수들을 호출하여 GPIO, UART, CRC, I2C 주변장치를 초기화AI 모델 초기화 및 실행: 사용자 정의 코드 섹션에서는 AI 모델을 초기화(
MX_X_CUBE_AI_Init)하고, 입력 데이터를 변환하여 모델에 공급한 다음, 모델을 실행(ai_model_run). 실행 후에는 출력 데이터를 분석하여 가장 높은 확률을 가진 인덱스(클래스)를 찾고 이를 출력.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
int main(void)
{
/* CPU 캐시 활성화 */
/* I-Cache(명령어 캐시) 활성화 */
SCB_EnableICache();
/* D-Cache(데이터 캐시) 활성화 */
SCB_EnableDCache();
/* MCU 구성 */
/* 모든 주변장치 리셋, 플래시 인터페이스 및 SysTick 초기화 */
HAL_Init();
/* 시스템 클럭 구성 */
SystemClock_Config();
/* 구성된 모든 주변장치 초기화 */
MX_GPIO_Init();
MX_USART3_UART_Init();
MX_CRC_Init();
MX_I2C1_Init();
/* AI 모델 초기화 */
MX_X_CUBE_AI_Init();
while (1)
{
/* 이미지 데이터를 4차원 텐서로 변환 */
float transformed_input[1][HEIGHT][WIDTH][1];
transform_to_4d(zero, transformed_input);
/* 변환된 데이터를 모델 입력 버퍼로 복사 */
memcpy(data_ins[0], transformed_input, sizeof(float) * 1 * 24 * 32 * 1);
/* AI 모델 실행. 실패 시 오류 로깅 및 종료 */
if (ai_model_run(model, ai_input, ai_output) != 1) {
ai_log_err(ai_model_get_error(model), "ai_model_run");
return -1;
}
/* 출력 데이터에서 최대 인덱스(예측된 클래스) 찾기 */
const int output_size = 5;
float* output_value = (float*)data_outs[0];
int max_index = argmax(output_value, output_size);
printf("Max index: %d\n", max_index);
}
}
1
memcpy(data_ins[0], transformed_input, sizeof(float) * 1 * 24 * 32 * 1);
data_ins[0]는 목적지 메모리 영역의 시작 주소. 여기서는 AI 모델의 첫 번째 입력 데이터를 저장할 메모리 위치를 가리킨다.transformed_input은 원본 메모리 영역의 시작 주소. 여기서는 변환된 입력 데이터가 저장된 메모리 위치를 가리킨다.sizeof(float) * 1 * 24 * 32 * 1은 복사할 데이터의 크기. 이 경우, 4차원 입력 텐서의 전체 요소 수에 해당하는 바이트 수를 계산한 것
따라서, 이 memcpy 호출은 transformed_input 메모리 영역에서 data_ins[0] 메모리 영역으로 지정된 크기만큼의 데이터를 복사. 결과적으로, data_ins[0]가 가리키는 메모리 영역에는 transformed_input의 데이터가 저장.
1
2
3
for (int idx=0; idx < AI_MODEL_IN_NUM; idx++) {
data_ins[idx] = ai_input[idx].data;
}
이 부분은 실제로는 ai_input[idx].data 포인터들을 data_ins 배열에 할당하는 것이 아니라, 모델 입력 데이터의 메모리 위치를 data_ins에 저장하는 것. 즉, data_ins[idx]는 입력 데이터의 실제 위치를 가리키게 된다.
그러나, 여기서의 핵심은 memcpy(data_ins[0], transformed_input, sizeof(float) * 1 * 24 * 32 * 1); 라인 이후의 행동과 관련이 있다. 이 memcpy 호출은 transformed_input에서 data_ins[0]로 데이터를 복사. 여기서 data_ins[0]는 사실 ai_input[0].data를 가리키는 것이기 때문에, 실제로 이뤄지는 것은 ai_input[0].data가 가리키는 메모리 위치로 transformed_input의 내용을 복사하는 것.
따라서, ai_model_run을 호출할 때, ai_input 구조체가 가리키는 데이터(즉, ai_input[idx].data가 가리키는 데이터)는 이미 memcpy를 통해 업데이트된 상태. ai_model_run(model, ai_input, ai_output) 호출 시, ai_input은 이미 최신화된 입력 데이터를 가리키고 있게된다.
memcpy에 의해 data_ins[0]로 복사된 데이터는 이미 ai_input[0].data를 통해 ai_model_run에 전달되기 때문에 추가적인 할당 과정이 필요하지 않다. 이 과정은 ai_input의 data 포인터가 이미 올바른 메모리 위치를 가리키고 있기 때문에 가능.
1
2
3
4
5
6
/* 출력 데이터에서 최대 인덱스(예측된 클래스) 찾기 */
const int output_size = 5;
float* output_value = (float*)data_outs[0];
int max_index = argmax(output_value, output_size);
printf("Max index: %d\n", max_index);
float* output_value = (float*)data_outs[0]; 이 코드는 data_outs[0]가 가리키는 메모리 주소를 float* 타입으로 캐스팅하고 그 포인터를 output_value에 할당. data_outs[0]가 가리키는 데이터는 (1, 1, 1, 5) 형태의 4차원 텐서, 이 때 포인터(output_value)를 사용하여 4차원 텐서의 데이터에 순차적으로 접근
model_data_params.h
AI 모델의 데이터 구성, 활성화 데이터 및 가중치 데이터에 대한 메타데이터를 정의하는 부분.
데이터 구성
1
#define AI_MODEL_DATA_CONFIG (NULL)
- 매크로는 AI 모델의 추가 데이터 구성을 위한 설정을 정의. 여기서는 특별한 구성이 없음을 나타내기 위해
NULL로 설정.
활성화 데이터 사이즈 정의
1
#define AI_MODEL_DATA_ACTIVATIONS_SIZES { 24576, }
- 모델의 활성화 데이터 크기를 배열로 정의. 여기서는 하나의 활성화 데이터 크기가 24576바이트임을 나타낸다.
1
#define AI_MODEL_DATA_ACTIVATIONS_SIZE (24576)
- 전체 활성화 데이터의 총 크기를 정의. 여기서는
AI_MODEL_DATA_ACTIVATIONS_SIZES배열의 총합과 동일.
1
#define AI_MODEL_DATA_ACTIVATIONS_COUNT (1)
- 활성화 데이터 배열의 요소 수를 정의. 여기서는 하나의 활성화 데이터만 있음을 나타낸다.
1
#define AI_MODEL_DATA_ACTIVATION_1_SIZE (24576)
- 첫 번째 활성화 데이터의 크기를 명시적으로 정의.
가중치 데이터 사이즈 정의
1
#define AI_MODEL_DATA_WEIGHTS_SIZES { 752108, }
- 모델의 가중치 데이터 크기를 배열로 정의. 여기서는 하나의 가중치 데이터 크기가 752108바이트임을 나타낸다.
1
#define AI_MODEL_DATA_WEIGHTS_SIZE (752108)
- 전체 가중치 데이터의 총 크기를 정의. 여기서는
AI_MODEL_DATA_WEIGHTS_SIZES배열의 총합과 동일.
1
#define AI_MODEL_DATA_WEIGHTS_COUNT (1)
- 가중치 데이터 배열의 요소 수를 정의 여기서는 하나의 가중치 데이터만 있음을 나타낸다.
1
#define AI_MODEL_DATA_WEIGHT_1_SIZE (752108)
- 첫 번째 가중치 데이터의 크기를 명시적으로 정의.
활성화 및 가중치 데이터 테이블 접근
1
2
#define AI_MODEL_DATA_ACTIVATIONS_TABLE_GET() \
(&g_model_activations_table[1])
- 활성화 데이터 테이블에 대한 접근을 제공하는 매크로 함수.
g_model_activations_table배열의 두 번째 요소의 주소를 반환.
1
extern ai_handle g_model_activations_table[1 + 2];
- 활성화 데이터를 저장하기 위한 전역 배열을 선언. 배열 크기는 3. (
1 + 2는 배열에 대한 여분의 공간을 예약하기 위해 사용)
1
2
#define AI_MODEL_DATA_WEIGHTS_TABLE_GET() \
(&g_model_weights_table[1])
- 가중치 데이터 테이블에 대한 접근을 제공하는 매크로 함수.
g_model_weights_table배열의 두 번째 요소의 주소를 반환.
1
extern ai_handle g_model_weights_table[1 + 2];
- 가중치 데이터를 저장하기 위한 전역 배열을 선언. 배열 크기는 3. (
1 + 2는 여기서도 배열에 대한 여분의 공간을 예약하기 위해 사용.)
model_data_params.c
AI 모델의 활성화 데이터와 가중치 데이터를 메모리에 저장하고, 이 데이터에 접근하기 위한 테이블을 설정
활성화 데이터 섹션
1
2
3
4
5
ai_handle g_model_activations_table[1 + 2] = {
AI_HANDLE_PTR(AI_MAGIC_MARKER),
AI_HANDLE_PTR(NULL),
AI_HANDLE_PTR(AI_MAGIC_MARKER),
};
- 전역 변수
g_model_activations_table은 모델의 활성화 데이터에 대한 핸들(주소)을 저장하는 배열. - 배열의 크기는 3으로 설정되어 있으며, 이는 활성화 데이터를 위한 핸들, 실제 활성화 데이터 주소, 그리고 마커를 포함하기 위한 공간.
AI_HANDLE_PTR(AI_MAGIC_MARKER)는 배열의 시작과 끝에 사용되며, 배열의 유효성을 체크하기 위한 마커로 사용.- 중간에
AI_HANDLE_PTR(NULL)은 실제 활성화 데이터를 가리킬 위치로, 이후에 적절한 메모리 주소로 업데이트될 수 있다.
가중치 데이터 섹션
1
2
3
4
5
AI_ALIGNED(32)
const ai_u64 s_model_weights_array_u64[94014] = {
0x3e94dd763ebad3b4U, 0x3f32bf593f127439U, 0x3ee7ad873f1b5183U, 0x3eec2fab3ea82dd9U,
...
};
s_model_weights_array_u64은 모델의 가중치 데이터를 저장하는 배열. 이 배열은ai_u64타입으로, 64비트 부동 소수점 값들을 포함AI_ALIGNED(32)지시어는 이 배열이 32바이트 경계에 정렬되도록 한다. 이는 메모리 접근의 최적화를 위한 것으로, 특정 아키텍처에서 더 효율적인 데이터 액세스를 가능하게 한다.- 배열의 크기는 94014로, 이는 모델의 가중치 데이터 전체를 저장하기 위한 크기. 실제 데이터 값들은
0x3e94dd76...과 같은 형식으로 표시되어 있다.
1
2
3
4
5
ai_handle g_model_weights_table[1 + 2] = {
AI_HANDLE_PTR(AI_MAGIC_MARKER),
AI_HANDLE_PTR(s_model_weights_array_u64),
AI_HANDLE_PTR(AI_MAGIC_MARKER),
};
g_model_weights_table은 가중치 데이터에 대한 핸들을 저장하는 전역 배열.- 마찬가지로 배열의 크기는 3으로 설정되어 있으며, 시작과 끝에는
AI_MAGIC_MARKER를 사용하여 배열의 유효성을 체크. - 배열의 중간에
AI_HANDLE_PTR(s_model_weights_array_u64)를 통해s_model_weights_array_u64배열의 주소를 저장. 이를 통해 모델은 가중치 데이터에 접근할 수 있게 된다.
model.c
AI 모델의 생성, 초기화, 실행, 그리고 파괴와 관련된 함수들을 정의하는 구현부
모델 오류 가져오기
1
2
3
4
5
AI_API_ENTRY
ai_error ai_model_get_error(ai_handle network)
{
return ai_platform_network_get_error(network);
}
ai_model_get_error함수는 주어진 네트워크 핸들에 대한 마지막 오류를 반환. 이는ai_platform_network_get_error함수를 호출하여 얻는다.
모델 생성
1
2
3
4
5
6
7
AI_API_ENTRY
ai_error ai_model_create(ai_handle* network, const ai_buffer* network_config)
{
return ai_platform_network_create(
network, network_config, &AI_NET_OBJ_INSTANCE,
AI_TOOLS_API_VERSION_MAJOR, AI_TOOLS_API_VERSION_MINOR, AI_TOOLS_API_VERSION_MICRO);
}
ai_model_create함수는 주어진 네트워크 구성에 따라 AI 모델을 생성. 내부적으로ai_platform_network_create함수를 사용하여 네트워크 인스턴스를 생성하고 초기화.
모델 생성 및 초기화
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
AI_API_ENTRY
ai_error ai_model_create_and_init(
ai_handle* network, const ai_handle activations[], const ai_handle weights[])
{
ai_error err;
ai_network_params params;
err = ai_model_create(network, AI_MODEL_DATA_CONFIG);
if (err.type != AI_ERROR_NONE)
return err;
if (ai_model_data_params_get(¶ms) != true) {
err = ai_model_get_error(*network);
return err;
}
#if defined(AI_MODEL_DATA_ACTIVATIONS_COUNT)
if (activations) {
for (int idx=0;idx<params.map_activations.size;idx++)
AI_BUFFER_ARRAY_ITEM_SET_ADDRESS(¶ms.map_activations, idx, activations[idx]);
}
#endif
#if defined(AI_MODEL_DATA_WEIGHTS_COUNT)
if (weights) {
for (int idx=0;idx<params.map_weights.size;idx++)
AI_BUFFER_ARRAY_ITEM_SET_ADDRESS(¶ms.map_weights, idx, weights[idx]);
}
#endif
if (ai_model_init(*network, ¶ms) != true) {
err = ai_model_get_error(*network);
}
return err;
}
- 이 함수는 AI 모델을 생성하고, 활성화 및 가중치 데이터를 사용하여 모델을 초기화. 먼저,
ai_model_create를 호출하여 모델을 생성한 후,ai_model_data_params_get함수를 사용하여 네트워크 파라미터를 가져온다. 이 파라미터에는 활성화 데이터와 가중치 데이터의 메모리 주소가 설정.
입력 및 출력 버퍼 가져오기
1
2
3
4
5
6
7
8
9
AI_API_ENTRY
ai_buffer* ai_model_inputs_get(ai_handle network, ai_u16 *n_buffer)
{
if (network == AI_HANDLE_NULL) {
network = (ai_handle)&AI_NET_OBJ_INSTANCE;
((ai_network *)network)->magic = AI_MAGIC_CONTEXT_TOKEN;
}
return ai_platform_inputs_get(network, n_buffer);
}
- 네트워크의 입력 버퍼를 가져오는 함수. 네트워크 핸들이
AI_HANDLE_NULL일 경우, 기본 네트워크 객체의 주소를 사용.
1
2
3
4
5
6
7
8
9
AI_API_ENTRY
ai_buffer* ai_model_outputs_get(ai_handle network, ai_u16 *n_buffer)
{
if (network == AI_HANDLE_NULL) {
network = (ai_handle)&AI_NET_OBJ_INSTANCE;
((ai_network *)network)->magic = AI_MAGIC_CONTEXT_TOKEN;
}
return ai_platform_outputs_get(network, n_buffer);
}
- 네트워크의 출력 버퍼를 가져오는 함수. 입력 버퍼를 가져오는 과정과 유사.
모델 파괴
1
2
3
4
ai_handle ai_model_destroy(ai_handle network)
{
return ai_platform_network_destroy(network);
}
ai_model_destroy함수는 주어진 네트워크 핸들을 사용하여 AI 모델을 파괴.
모델 초기화
1
2
3
4
5
6
7
8
9
10
11
12
13
AI_API_ENTRY
ai_bool ai_model_init(ai_handle network, const ai_network_params* params)
{
ai_network* net_ctx = ai_platform_network_init(network, params);
if (!net_ctx) return false;
ai_bool ok = true;
ok &= model_configure_weights(net_ctx, params);
ok &= model_configure_activations(net_ctx, params);
ok &= ai_platform_network_post_init(network);
return ok;
}
- 모델을 주어진 파라미터로 초기화. 이 과정에는 가중치와 활성화 데이터의 설정, 그리고 네트워크의 후처리 초기화가 포함.
모델 실행
1
2
3
4
5
AI_API_ENTRY
ai_i32 ai_model_run(ai_handle network, const ai_buffer* input, ai_buffer* output)
{
return ai_platform_network_process(network, input, output);
}
- 주어진 입력에 대해 AI 모델을 실행하고, 결과를 출력 버퍼에 저장. 이 함수는 내부적으로
ai_platform_network_process함수를 호출.
1
2
3
4
5
AI_API_ENTRY
ai_i32 ai_model_forward(ai_handle network, const ai_buffer* input)
{
return ai_platform_network_process(network, input, NULL);
}
- 이 함수는 모델을 “forward” 실행. 즉, 출력 버퍼 없이 입력 데이터만을 기반으로 모델을 실행. 주로 모델의 중간 결과를 얻거나 특정 계층의 출력을 분석할 때 사용.
model.h
모델의 이름, 입력 및 출력 데이터의 사이즈와 포맷, 그리고 모델에 관련된 추가 정보를 설정.
모델 이름 정의
1
2
#define AI_MODEL_MODEL_NAME "model"
#define AI_MODEL_ORIGIN_MODEL_NAME "model"
- 이 매크로는 모델의 이름과 원본 모델의 이름을 정의. 여기서는 둘 다 “model”로 설정.
활성화 데이터와 입력/출력 데이터의 정렬
1
2
3
#define AI_MODEL_ACTIVATIONS_ALIGNMENT (4)
#define AI_MODEL_INPUTS_IN_ACTIVATIONS (4)
#define AI_MODEL_OUTPUTS_IN_ACTIVATIONS (4)
AI_MODEL_ACTIVATIONS_ALIGNMENT는 활성화 데이터를 메모리에 정렬할 때 사용되는 바이트 경계를 정의. 여기서는 4바이트 정렬을 사용.AI_MODEL_INPUTS_IN_ACTIVATIONS와AI_MODEL_OUTPUTS_IN_ACTIVATIONS는 입력 및 출력 데이터가 활성화 데이터 버퍼 내에 저장될 때 사용되는 값.
모델 입력 데이터 정의
1
#define AI_MODEL_IN_NUM (1)
- 모델의 입력 수를 정의. 여기서는 하나의 입력만을 가지는 모델을 나타낸다.
1
2
#define AI_MODEL_IN \
ai_model_inputs_get(AI_HANDLE_NULL, NULL)
AI_MODEL_IN은 모델의 입력을 가져오는 데 사용되는 함수를 호출.
1
2
3
4
5
6
7
8
9
#define AI_MODEL_IN_SIZE { \
AI_MODEL_IN_1_SIZE, \
}
#define AI_MODEL_IN_1_FORMAT AI_BUFFER_FORMAT_FLOAT
#define AI_MODEL_IN_1_HEIGHT (24)
#define AI_MODEL_IN_1_WIDTH (32)
#define AI_MODEL_IN_1_CHANNEL (1)
#define AI_MODEL_IN_1_SIZE (24 * 32 * 1)
#define AI_MODEL_IN_1_SIZE_BYTES (3072)
- 모델의 첫 번째 입력에 대한 사이즈, 포맷, 차원(높이, 너비, 채널)을 정의. 입력 데이터는
AI_BUFFER_FORMAT_FLOAT포맷을 사용하며, 24x32 크기의 이미지와 1개의 채널을 가진다.
모델 출력 데이터 정의
1
#define AI_MODEL_OUT_NUM (1)
- 모델의 출력 수를 정의. 여기서는 하나의 출력만을 가지는 모델을 나타낸다.
1
2
#define AI_MODEL_OUT \
ai_model_outputs_get(AI_HANDLE_NULL, NULL)
AI_MODEL_OUT은 모델의 출력을 가져오는 데 사용되는 함수를 호출.
1
2
3
4
5
6
7
#define AI_MODEL_OUT_SIZE { \
AI_MODEL_OUT_1_SIZE, \
}
#define AI_MODEL_OUT_1_FORMAT AI_BUFFER_FORMAT_FLOAT
#define AI_MODEL_OUT_1_CHANNEL (5)
#define AI_MODEL_OUT_1_SIZE (5)
#define AI_MODEL_OUT_1_SIZE_BYTES (20)
- 모델의 첫 번째 출력에 대한 사이즈, 포맷, 그리고 채널 수를 정의. 출력 데이터는
AI_BUFFER_FORMAT_FLOAT포맷을 사용하며, 5개의 채널(예를 들어, 5개의 분류 클래스에 대한 확률)을 가진다.
추가 모델 정보
1
#define AI_MODEL_N_NODES (132)
- 모델 내부의 노드(계층) 수를 정의. 여기서는 132개의 노드가 있다고 설정되어 있다.
결과
사용 Device
STM32F767ZIT6
Flash: 2MiB
RAM : 512KiB
Model accuracy
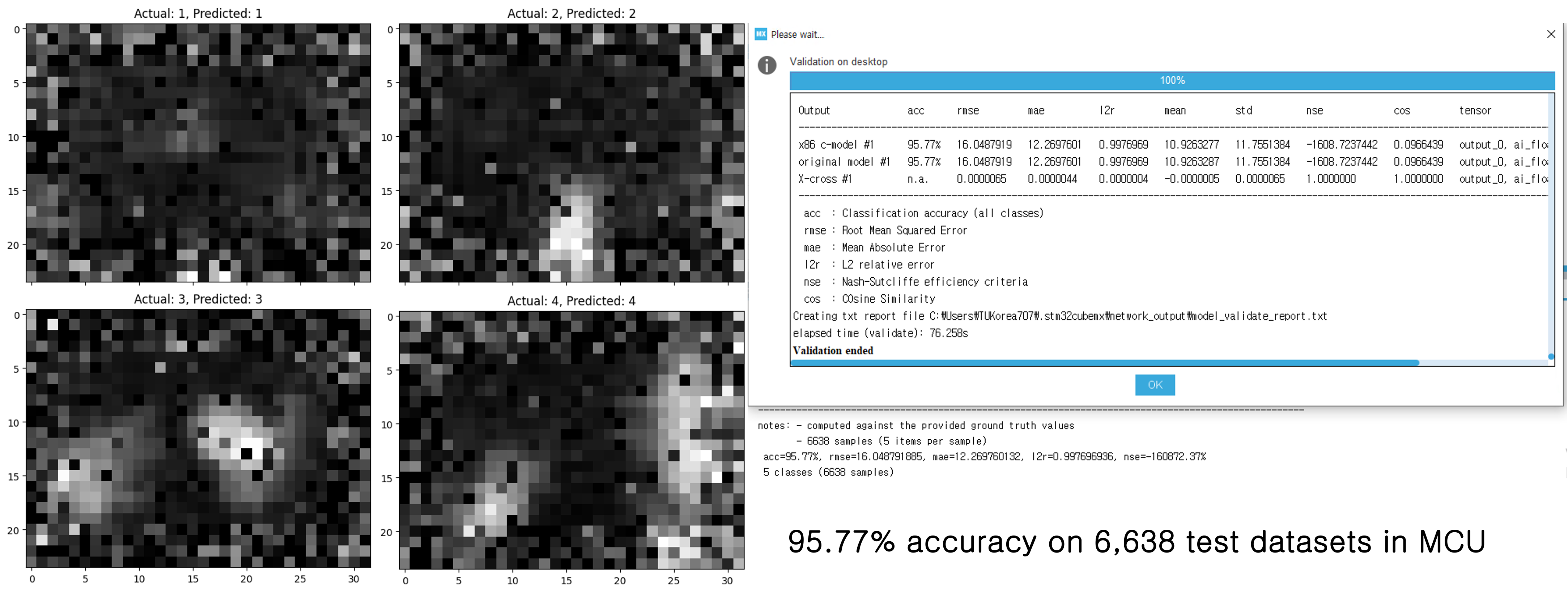
95.77% accuracy on 6,638 test datasets in MCU
Model predict result
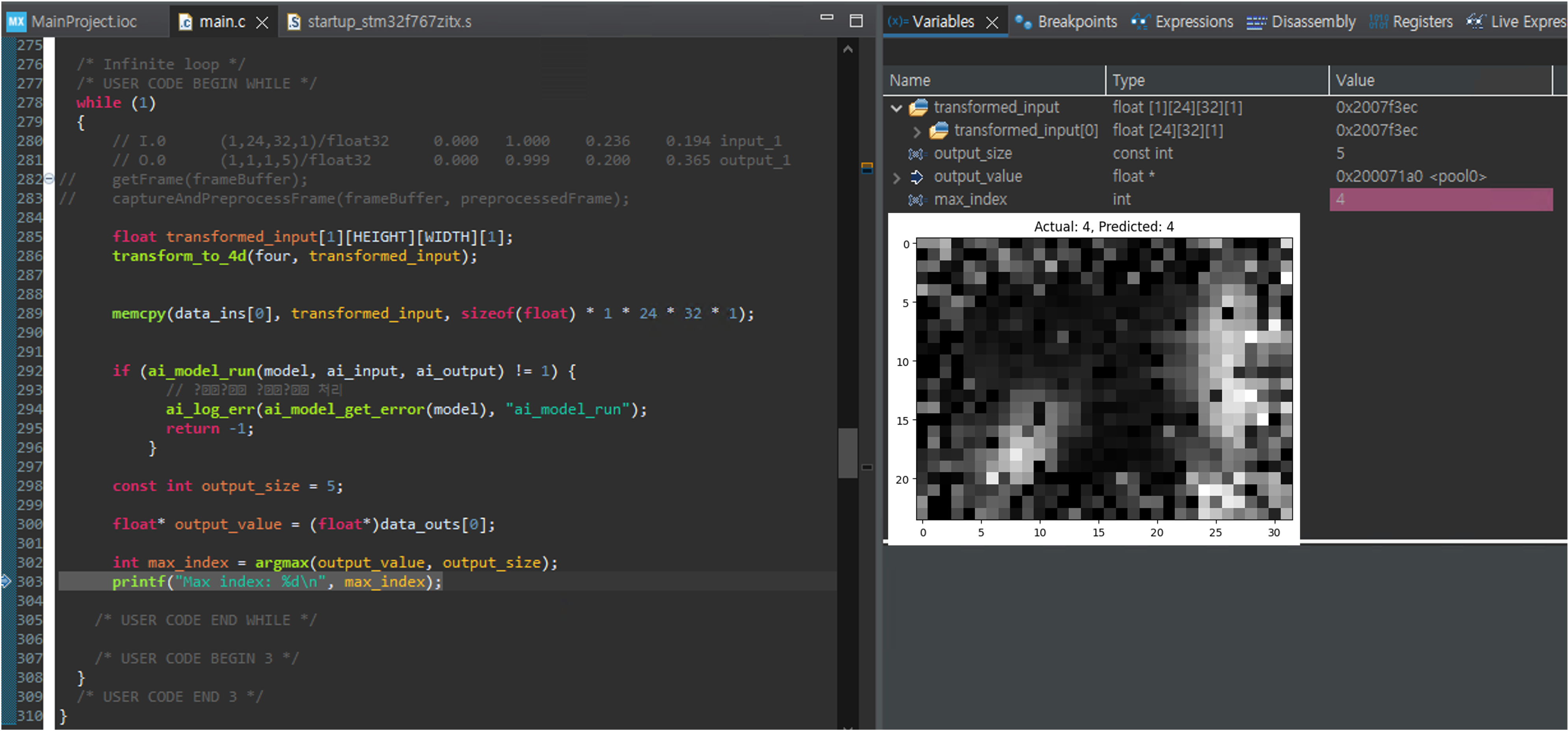
Model predict result(i2c in actual use)
.png)