Pytorch 기초
1
import torch
텐서 초기화
데이터로부터 직접 텐서 생성
1
2
data = [[1, 2], [3, 4]]
x_data = torch.tensor(data)
Numpy 배열로부터 생성
반대도 가능
1
2
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
다른 텐서로부터 생성
명시적으로 재정의 하지 않는다면, 인자로 주어진 텐서의 속성(모양(shape), 자료형(datatype))을 유지
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# x_data의 속성 유지
x_ones = torch.ones_like(x_data)
# x_data의 속성 덮어씀(자료형 바뀜)
x_rand = torch.rand_like(x_data, dtype = torch.float)
"""
Ones Tensor:
tensor([[1, 1],
[1, 1]])
Random Tensor:
tensor([[0.1410, 0.6257],
[0.3737, 0.3467]])
"""
무작위(random) 또는 상수(constant) 값 사용
shape은 텐서의 차원(dimension)을 나타내는 튜플(tuple)로, 아래 함수들에서는 출력 텐서의 차원을 결정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
shape = (2, 3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)
"""
Random Tensor:
tensor([[0.1705, 0.4169, 0.7231],
[0.5942, 0.1188, 0.5520]])
Ones Tensor:
tensor([[1., 1., 1.],
[1., 1., 1.]])
Zeros Tensor:
tensor([[0., 0., 0.],
[0., 0., 0.]])
"""
텐서의 속성(Attribute)
텐서의 속성은 텐서의 모양(shape), 자료형(datatype) 및 어느 장치에 저장 되는지를 나타낸다.
1
2
3
4
5
6
7
tensor = torch.rand(3, 4)
"""
Shape of tensor: torch.Size([3, 4])
Datatype of tensor: torch.float32
Device tensor is stored on: cpu
"""
텐서 연산 (Operation)
기본적으로 텐서는 CPU에 생성되지만 .to 메소드를 사용해 GPU로 텐서를 명시적으로 이동 가능.
1
2
if torch.cude.is_available():
tensor = tensor.to("cuda")
NumPy식의 표준 인덱싱과 슬라이싱
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
tensor = torch.rand(4, 4)
print(tensor)
print(f"First row: {tensor[0]}")
print(f"First column: {tensor[:, 0]}")
print(f"Last column: {tensor[..., -1]}")
tensor[:, 1] = 0
print(tensor)
"""
tensor([[0.2662, 0.6929, 0.5385, 0.4480],
[0.0499, 0.6138, 0.8756, 0.9174],
[0.8447, 0.6677, 0.0407, 0.8491],
[0.9659, 0.2635, 0.1464, 0.4120]])
First row: tensor([0.2662, 0.6929, 0.5385, 0.4480])
First column: tensor([0.2662, 0.0499, 0.8447, 0.9659])
Last column: tensor([0.4480, 0.9174, 0.8491, 0.4120])
tensor([[0.2662, 0.0000, 0.5385, 0.4480],
[0.0499, 0.0000, 0.8756, 0.9174],
[0.8447, 0.0000, 0.0407, 0.8491],
[0.9659, 0.0000, 0.1464, 0.4120]])
"""
텐서 합치기 torch.cat을 사용하여 주어진 차원에 따라 일련의 텐서를 연결 할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# dim == axis (0: 행방향, 1 열방향)
t1 = torch.cat([tensor, tensor, tensor], dim = 0)
"""
tensor([[0.2662, 0.0000, 0.5385, 0.4480],
[0.0499, 0.0000, 0.8756, 0.9174],
[0.8447, 0.0000, 0.0407, 0.8491],
[0.9659, 0.0000, 0.1464, 0.4120],
[0.2662, 0.0000, 0.5385, 0.4480],
[0.0499, 0.0000, 0.8756, 0.9174],
[0.8447, 0.0000, 0.0407, 0.8491],
[0.9659, 0.0000, 0.1464, 0.4120],
[0.2662, 0.0000, 0.5385, 0.4480],
[0.0499, 0.0000, 0.8756, 0.9174],
[0.8447, 0.0000, 0.0407, 0.8491],
[0.9659, 0.0000, 0.1464, 0.4120]])
"""
t1 = torch.cat([tensor, tensor, tensor], dim = 1)
"""
tensor([[0.6314, 0.0000, 0.6446, 0.6860, 0.6314, 0.0000, 0.6446, 0.6860, 0.6314, 0.0000, 0.6446, 0.6860],
[0.8336, 0.0000, 0.3110, 0.4294, 0.8336, 0.0000, 0.3110, 0.4294, 0.8336, 0.0000, 0.3110, 0.4294],
[0.6410, 0.0000, 0.5801, 0.7467, 0.6410, 0.0000, 0.5801, 0.7467, 0.6410, 0.0000, 0.5801, 0.7467],
[0.7296, 0.0000, 0.5763, 0.5586, 0.7296, 0.0000, 0.5763, 0.5586, 0.7296, 0.0000, 0.5763, 0.5586]])
"""
산술 연산(Arithmetic operations)
1
2
3
4
5
6
7
8
9
10
11
# 두 텐서 간의 행렬 곱 (y1 == y2 == y3)
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)
y3 = torch.rand_like(y1)
torch.matmul(tensor, tensor.T, out = y3)
# 요소별 곱(element-wise product)
z1 = tensor * tensor
z2 = tensor.mul(tensor)
z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out = z3)
단일-요소(single-element)텐서
텐서의 모든 값을 하나로 집계(aggregate)하여 요소가 하나인 텐서의 경우, item()을 사용하여 python숫자 값으로 변환
1
2
3
4
5
6
7
agg = tensor.sum()
agg_item = agg.item()
print(agg_item, type(agg_item))
"""
7.36817741394043 <class 'float'>
"""
바꿔치기(in-place) 연산 (권장 X)
연산 결과를 피연산자(operand)에 저장하는 연산을 바꿔치기 연산이라 부르며 _ 접미사를 갖는다. ex) x.copy_(y)나 x.t_() 는 x에 할당 없이 x를 직접 변경
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
print(f"{tensor} \n")
tensor.add_(5)
print(tensor)
"""
tensor([[0.6314, 0.0000, 0.6446, 0.6860],
[0.8336, 0.0000, 0.3110, 0.4294],
[0.6410, 0.0000, 0.5801, 0.7467],
[0.7296, 0.0000, 0.5763, 0.5586]])
tensor([[5.6314, 5.0000, 5.6446, 5.6860],
[5.8336, 5.0000, 5.3110, 5.4294],
[5.6410, 5.0000, 5.5801, 5.7467],
[5.7296, 5.0000, 5.5763, 5.5586]])
"""
NumPy 변환(Bridge)
CPU 상의 텐서와 NumPy 배열은 메모리 공간을 공유하기 때문에, 하나를 변경하면 다른 하나도 변경
텐서를 NumPy배열로 변환
1
2
3
4
5
6
7
8
9
t = torch.ones(5)
print(f"t: {t}")
n = t.numpy()
print(f"n: {n}")
"""
t: tensor([1., 1., 1., 1., 1.])
n: [1. 1. 1. 1. 1.]
"""
텐서의 변경 사항이 NumPy 배열에 반영
1
2
3
t.add_(1)
print(f"t: {t}")
print(f"n: {n}")
NumPy 배열을 텐서로 변환
1
2
n = np.ones(5)
t = torch.from_numpy(n)
NumPy 배열의 변경사항이 텐서에 반영
1
2
3
4
5
6
7
8
9
np.add(n, 1, out = n)
print(f"t: {t}")
print(f"n: {n}")
"""
t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
n: [2. 2. 2. 2. 2.]
"""
Dataset과 DataLoader
데이터 샘플을 처리하는 코드는 지저분하고 유지보수가 어려울 수 있다. 더 나은 가독성 과 모듈성 을 위해 데이터셋 코드를 모델 학습 코드로부터 분리하는 것이 이상적이다.
PyTorch는 torch.utils.data.DataLoader와 torch.utils.data.Dataset 의 두가지 데이터 기본 요소를 제공하여 미리 준비해둔(pre-loaded) 데이터셋 뿐만 아니라 가지고 있는 데이터를 사용할 수 있도록 한다. Dataset은 샘플과 정답(label)을 저장하고, DataLoader 는 Dataset을 샘플에 쉽게 접근할 수 있도록 순회 가능한 객체(iterable)로 감싼다.
PyTorch의 도메인 특화 라이브러리들은 (FashionMNIST와 같은) 미리 준비해둔(pre-loaded) 다양한 데이터셋을 제공한다. 데이터셋은 torch.utils.data.Dataset의 하위 클래스로 개별 데이터를 특정하는 함수가 구현되어 있다. 이러한 데이터셋은 모델을 만들어보고(prototype) 성능을 측정 (benchmark)하는데 사용할 수 있다
데이터셋 불러오기
- root : 학습/테스트 데이터가 저장되는 경로
- train : 학습용 또는 테스트용 데이터셋 여부를 지정
- download = True : root에 데이터가 없는 경우 인터넷에서 다운로드
- transform, target_transform : feature와 label 변형을 지정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root = "data",
train = True,
download = True,
transform = ToTensor()
)
test_data = datasets.FashionMNIST(
root = "data",
train = False,
download = True,
transform = ToTensor()
)
데이터셋을 순회하고 시각화
Dataset에 리스트 처럼 직접 접근(index)할 수 있다. training_data[index].matplotlib을 사용해 학습 데이터의 일부를 시각화
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag"
9: "Ankle Boot",
}
figure = plt.figure(figsize = (8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size = (1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
# img shape = (1, 28, 28)
# img.squeeze().shape = (28, 28)
plt.imshow(img.squeeze(), cmap = 'gray')
plt.show()
파일에서 사용자 정의 데이터셋 만들기
사용자 정의 Dataset 클래스는 반드시 3개 함수를 구현해야 한다.
__init__, __len__, __getitem__
아래 구현을 살펴보면 FashionMNIST 이미지들은 img_dir 디렉토리에 저장되고, 정답은 annotations_file csv 파일에 별도로 저장된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file, names=['file_name', 'label'])
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
"""
`self.img_labels`가 이미지 파일 이름을 포함하는 열과 해당 이미지의 레이블을 포함하는 열을 가지고 있다면,
`self.img_labels.iloc[idx, 0]`는 `idx`에 해당하는 이미지 파일의 이름을 반환.
이 이름은 후속 코드 `os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])`에서 이미지 파일의 전체 경로를 구성하는 데 사용
여기서 `self.img_dir`은 이미지 파일들이 저장된 디렉토리의 경로를 나타냅니다.
"""
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
__init__
__init__ 함수는 Dataset 객체가 생성(instantiate)될 때 한 번만 실행 여기서는 이미지와 주석 파일(annotation_file)이 포함된 디렉토리와 두가지 변형(transform)을 초기화
labels.csv ex)
1
2
3
4
tshirt1.jpg, 0
tshirt2.jpg, 0
......
ankleboot999.jpg, 9
1
2
3
4
5
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
__len__
__len__ 함수는 데이터셋의 샘플 개수를 반환
1
2
def __len__(self):
return len(self.img_labels)
__getitem__
__getitem__ 함수는 주어진 인덱스 idx에 해당하는 샘플을 데이터셋에서 불러오고 반환 인덱스를 기반으로, 디스크에서 이미지의 위치를 식별하고, read_image를 사용하여 이미지를 텐서로 변환하고, self.img_labels의 csv 데이터로부터 해당하는 정답(label)을 가져오고, (해당하는 경우) 변형(transform) 함수들을 호출한 뒤, 텐서 이미지와 라벨을 Python 사전(dict) 형으로 반환
1
2
3
4
5
6
7
8
9
10
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
sample = {"image" : image, "label" : label}
return sample
DataLoader로 학습용 데이터 준비
Dataset은 데이터셋의 특징(feature)을 가져오고 하나의 샘플에 정답(label)을 지정하는 일을 한번에 수행. 모델을 학습할 때, 일반적으로 샘플들을 “minibatch”로 전달하고, 매 에폭(epoch)마다 데이터를 다시 섞어 과적합(overfit)을 막고, Python의 multiprocessing을 사용하여 데이터 검색 속도를 높힌다.
DataLoader는 간단한 API로 이러한 복잡한 과정들을 추상화한 순회 가능한 객체(iterable)이다.
1
2
3
4
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size = 64, shuffle = True)
test_dataloader = DataLoader(test_data, batch_size = 64, shuffle = True)
DataLoader를 통해 순회(iterate)
DataLoader에 데이터셋을 불러온 뒤에는 필요에 따라 데이터셋을 순회(iterate)할 수 있다. 아래의 각 순회(iteration)는 (각각 batch_size=64) 의 특징(feature)과 정답(label)을 포함하는) train_features와 train_labels 의 묶음(batch)을 반환한다. shuffle = True로 지정했으므로, 모든 배치를 순회한 뒤 데이터가 섞인다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap = 'gray')
plt.show()
print(f"Label: {label}")
"""
Feature batch shape: torch.Size([64, 1, 28, 28])
Labels batch shape: torch.Size([64])
"""
Transform
데이터가 항상 머신러닝 알고리즘 학습에 필요한 최종 처리가 된 형태로 제공되지는 않는다. 변형(Transform)을 해서 데이터를 조작하고 학습에 적합하게 만든다.
모든 TorchVision 데이터셋들은 변형 로직을 갖는, 호출 가능한 객체(callable)를 받는 매개변수 두개 ( 특징(feature)을 변형하기 위한 transform과 정답(label)을 변경하기 위한 target_transform)를 갖는다.
FashionMNIST 특정(feature)은 PIL Image형식이며, 정답(label)은 정수(intefer)이다. 학습을 하려면 정규화(normalize)된 텐서 형태의 특징(feature)과 one-hot으로 encoding된 텐서 형태의 정답(label)이 필요하다. 이러한 변형(transformation)을 하기 위해 ToTensor와 Lambda를 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root = 'data',
train = True,
download = True,
# `transform=ToTensor()`는 PyTorch의 `torchvision.transforms` 모듈에 있는 `ToTensor` 변환을 의미
# 이 변환을 사용하면 이미지 데이터를 PyTorch의 텐서(tensor)로 변환하고, 동시에 이미지의 픽셀 값 범위를 [0, 255]에서 [0.0, 1.0]으로 정규화
transform=ToTensor(),
# y 값은 0 ~ 9 사이
# 레이블 y를 받아 해당 레이블에 해당하는 위치를 제외하고 모두 0이며, 레이블 위치만 1인 10차원의 one-hot 인코딩 벡터를 생성하는 함수
target_transform = Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(dim = 0, index = torch.tensor(y), value = 1))
)
구조 분석
- Lambda:
Lambda는torchvision.transforms모듈의 기능 중 하나로, 사용자 정의 람다(lambda) 함수를 변환(transform)으로 사용할 수 있게 해줍니다. 이를 통해 레이블 데이터에 대한 임의의 변환을 정의할 수 있습니다.
- lambda 함수:
lambda y: ...는 레이블y를 입력으로 받는 람다 함수를 정의합니다. 이 함수는y에 대해 특정 변환을 수행한 결과를 반환합니다.
- torch.zeros(10, dtype=torch.float):
torch.zeros(10, dtype=torch.float)는 길이가 10이고, 모든 요소가 0인 부동소수점 타입의 텐서를 생성합니다. 이 텐서는 원-핫 인코딩된 벡터의 기반이 됩니다. 길이 10은 클래스의 개수를 가정한 것으로, 분류하려는 타겟 클래스가 10개라는 것을 의미합니다.
- scatter_(0, torch.tensor(y), value=1):
.scatter_메소드는 텐서에 직접 값을 할당하는 in-place 연산으로, 여기서는 원-핫 인코딩을 생성하는 데 사용됩니다.- 첫 번째 인자
0은 차원(dim)을 나타내며, 여기서는 0번째 차원(즉, 텐서의 길이 방향)에 대해 작업을 수행한다는 것을 의미합니다. torch.tensor(y)는 레이블y를 텐서로 변환합니다. 이 텐서는.scatter_메소드에서 인덱스로 사용됩니다.value=1은 지정된 인덱스의 위치에 할당될 값으로, 이 경우에는 1입니다. 즉, 레이블y에 해당하는 위치에 1을 할당하여 원-핫 인코딩을 완성합니다.
해설
이 코드는 레이블 y를 입력으로 받아, 해당 레이블에 해당하는 위치를 제외하고 모두 0인 길이가 10인 텐서를 생성하고, y에 해당하는 위치만 값을 1로 설정하여 원-핫 인코딩된 벡터를 반환합니다. 예를 들어, 레이블 y가 3이라면, 이 코드는 [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]과 같은 텐서를 생성합니다.
이러한 원-핫 인코딩 방식은 분류 문제에서 널리 사용되며, 각 클래스가 독립적인 출력으로 표현되어야 할 때 유용합니다. 이 방법은 모델이 각 클래스에 대한 확률을 분명하게 예측하도록 돕습니다.
ToTensor()
ToTensor 는 PIL Image나 NumPy ndarray를 FloatTensor로 변환하고, 이미지 픽셀의 크기(intensity) 값을 [0., 1.]범위로 비례하여 조정(scale)한다.
Lambda 변형(Transform)
Lambda 변형은 사용자 정의 람다(lambda) 함수를 적용한다. 여기에서는 정수를 one-hot 으로 인코딩된 텐서로 바꾸는 함수를 정의. 이 함수는 먼저 (데이터셋 정답 갯수인) 크기 10짜리 0 텐서(zero tensor)를 만들고, scatter_ 를 호출하여 주어진 정답 y에 해당하는 인덱스에 value = 1을 할당
1
2
target_transform = Lambda(lambda y: torch.zeros(
10, dtype = torch.float).scatter_(dim = 0, index = torch.tensor(y), value = 1))
신경망 모델 구성하기
신경망은 데이터에 대한 연산을 수행하는 계층(layer)/모듈(module)로 구성되어 있다. torch.nn 네임스페이스는 신경망을 구성하는데 필요한 모든 구성 요소를 제공한다. PyTorch의 모든 모듈은 nn.Module의 하위 클래스(subclass)이다. 신경망은 다른 모듈 (계층; layer)로 구성된 모듈이다. 이러한 중첩된 구조는 복잡한 아키텍쳐를 쉽게 구축하고 관리할 수 있다.
1
2
3
4
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
학습을 위한 장치 얻기
1
2
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"using {device} device")
클래스 정의
신경망 모델을 nn.Module 의 하위클래스로 정의하고, __init__ 에서 신경망 계층들을 초기화 한다. nn.Module을 상속받은 모든 클래스는 forward 메소드에 입력 데이터에 대한 연산들을 구현한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512), # in feature, out feature
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.leaner_relu_stack(x)
return logits
NeuralNetwork 의 인스턴스(instance)를 생성하고 이를 device로 이동한 뒤, 구조(structure)를 출력한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
model = NeuralNetwork().to(device)
print(model)
"""
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
"""
모델을 사용하기 위해 입력데이터를 전달한다. 이는 일부 백그라운드 연산들과 함께 모델의 forward 를 실행한다.
mode.forward()를 직접 호출하면 안된다.
모델에 입력을 호출하면 각 분류(class)에 대한 원시(raw) 예측값이 있는 10차원 텐서가 반환된다. 원시 예측값을 nn.Softmax 모듈의 인스턴스에 통과시켜 예측 확률을 얻는다.
1
2
3
4
5
6
7
8
9
10
11
X = torch.rand(1, 28, 28, device = device)
logits = model(x)
pred_probab = nn.Softmax(dim = 1)(logits)
y_pred = pred_probab.argmax(dim = 1)
print(f"predicted class: {y_pred}")
"""
Predicted class: tensor([8], device='cuda:0')
"""
모델 계층(Layer)
1
2
3
4
5
6
input_image = torch.rand(3, 28, 28) # 28x28 크기의 이미지 3장으로 구성된 미니배치
print(input_iamge.size())
"""
torch.Size([3, 28, 28])
"""
nn.Flatten
nn.Flatten 계층을 초기화하여 각 28x28의 2D이미지를 784픽셀 값을 갖는 연속된 배열로 변환한다.
(dim = 0 의 미니배치 차원은 유지)
1
2
3
4
5
6
7
flatten = nn.Flatten()
flat_iamge = flatten(input_image)
print(flat_image.size())
"""
torch.Size([3, 784])
"""
nn.Linear
선형 계층은 저장된 가중치(weight)와 편향(bias)을 사용해 입력에 선형 변환(linear transformation)을 적용하는 모듈
1
2
3
4
5
6
7
layer1 = nn.Linear(in_feature=28*28, out_feature = 20)
hidden1 = layer1(flat_image)
print(hidden1.size())
"""
torch.Size([3, 20])
"""
nn.ReLU
비선형 활성화(activation)는 모델의 입력과 출력 사이에 복잡한 관계(mapping)를 만든다. 비선형 활성화는 선형 변환 후에 적용되어 비선형성(nonlinearity) 을 도입하고, 신경망이 다른 현상을 학습할 수 있도록 돕는다.
이 모델에서는 nn.ReLU를 선형 계층들 사이에 사용하지만, 모델을 만들 때는 비선형성을 가진 다른 활성화를 도입할 수도 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")
"""
Before ReLU: tensor([[-0.3858, -0.1579, -0.1333, 0.0358, 0.0529, -0.0907, 0.1169, -0.0973,
-0.2388, 0.2646, 0.2303, 0.0362, -0.2612, 0.0344, 0.1711, -0.3830,
-0.0534, 0.0704, 0.4804, -0.2544],
[-0.7281, 0.2420, 0.1238, 0.0509, -0.0304, -0.3439, -0.0392, -0.0821,
-0.1728, 0.1718, 0.3270, 0.1842, 0.2016, 0.1120, -0.0883, -0.5609,
-0.1216, 0.1158, 0.5519, -0.3336],
[-0.6948, -0.1428, 0.1198, 0.2855, 0.1055, -0.1769, 0.3291, -0.3199,
-0.0686, 0.1908, 0.1393, -0.0129, 0.0203, -0.1860, 0.0931, -0.3663,
-0.2686, 0.1985, 0.3661, 0.0224]], grad_fn=<AddmmBackward0>)
After ReLU: tensor([[0.0000, 0.0000, 0.0000, 0.0358, 0.0529, 0.0000, 0.1169, 0.0000, 0.0000,
0.2646, 0.2303, 0.0362, 0.0000, 0.0344, 0.1711, 0.0000, 0.0000, 0.0704,
0.4804, 0.0000],
[0.0000, 0.2420, 0.1238, 0.0509, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.1718, 0.3270, 0.1842, 0.2016, 0.1120, 0.0000, 0.0000, 0.0000, 0.1158,
0.5519, 0.0000],
[0.0000, 0.0000, 0.1198, 0.2855, 0.1055, 0.0000, 0.3291, 0.0000, 0.0000,
0.1908, 0.1393, 0.0000, 0.0203, 0.0000, 0.0931, 0.0000, 0.0000, 0.1985,
0.3661, 0.0224]], grad_fn=<ReluBackward0>)
"""
nn.Sequential
nn.sequential 은 순서를 갖는 모듈의 컨테이너. 데이터는 정의된 것과 같은 순서로 모든 모듈들을 통과해 전달된다. 순차 컨테이너(sequential container)를 사용하여 아래의 seq_modules 과 같은 신경망을 빠르게 만들 수 있다.
1
2
3
4
5
6
7
8
9
seq_modules = nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20, 10)
)
input_image = torch.rand(3, 28, 28)
logits = seq_modules(input_imgae)
nn.Softmax
신경망의 마지막 선형 계층은 nn.Softmax 모듈에 전달될 $[-\infty, \infty]$ 범위의 원시 값 (raw value)인 logits를 반환한다. logits 는 모델의 각 분류(class)에 대한 예측 확률을 나타내도록 [0, 1] 범위로 비례하여 조정(scale)된다. dim 매개변수는 값의 합이 1이 되는 차원을 나타낸다.
1
2
softmax = nn.Softmax(dim = 1)
pred_probab = softmax(logits)
모델 매개변수
신경망 내부의 많은 계층들은 매개변수화(parameterize)된다. 즉, 학습 중에 최적화되는 가중치와 편향과 연관지어진다. nn.Module을 상속하면 모델 객체 내부의 모든 필드들이 자동으로 추적(track)되며, 모델의 parameters() 및 named_paramters()메소드로 모든 매개변수에 접근할 수 있게 된다.
아래 예제에서는 각 매개변수들을 순회하며(iterate), 매개변수의 크기와 값을 출력한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
print(f"Model structure: {model}\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]}")
"""
Model structure: NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
Layer: linear_relu_stack.0.weight | Size: torch.Size([512, 784]) | Values : tensor([[ 0.0056, 0.0250, 0.0112, ..., 0.0124, -0.0328, -0.0238],
[-0.0096, 0.0251, 0.0021, ..., -0.0061, -0.0240, 0.0163]],
device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.0.bias | Size: torch.Size([512]) | Values : tensor([ 0.0196, -0.0025], device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.2.weight | Size: torch.Size([512, 512]) | Values : tensor([[ 0.0163, -0.0337, -0.0116, ..., 0.0155, 0.0049, 0.0419],
[ 0.0302, 0.0108, -0.0281, ..., 0.0312, -0.0207, 0.0067]],
device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.2.bias | Size: torch.Size([512]) | Values : tensor([0.0209, 0.0436], device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.4.weight | Size: torch.Size([10, 512]) | Values : tensor([[-0.0227, 0.0324, 0.0321, ..., -0.0018, 0.0294, -0.0229],
[ 0.0381, -0.0395, 0.0149, ..., -0.0205, 0.0408, -0.0343]],
device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.4.bias | Size: torch.Size([10]) | Values : tensor([-0.0422, -0.0089], device='cuda:0', grad_fn=<SliceBackward0>)
"""
모델 매개변수 최적화하기
데이터에 매개변수를 최적화하여 모델을 학습하고, 검증하고, 테스트 모델을 학습하는 과정은 반복적인 과정을 거친다. (에폭 (epoch)이라고 부르는) 각 반복 단계에서 모델은 출력을 추측하고, 추측과 정답 사이의 오류 (손실(loss)) 를 계산하고, 매개변수에 대한 오류의 도함수(derivative)를 수집한 뒤, 경사하강법을 사용해 이 파라미터들을 최적화(optimize) 한다.
기본 (Pre-requisite) 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
training_data = datasets.FashionMNIST(
root = "data",
train = True,
download = True,
transform = ToTensor()
)
test_data = datasets.FashionMNIST(
root = "data",
train = False,
download = True,
transform = ToTensor()
)
train_dataloader = DataLoader(train_data, batch_size = 64)
test_dataloader = DataLoader(test_data, batch_size = 64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU()
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
하이퍼파라미터(Hyperparameter)
하이퍼파라미터(Hyperparameter)는 모델 최적화 과정을 제어할 수 있는 조절 가능한 매개변수. 서로 다른 하이퍼파라미터 값은 모델 학습과 수렴율(convergence rate)에 영향을 미칠 수 있다.
학습시에는 다음과 같은 하이퍼파라미터를 정의한다.
- 에폭(epoch)수 : 데이터셋을 반복하는 횟수
- 배치 크기(batch_size) : 매개변수가 생신되기 전 신경망을 통해 전파된 데이터 샘플의 수
- 학습률(learning rate) : 각 배치 / 에폭에서 모델의 매개변수를 조절하는 비율. 값이 작을수록 학습 속도가 느려지고, 값이 크면 학습 중 예측할 수 없는 동작이 발생할 수 있다.
1
2
3
learning_rate = 1e-3
batch_size = 64
epochs = 5
최적화 단계(Optimization Loop)
하이퍼파라미터를 설정한 뒤에는 최적화 단계를 통해 모델을 학습하고 최적화할 수 있다. 최적화 단계의 각 반복(iteration)을 에폭 이라 부른다.
하나의 에폭은 다음 두 부분으로 구성된다.
- 학습 단계(train loop) - 학습용 데이터셋을 반복(iterate)하고 최적의 매개변수로 수렴한다.
- 검증/테스트 단계(validation/test loop) - 모델의 성능이 개선되고 있는지를 확인하기 위해 테스트 데이터셋을 반복(iterate)한다.
학습 단계(training loop)에서 일어나는 일
손실 함수(loss function)
학습용 데이터를 제공하면, 학습되지 않은 신경망은 정답을 제공하지 않을 확률이 높다. 손실함수(loss function)는 획득한 결과와 실제 값 사이의 틀린 정도(degree of dissimilarity)를 측정하며, 학습 중에 이 값을 최소화하려고 한다. 주어진 데이터 샘플을 입력으로 계산한 예측과 정답(label)을 비교하여 손실(loss)을 계산한다.
일반적인 손실함수에는 회귀문제(regression task)에 사용하는 nn.MSELoss (평균 제곱 오차) 나 분류(clasification)에 사용되는 nn.NLLLoss(Negative Log Likelihood), 그리고 nn.LogSoftmax 와 nn.NLLLoss 를 합친 nn.CrossEntropyLoss 등이 있다.
모델의 출력 logit을 nn.CrossEntropyLoss에 전달해 logit을 정규화하고 예측 오류를 계산한다.
1
2
# 손실함수 초기화
loss_fn = nn.CrossEnropyLoss()
옵티마이저 (Optimizer)
최적화는 각 학습 단계에서 모델의 오류를 줄이기 위해 모델 매개변수를 조정하는 과정이다. 최적화 알고리즘은 이 과정이 수행되는 방식을 정의한다. 모든 최적화 절차(logic)은 optimizer객체에 캡슐와(encapsulate)된다.
학습하려는 모델의 매개변수와 학습률 (learning rate) 하이퍼파라미터를 등록하여 Optimizer를 초기화 한다.
1
optimizer = torch.optim.SGD(model.paramters(), lr = learning_rate)
학습 단계(loop)에서 최적화는 세 단계로 이루어 진다.
optimizer.zero_grad()를 호출해 모델 매개변수의 변화도를 재설정한다. 기본적으로 변화도는 더해지기(add up)때문에 중복 계산을 막기 위해 반복할 때마다 명시적으로 0으로 설정한다loss.backwards()를 호출해 예측 손실(prediction loss)을 역정파한다. PyTorch는 각 매개변수에 대한 손실의 변화도를 저장한다.- 변화도를 계산한 뒤에는
optimizer.step()을 호출해 역전파 단계에서 수집된 변화도로 매개변수를 조정
전체 구현
최적화 코드를 반복하여 수행하는 train_loop 와 테스트 데이터로 모델의 성능을 측정하는 test_loop 를 정의
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def train_loop(dataloader, model, loos_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
# 예측(prediction)과 손실(loss)를 계산
pred = model(x)
loss = loss_fn(pred, y)
# 역전파
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d/{size:>5d}}]")
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad(): # PyTorch에서 자동 미분(autograd)엔진이 텐서에 대한 연산 추적을 일시적으로 비활성화
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100 * correct) :> 0.1f}%, Avg loss: {test_loss:>8f}\n")
손실 함수와 옵티마이저를 초기화하고 train_loop 와 test_loop 에 전달한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!)
"""
Epoch 1
-------------------------------
loss: 2.305402 [ 0/60000]
loss: 2.288151 [ 6400/60000]
loss: 2.275361 [12800/60000]
loss: 2.271551 [19200/60000]
loss: 2.262455 [25600/60000]
loss: 2.230606 [32000/60000]
loss: 2.232600 [38400/60000]
loss: 2.201989 [44800/60000]
loss: 2.203456 [51200/60000]
loss: 2.180487 [57600/60000]
Test Error:
Accuracy: 47.5%, Avg loss: 2.169787
Epoch 2
-------------------------------
loss: 2.176373 [ 0/60000]
loss: 2.166049 [ 6400/60000]
loss: 2.118096 [12800/60000]
loss: 2.136652 [19200/60000]
loss: 2.093650 [25600/60000]
loss: 2.035787 [32000/60000]
loss: 2.054227 [38400/60000]
loss: 1.982763 [44800/60000]
loss: 1.990187 [51200/60000]
loss: 1.932767 [57600/60000]
Test Error:
Accuracy: 60.3%, Avg loss: 1.921545
Epoch 3
-------------------------------
loss: 1.951017 [ 0/60000]
loss: 1.921927 [ 6400/60000]
loss: 1.811325 [12800/60000]
loss: 1.851000 [19200/60000]
loss: 1.745803 [25600/60000]
loss: 1.698114 [32000/60000]
loss: 1.702955 [38400/60000]
loss: 1.608236 [44800/60000]
loss: 1.631362 [51200/60000]
loss: 1.536411 [57600/60000]
Test Error:
Accuracy: 59.8%, Avg loss: 1.545819
Epoch 4
-------------------------------
loss: 1.611245 [ 0/60000]
loss: 1.572988 [ 6400/60000]
loss: 1.423452 [12800/60000]
loss: 1.495310 [19200/60000]
loss: 1.377467 [25600/60000]
loss: 1.368020 [32000/60000]
loss: 1.368429 [38400/60000]
loss: 1.297531 [44800/60000]
loss: 1.326762 [51200/60000]
loss: 1.236822 [57600/60000]
Test Error:
Accuracy: 63.2%, Avg loss: 1.260925
Epoch 5
-------------------------------
loss: 1.338428 [ 0/60000]
loss: 1.316166 [ 6400/60000]
loss: 1.151961 [12800/60000]
loss: 1.257553 [19200/60000]
loss: 1.136688 [25600/60000]
loss: 1.154902 [32000/60000]
loss: 1.166386 [38400/60000]
loss: 1.109468 [44800/60000]
loss: 1.137820 [51200/60000]
loss: 1.065428 [57600/60000]
Test Error:
Accuracy: 65.1%, Avg loss: 1.087270
Done!
"""
모델 저장하고 불러오기
1
2
import torch
import torchvision.models as models
모델 가중치 저장하고 불러오기
PyTorch 모델은 학습한 매개변수를 state_dict 라고 불리는 내부 상태 사전(internal state dictionary)에 저장한다. 이 상태값들은 torch.save 메소드를 사용해 저장할 수 있다.
1
2
model = models.vgg16(pretrained=True)
torch.save(model.state_dict(), 'model_weights.pth')
모델 가중치를 불러오기 위해서는, 먼저 동일한 모델의 인스턴스(instance)를 생성한 다음 load_state_dict() 메소드를 사용해 매개변수들을 불러온다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
model = models.vgg16() # 기본 가중치를 불러오지 않으므로 pretrained=True를 지정하지 않는다.
model.load_state_dict(torch.load('model_weights.pth'))
model.eval()
"""
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
"""
Note
추론(inference)을 하기 전에 ``model.eval()`` 메소드를 호출하여 드롭아웃(dropout)과 배치 정규화(batch normalization)를 평가 모드(evaluation mode)로 설정해야 한다. 그렇지 않으면 일관성 없는 추론 결과가 생성된다.
모델의 형태를 포함하여 저장하고 불러오기
모델의 가중치를 불러올 때, 신경망의 구조를 정의하기 위해 모델 클래스를 먼저 생성(instantiate)해야 했지만, 이 클래스의 구조를 모델과 함께 저장하고 싶으면, (model.state_dict() 가 아닌) model을 저장함수에 전달한다.
1
torch.save(model, 'model.pth')
다음과 같이 모델을 불러올 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
model = torch.load('model.pth')
model
"""
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
"""
Note
이 접근 방식은 Python `pickle <https://docs.python.org/3/library/pickle.html>`_ 모듈을 사용하여 모델을 직렬화(serialize)하므로, 모델을 불러올 때 실제 클래스 정의(definition)를 적용(rely on)한다.
Convolutional Neural Networks
1
2
3
4
5
6
7
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Convolution operator
- Fully-connected network(FCN)의 한계
- FCN에서는 모든 input의 모든 element들이 연결되어 다음 layer의 element를 만들어 낸다.
- 이 결과 FCN은 많은 수의 파라미터를 가지게 되고, 학습이 굉장히 비효율적이고, overfitting으로 인해 낮은 성능을 보인다.
- CNN
CNN은 local connectivity라는 가정을 통해 다음 일부의 element들 간 연결이 된다.

그리고 element들은 weight을 share한다.

Activation map

Convolution operator - torch.nn.Module
torch.nn 패키지의 nn.Module 클래스의 convolution 모듈을 이용해 convolution layer를 구현 먼저 image사이즈의 random tensor를 만들고, Random filter를 이용해 이미지를 convolve 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# Create 10 random images of shape(1, 28, 28)
images = torch.rand(10, 1, 28, 28)
# Build 6 conv. filters
conv_filters = nn.Conv2d(in_channels = 1, out_channel = 6, kernel_size=(3,3), stride = 1, padding = 1)
# Convolve the image with the filters
output_feature = conv_filters(images)
print(output_feature.shape)
"""
torch.Size([10, 6, 28, 28])
"""
Convolution operator - torch.nn.functional
모델을 구성할 때는 주로 torch.nn 의 module등을 이용해 nn.Module class를 주로 구성하지만, functional 방식으로 torch.nn.functional 을 이용해 CNN을 구성할 수 도 있다. 이미지와 필터를 구성한 뒤에 convolution function에 입력으로 넣어주게 된다.
1
2
3
4
5
6
7
8
9
images = torch.rand(10, 1, 28, 28)
filters = torch.rand(6, 1, 3, 3)
output_feature = F.conv2d(images, filters, stride = 1, padding = 1)
print(output_feature.shape)
"""
torch.Size([10, 6, 28, 28])
"""
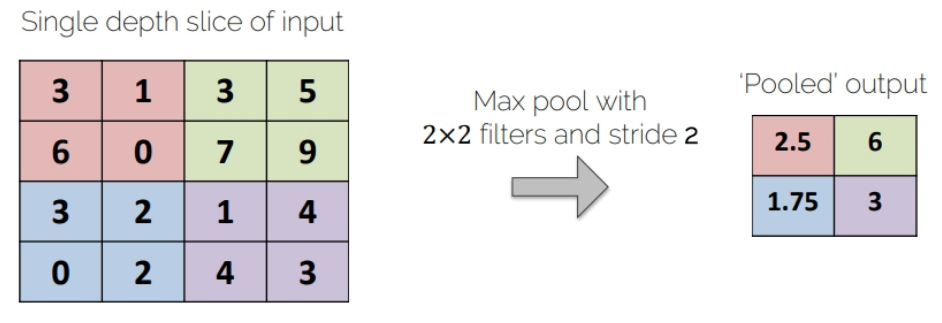
Pooling operators
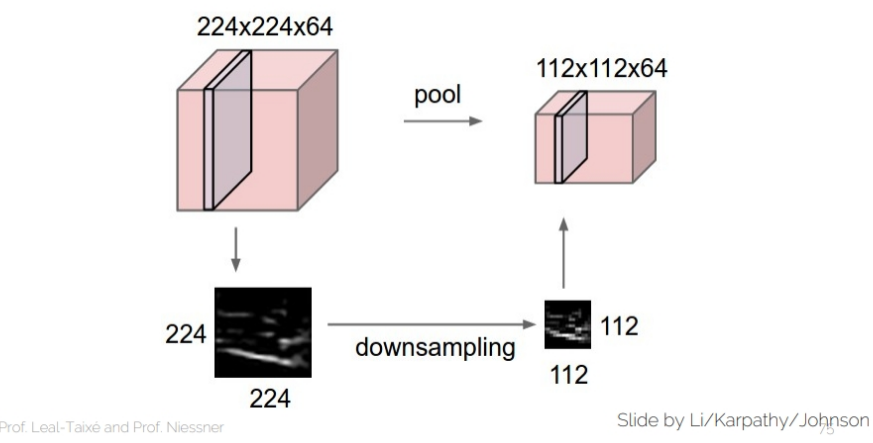
Max-Pooling
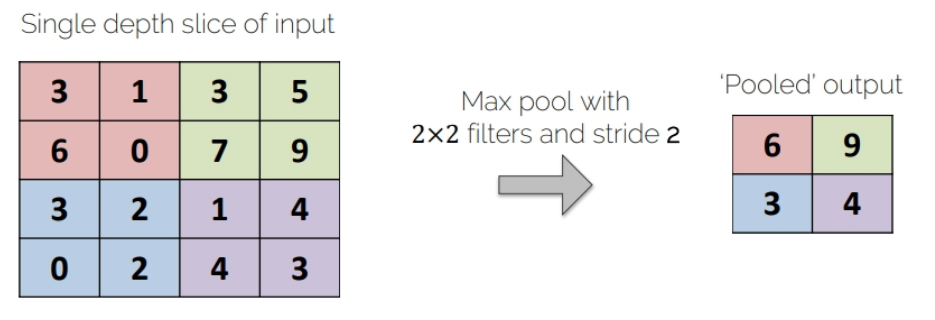
Average-Pooling
Max-pooling operator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
im = torch.rand(1, 1, 6, 6)
print(im)
"""
tensor([[[[0.9898, 0.4500, 0.0960, 0.2501, 0.8874, 0.2399],
[0.8767, 0.9804, 0.6105, 0.7821, 0.1379, 0.1649],
[0.2308, 0.3177, 0.3534, 0.5684, 0.5967, 0.3972],
[0.3661, 0.9300, 0.4619, 0.4189, 0.8395, 0.6891],
[0.4644, 0.1608, 0.2038, 0.6788, 0.0543, 0.4698],
[0.8717, 0.0946, 0.1381, 0.3624, 0.8110, 0.3646]]]])
"""
max_pooling = nn.MaxPool2d(2) # 2x2
output_feature = max_pooling(im)
output_feature_F = F.max_pool2d(im, 2)
print(output_feature)
print(output_feature_F)
"""
tensor([[[[0.9898, 0.7821, 0.8874],
[0.9300, 0.5684, 0.8395],
[0.8717, 0.6788, 0.8110]]]])
tensor([[[[0.9898, 0.7821, 0.8874],
[0.9300, 0.5684, 0.8395],
[0.8717, 0.6788, 0.8110]]]])
"""
Average-pooling operator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
avg_pooling = nn.AvgPool2d(2)
output_feature = avg_pooling(im)
output_feature_F = F.avg_pool2d(im, 2)
print(output_feature)
print(output_feature_F)
"""
tensor([[[[0.8242, 0.4347, 0.3575],
[0.4611, 0.4507, 0.6306],
[0.3979, 0.3458, 0.4249]]]])
tensor([[[[0.8242, 0.4347, 0.3575],
[0.4611, 0.4507, 0.6306],
[0.3979, 0.3458, 0.4249]]]])
"""
Convolutional Neural Networks (AlexNet)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
class AlexNet(nn.Module):
def __init__(self, num_classes = 10):
super(AlexNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size = 11, stride = 4, padding = 2)
self.relu = nn.ReLU(inplace = True)
self.maxpool = nn.MaxPool2d(kernel_size = 3, stride = 2)
self.conv2 = nn.Conv2d(64, 192, kernel_size = 5, padding = 2)
self.conv3 = nn.Conv2d(192, 384, kernel_size = 3, padding = 1)
self.conv4 = nn.Conv2d(384, 256, kernel_size = 3, padding = 1)
self.conv5 = nn.Conv2d(256, 256, kernel_size = 3, padding = 1)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.fc1 = nn.Linear(256 * 6 * 6, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, num_classes)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.maxpool(x)
x = self.relu(self.conv2(x))
x = self.maxpool(x)
x = self.relu(self.conv3(x))
x = self.relu(self.conv4(x))
x = self.relu(self.conv5(x))
x = self.maxpool(x)
x = self.avgpool(x)
x = x.view(x.size(0), 256 * 6 * 6)
# view : 텐서의 차원을 변경해 데이터의 전체 요소 수가 동일하면서 새로운 형태의 텐서를 생성
# 이 경우, 변환의 목적은 일반적으로 특정 네트워크 계층의 입력으로 사용하기 위해 텐서를 적절한 형태로 재구성
# x.size(0) 은 x 텐서의 첫번째 차원의 크기 반환. 이는 일반적으로 배치 사이즈를 의미(즉 처리하고 있는 데이터 샘플의 수)
# 256 * 6 * 6 은 새로운 텐서의 두번째 차원의 크기를 지정
#(256특정 conv 레이어의 출력수, 6 * 6 : 채널들의 각가에 대한 feature map 크기)
# 즉 256 * 6 * 6은 각 데이터 샘플에 대한 특성들을 일렬로 펼친 벡터의 크기
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
return self.fc3(x)
실제 학습시킬 모델
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# Instantiate two convolutional layers
self.conv1 = nn.Conv2d(in_channels=1, out_channels=5, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels=5, out_channels=10, kernel_size=3, padding=1)
# Instantiate the ReLU nonlinearity
self.relu = nn.ReLU(inplace=True)
# Instantiate a max pooling layer
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# Instantiate a fully connected layer
self.fc = nn.Linear(49 * 10, 10)
def forward(self, x):
# Apply conv followed by relu, then in next line pool
x = self.relu(self.conv1(x))
x = self.pool(x)
# Apply conv followed by relu, then in next line pool
x = self.relu(self.conv2(x))
x = self.pool(x)
# Prepare the image for the fully connected layer
x = x.view(-1, 7 * 7 * 10)
# Apply the fully connected layer and return the result
return self.fc(x)
Training CNNs
torchvision 패키지의 MNIST 데이터를 이용해 dataset과 dataloader를 구성하고, 위에서 만든 CNN을 instance화 하고 (net), cross-entropy(criterion) 와 Adam optimizer를 이용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
transform = transform.Compose([
transforms.ToTensor(),
transforms.Normalize((0,1307), (0.3081)) # 평균, 표쥰편차 (normalized_channel - (channel - mean) / std)
# ToTensor() 에서 0 ~ 1로 이미 정규화를 했지만 아래서 다시 하는 이유
# 픽셀 값들의 분포가 여전히 비대칭 적일 수 있으며, 특정 범위에 치우쳐져 있을 수 있다.
# transforms.Normalize((0,1307), (0.3081)) 이런 데이터 분포로 변환해 평균이 0, 표준편차가 1이 되도록 함
# `transforms.ToTensor()`로 변환된 후의 데이터는 0에서 1 사이의 값으로 스케일링되며,
# 이후 `transforms.Normalize()`를 통해 각 픽셀 값에서 평균 `0.1307`을 빼고, 그 결과를 표준편차 `0.3081`로 나누어 정규화
])
trainset = torchvision.datasets.MNIST('MNIST',
train = True,
transform = transform,
download = True)
testset = torchivision.datasets.MNIST('MNIST',
train = False,
transform = transform,
download = True)
train_loader = torch.utils.data.DataLoader(trainset,
batch_size = 1,
shuffle = True,
num_workers = 0) # 데이터를 로드할 때 사용하는 서브프로세스의 수를 지정
test_loader = torch.utils.data.DataLoader(testset,
batch_size = 1,
shuffle = False,
num_workers = 0)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import torch.optim as optim
net = Net()
optimizer = optim.Adam(net.parameters(), lr=3e-4)
criterion = nn.CrossEntropyLoss()
for i, data in enumerate(train_loader, 0): # train_loader를 순회, train_loader의 0번째 인덱스부터
inputs, labels = data
optimizer.zero_grad()
# Compute the forward pass
outputs = net(inputs)
# Compute the loss function
loss = criterion(outputs, labels)
# Compute the gradients
loss.backward()
# Update the weights
optimizer.setp()
Using CNNs to make predictions
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
net.eval()
for i, data in enumerate(test_loader):
image, label = data
output = net(image)
_, predicted = torch.max(output.data, dim = 1)
# 반환값
# 첫번째 값은 각 행에서 찾은 최대값을 담은 텐서
# 두번째 값은 해당 최대값의 인덱스를 담은 텐서(모델이 예측한 클래스)
if predicted == label:
print("Yipes, your net made the right prediction " + str(predicted))
else:
print("Your net prediction was " + str(predicted) + ", but the correct label is: " + str(label))
if i > 10:
break