15. PGGAN 이론 및 구현
1. Introduction
Autoregressive models(ex. PixelCNN), VAEs, GANs 등 많은 생성모델들이 있다. 본 논문은 이 중에서도 GAN의 architecture를 사용한 논문이다.
- Autoregressive models : sharp images, slow to evaluate, no latent space
- VAE : fast to train, blurry images
- GANs: sharp images, low resolution, limited variation, unstable training
GAN
GAN은 서로 경쟁하는 두 네트워크인 generator와 discriminator로 구성되어 있다. generator는 실제 데이터를 모방하는 새로운 데이터를 생성하고, discriminator는 이 데이터가 실제인지 아닌지를 판별한다. 두 네트워크는 지속적으로 서로를 개선시키면서 학습한다. 최종적으로, GAN은 실제와 구별하기 어려운 고품질의 데이터를 생성할 수 있게 된다.
GAN에서는 generator를 잘 학습시키는 것이 중요하다.(discriminator는 학습중에만 사용되고 이후에는 버려진다.)
Challenge
GAN에는 해결해야 할 문제점들이 있다.
- generated distribution과 training distribution들이 겹치는 부분(overlap)이 적다면, 이 분포들간의 거리를 측정할 때 gradient는 random한 방향을 가리킬 수 있다.
- original GAN에서는 Jensen-Shannon Divergence를 distance metric으로 사용했다면, 최근에는 least squares나 Wasserstein distance등의 metric을 사용해서 모델을 안정화 시켰다.
- mode collapse: generated distribution이 실제 데이터의 분포를 모두 커버하지 못하고 다양성을 잃어버리는 현상을 뜻한다. G는 그저 loss만을 줄이려고 학습을 하기 때문에 전체 데이터 분포를 찾지 못하게 되고, 결국에는 하나의 mode에만 강하게 몰리게 되는 경우이다.
- 예를 들어, MNIST에서 G가 특정 숫자만을 생성하게되는 경우가 이게 속한다.
High-resolution의 image를 생성할 수록, 가짜 이미지라고 판별하기 쉬워진다.
- High-resolution의 이미지를 만들기 위해서는 memory constraint 때문에 더 작은 minibatch를 사용해야하고, training stability 역시 떨어진다.
$\star$ 따라서 이러한 문제점들을 해결하기 위해 PGGAN에서는 Generator와 Discriminator를 점진적으로 학습시킨다. 즉, 만들기 쉬운 low-resolution부터 시작하여 새로운 layer를 조금씩 추가하고 higher-resolution의 detail들을 생성한다.
2. Progressive Growing of GANs
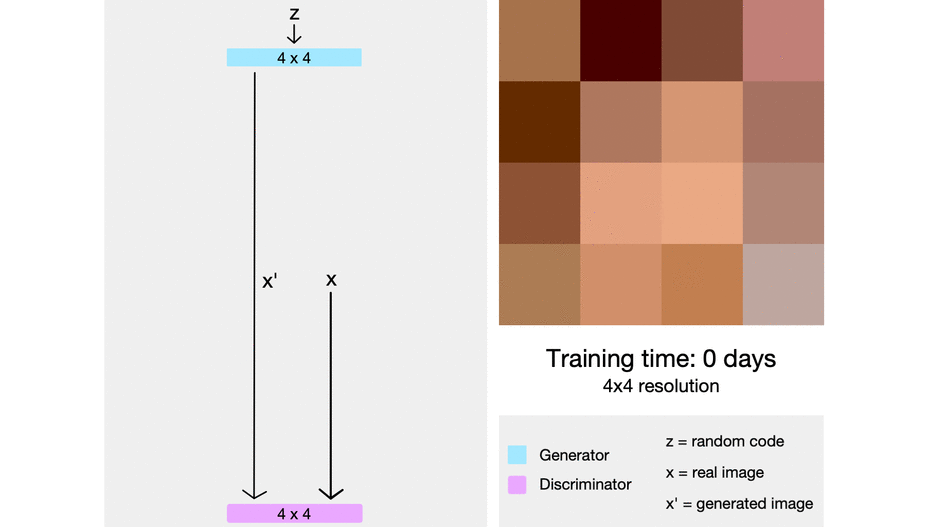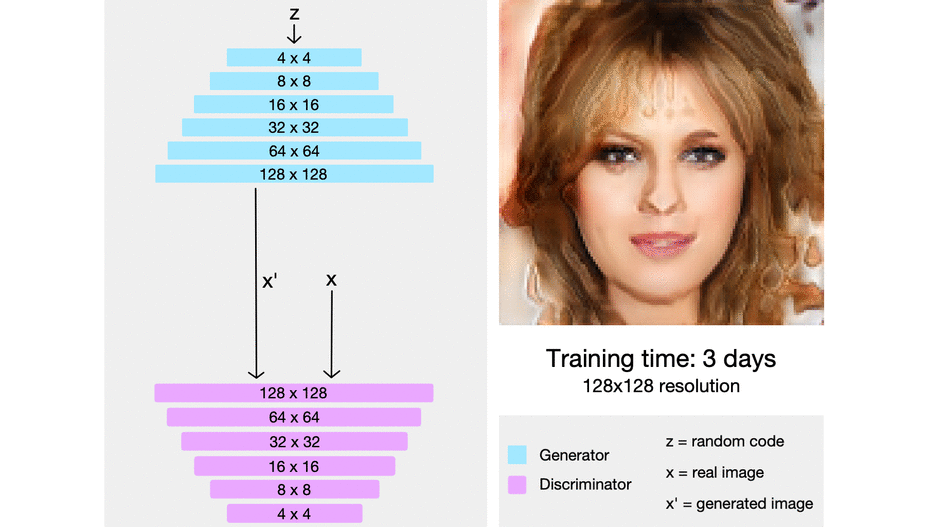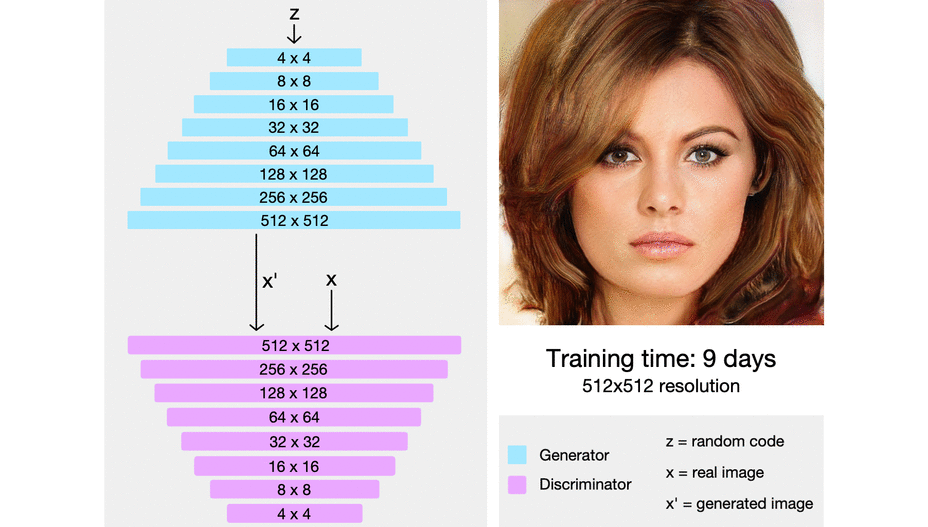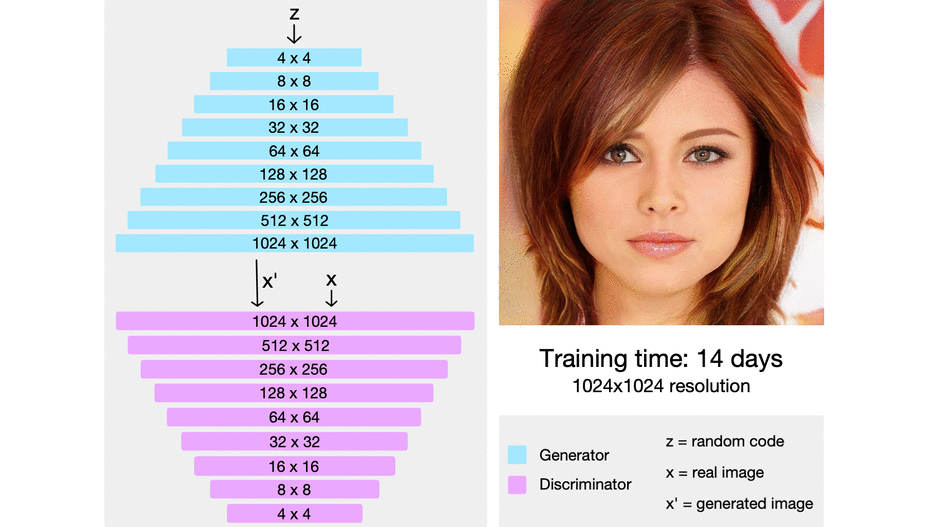 위의 그림처럼 PGGAN은 low-resolution의 image에서 시작하여 점차 layer를 추가하면서 high-resolution을 학습하게 된다. 또한, discriminator는 generator와 대칭의 형태를 이루고 있으며 모든 layer들을 학습할 수 있다.
위의 그림처럼 PGGAN은 low-resolution의 image에서 시작하여 점차 layer를 추가하면서 high-resolution을 학습하게 된다. 또한, discriminator는 generator와 대칭의 형태를 이루고 있으며 모든 layer들을 학습할 수 있다.
처음에는 large scale(low frequency)의 정보들을 학습하고, 점차 fine scale(higher frequency)의 정보들을 학습하게 된다.
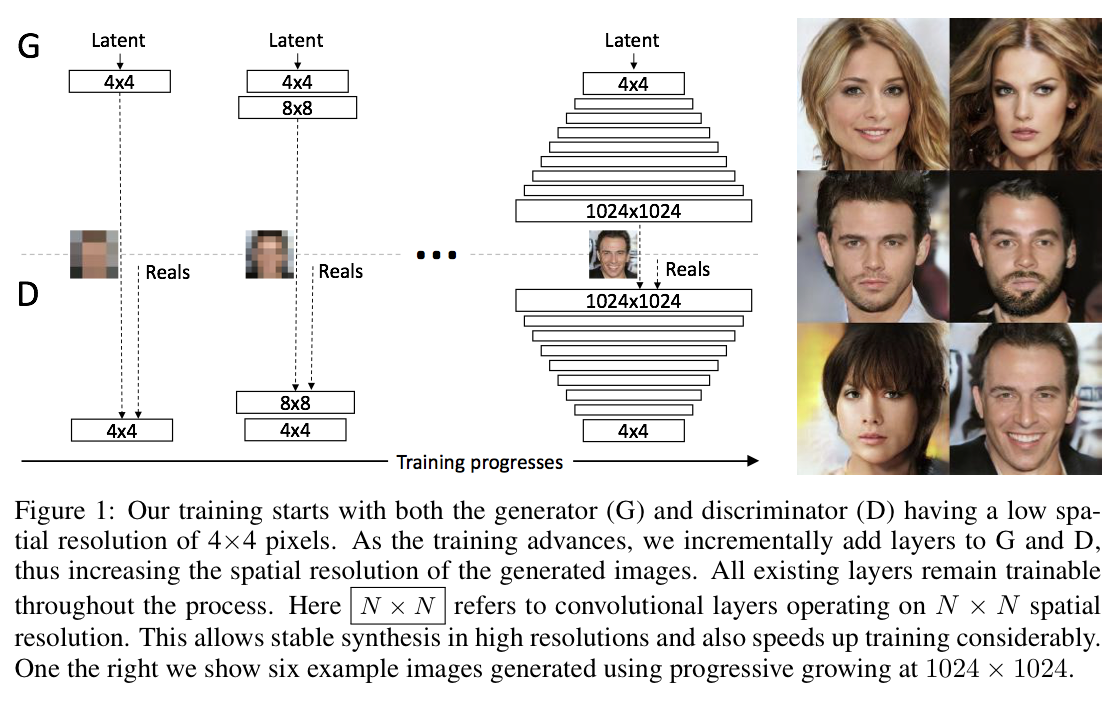 이러한 Progressive training은 몇가지 장점이 있다.
이러한 Progressive training은 몇가지 장점이 있다.
- Stable: low-resolution의 이미지를 학습하면 class information도 적고 mode도 몇없기 때문에 안정적이다.
- Reduced training time: PGGAN은 lower resolution에서부터 비교하여 학습을 하기 때문에 학습속도가 2~6배 빨라진다.
Fading in higher resolution layers
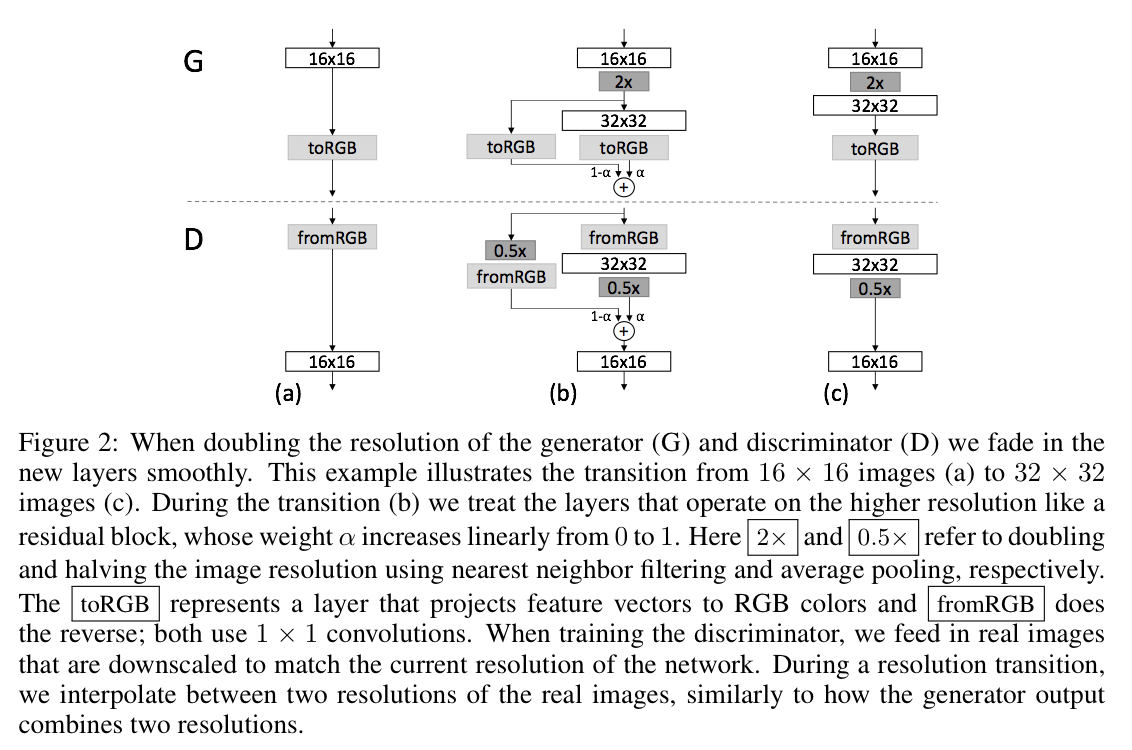
G와 D의 resolution을 upsampling 할 때, PGGAN은 새로운 layer에 fade in 하는 방식을 사용한다.
(a): 이 단계에서는 생성자(G)와 판별자(D)가 16x16 이미지를 처리한다. 생성자는 랜덤 노이즈를 받아 이미지를 생성하고, 판별자는 이 이미지가 실제 이미지인지 아닌지 판별한다. 이미지는
toRGB레이어를 통해 RGB 색상으로 표현되며, 판별자는fromRGB레이어를 통해 RGB 이미지를 피처 벡터로 변환한다.(b): 이 단계는 해상도가 16x16에서 32x32로 증가하는 과정을 나타낸다. 이 때 새로운 레이어들은 점차적으로 부드럽게 페이드인된다. 해상도가 높아진 레이어들은 가중치 $\alpha$ 가 0에서 1로 선형적으로 증가하는 잔차 블록처럼 처리된다. 생성자의 출력은 두 가지 해상도를 결합하고, 판별자의 입력은 실제 이미지의 두 가지 해상도를 보간한다. 이는 훈련 과정 동안 생성자와 판별자가 더 높은 해상도의 이미지를 처리하는 방법을 점차적으로 배울 수 있게 한다.
(c): 이 단계에서는 생성자와 판별자가 32x32 이미지를 처리한다. 이 단계는 (a) 단계와 비슷하지만, 이미지의 해상도가 더 높아진다. 생성자는 이제 더 높은 해상도의 이미지를 생성하고, 판별자는 더 높은 해상도의 이미지를 판별한다.
3. Increasing Variation using Minibatch Standard Deviation
PGGAN에서는 mode collapsing을 해결하기 위한 한가지 방법인 Mini-batch discrimination의 방식을 사용한다. mini-batch 별로 생성이미지와 실제 이미지 사이의 거리 합의 차이를 목적함수에 추가하는 것이다.
- 이 값을 discriminator의 어디에나 추가해도 되지만, 보통은 맨 뒤에 추가하곤 한다
- 이 방식 외에 repelling regularizer를 사용할 수도 있다.
4. Normalization in Generator and Discriminator
GAN에서는 G와 D가 경쟁을 할 때 signal magnitude(신호의 크기)가 커지기 쉽다. 따라서 보통은 batch normalization을 하곤 한다. 그런데 PGGAN에서는 signal magnitude을 할 때 이러한 현상이 나타나지 않기 때문에 parameter를 학습시키기 위한 방식으로 다른 접근 방식을 사용한다.
4.1 Equalized Learning Rate
batch size가 큰 일반 GAN의 경우 batch norm을 사용해도 문제가 없지만, PGGAN에서는 high-resolution의 이미지를 생성해야하기 때문에 작은 사이즈의 batch를 사용하게 되고 그렇기 때문에 initialization이 굉장히 중요해진다.
본 논문에서는 모든 layer의 learning speed가 같도록 equalized learning rate의 방식을 사용한다. gradient의 학습 속도가 parameter와 무관하도록 standard deviation으로 gradient를 normalize하는 방식이다. (weight를 N(0, 1)의 정규 분포에서 initialization한 후, runtime시에 scaling 해준다.)
4.2 Pixelwise Feature Vector Normalization in Generator
D와 G가 경쟁을 하면서 크기가 control이 잘 안되는 경우를 대비하여 PGGAN에서는 convolution layer 후 generator에서 각 pixel 별로 normalization을 해준다.
\[b_{x, y}=a_{x, y} / \sqrt{\frac{1}{N} \sum_{j=0}^{N-1}\left(a_{x, y}^{j}\right)^{2}+\epsilon}\]
5. Experiments


다른 GAN들과 비교했을 때 고해상도 이미지가 잘 출력된다.
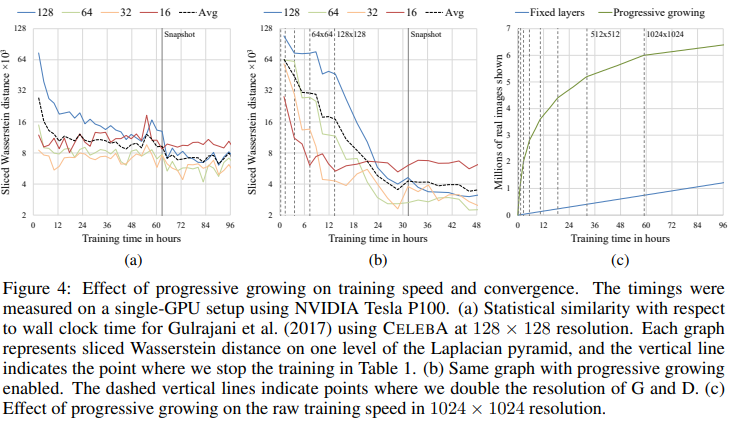
학습속도 역시 매우 빠르다.
PGGAN 핵심 개념
PGGAN (Progressive Growing of GANs)의 핵심은 점진적으로 이미지의 해상도를 높여가며 학습을 진행하는 것이며, 이 과정에서 다양한 기술적 전략들을 사용하여 품질과 학습의 안정성을 개선한다. 여기에는 Loss 함수, 정규화 방법, 그리고 학습률 조정 기술이 포함된다.
정규화 기법과 학습률 조정
- Normalization in Generator and Discriminator:
- PGGAN에서는 주로 Pixelwise Feature Vector Normalization을 생성자에 적용한다. 이 기술은 각 픽셀 위치에서 feature vector의 길이를 정규화함으로써, 네트워크 학습 시 발생할 수 있는 scale 문제를 완화한다. 특히, 이는 생성자에서의 각 레이어의 출력을 통제하여 네트워크의 학습을 안정화하는 데 도움을 준다.
- Equalized Learning Rate:
- 이 기술은 학습률을 각 레이어마다 동등하게 조정하여, 모든 레이어가 동일한 속도로 학습되도록 한다. 구체적으로는 He 초기화 기법을 사용하여 가중치를 초기화한 뒤, 학습 과정에서 가중치의 스케일을 조정함으로써 학습률을 ‘평준화’한다. 이는 학습 초기 단계에서 가중치 값의 폭발이나 소실을 방지하여 모델의 안정성을 높이는 데 기여한다.
- Pixelwise Feature Vector Normalization in Generator:
- 앞서 언급한 바와 같이, 이 정규화 방법은 생성자 내부에서 사용되며, 각 픽셀의 feature vector를 정규화하여 네트워크의 학습 과정을 안정화한다. 이는 특히 각 레이어의 출력이 일정 범위 내에 머물도록 보장하여, 네트워크가 더 빠르고 안정적으로 수렴하도록 돕는다.
PGGAN의 학습 과정은 저해상도에서 시작하여 점진적으로 해상도를 높여가는 방식으로 진행된다. 각 단계에서, 생성자와 판별자는 추가된 레이어를 통해 더 높은 해상도의 이미지를 처리하게 된다. 이 점진적 학습 방법은 모델이 더 안정적으로 학습하고, 더 세밀하고 복잡한 이미지 특징을 효과적으로 포착할 수 있게 한다.
정리
1. Progressive Growing
- 점진적으로 해상도를 높여가며 학습
2. PixelNorm
- 기존에 많이 쓰는 BatchNorm과는 달리 픽셀별로 Normalization 작업 수행
- 각 위치의 픽셀에 대해 모든 채널을 통틀어 정규화를 수행
3. Equalized Learning Rate
- 가중치를 sqrt(2/입력개수) 로 나누어 모든 가중치가 동일한 속도로 학습될 수 있도록 한다.
4. Minibatch Std
- Discriminator의 마지막 블록에 해당 레이어를 추가하여 모드 붕괴 현상을 완화
Progressive Growing
각 resolution으로 데이터셋을 downsampling하여 학습 그 전 resolution에서의 모델 파라미터 상태를 가져와 학습 그리고 좀 더 부드럽게 해상도를 높힐 수 있도록 fade in 레이어를 사용 PGGAN에서는 (b)의 구조를 사용. alpha 값은 학습 도중에 선형적으로 0 to 1 로 증가
Pixel Norm
각 위치의 픽셀에 대해 모든 채널을 통틀어 정규화를 수행. 이미지가 고해상도인만큼 batch_size를 저해상도 이미지만큼 늘리기가 어렵다. \(b_{x, y}= {a_{x, y} \over \sqrt{\frac{1}{N} \sum_{j=0}^{N-1}\left(a_{x, y}^{j}\right)^{2}+\epsilon}}\)
N은 FeatureMap의 갯수. a는 원본 벡터, b는 정규화된 벡터 이는 활성화 값이 폭주하는 것을 막는다.
Equalized Learning Rate
모든 가중치를 평균이 0이고 표준편차가 1인 정규분포로 초기화한다. 그 후에 각 층이 실행될 때마다 가중치를 sqrt(2/입력개수)로 나눈다. (입력개수 = k * k * c) RMSProp, Adam등의 옵티마이저를 사용했을 때 이 기법이 GAN의 성능을 크게 향상한다는 것을 논문에서 입증하였다. 이로서 모든 가중치가 동일한 속도로 학습될 수 있도록 도와준다.
Minibatch Standard Deviation
이 레이어는 Discriminator의 마지막 블록에서만 사용되고, 모드 붕괴 현상을 막기 위해 사용된 기법 minibatch의 표준편차의 평균을 입력 마지막 층에 추가
만약 생성이미지의 다양성이 부족하다면, 판별자의 특성맵 간의 표준편차는 적을 것이다. 통계적 수치를 마지막 층에 추가해줌으로써, 판별자가 통계적 수치를 사용할 수 있도록 하고 다양성이 부족한 생성이미지에 속지 않도록 도와준다. (데이터셋 이미지의 다양성이 충분하다면, 진짜 이미지와 가짜 이미지를 구별할 때 이런 통계적 수치를 사용할 수 있기 때문. 가짜이미지가 진짜같더라도 다양성이 부족하다면 판별자의 마지막 층을 통해 구별)
프로그레시브 GAN의 단계별 학습과 메모리 관리
프로그레시브 GAN (Generative Adversarial Network)의 학습 방법은 저해상도에서 시작하여 점진적으로 해상도를 높여가며 학습하는 방식이다. 이 과정에서 파이썬과 PyTorch의 객체 및 메모리 관리 기능이 중요한 역할을 한다. 본 문서에서는 이러한 프로세스가 어떻게 이루어지는지에 대해 자세히 설명한다.
파이썬에서의 객체 및 메모리 관리
파이썬은 객체 지향 프로그래밍 언어로, 데이터와 함수를 하나의 개체인 객체로 캡슐화한다. 객체가 생성될 때마다 파이썬 인터프리터는 해당 객체를 메모리에 할당하고, 이 객체는 고유한 식별자(ID)를 통해 참조된다. 객체에 대한 모든 참조가 제거되면, 파이썬의 가비지 컬렉터가 자동으로 메모리를 회수하여 효율적인 메모리 관리를 돕는다.
예시: 객체 참조
1
2
3
4
5
6
class Dog:
def __init__(self, name):
self.name = name
dog1 = Dog('Buddy')
dog2 = dog1 # dog2는 dog1과 같은 객체를 참조합니다.
위 예시에서 dog1과 dog2는 메모리상 동일한 Dog 객체를 참조한다. 따라서, dog1의 이름을 변경하면 dog2를 통해서도 변경된 이름을 확인할 수 있다.
PyTorch에서의 모듈 및 가중치 관리
PyTorch는 딥러닝 모델을 구성하는 레이어(layer)와 모듈(module)을 정의할 때 사용되는 프레임워크이다. nn.Module 클래스는 모든 신경망 모듈의 기본 클래스로, 여러 레이어를 하나의 모듈로 그룹화하여 관리할 수 있게 한다. 이 클래스는 내부적으로 모듈의 파라미터(가중치)를 추적하며, 이를 통해 학습, 저장, 불러오기 등의 작업을 간편하게 수행할 수 있다.
예시: 모듈 정의
1
2
3
4
5
6
7
8
9
10
11
12
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 40, 5)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
위 예시에서 SimpleNet은 두 개의 컨볼루션 레이어를 포함하는 간단한 신경망 모델다 nn.Module을 상속받아 정의되며, 이를 통해 PyTorch는 conv1과 conv2의 가중치를 자동으로 관리한다.
프로그레시브 GAN에서의 단계별 학습
프로그레시브 GAN의 핵심 아이디어는 모델이 저해상도에서 시작하여 점진적으로 더 높은 해상도의 이미지를 생성할 수 있도록 학습하는 것이다. 이 과정에서 초기 단계의 레이어들은 학습이 진행됨에 따라 유지되며, 새로운 레이어는 점진적으로 모델에 추가된다.
예시: 단계별 레이어 추가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class ProgressiveGAN(nn.Module):
def __init__(self):
super(ProgressiveGAN, self).__init__()
self.steps = 0
self.init_layer = nn.Conv2d(1, 16, 3)
self.layers = nn.ModuleList([self.init_layer])
def add_layer(self, new_layer):
self.steps += 1
self.layers.append(new_layer)
def forward(self, x):
for step, layer in enumerate(self.layers):
x = layer(x)
return
# ProgressiveGAN 인스턴스 생성
model = ProgressiveGAN()
# 초기 상태에서 모델에 레이어 추가
new_layer = nn.Conv2d(16, 32, 3) # 예시로 새 컨볼루션 레이어 생성
model.add_layer(new_layer) # 새 레이어를 모델에 추가
# 또 다른 레이어 추가
another_layer = nn.Conv2d(32, 64, 3)
model.add_layer(another_layer)
# 이런 식으로 모델에 레이어를 추가하면서 점진적으로 모델을 확장할 수 있다.
위 예시에서 ProgressiveGAN은 초기에 하나의 컨볼루션 레이어로 시작한다. add_layer 메소드를 통해 새로운 레이어를 추가할 때마다, 이전 레이어들은 그대로 유지되며 새 레이어만 추가된다. 이는 PyTorch의 nn.ModuleList를 사용하여 구현되며, 각 단계별로 학습된 가중치는 저장되고 재사용된다.
이와 같이 파이썬과 PyTorch의 메모리 및 객체 관리 메커니즘이 프로그레시브 GAN에서 단계별로 학습된 레이어들의 가중치를 유지하고 새로운 레이어를 효과적으로 추가할 수 있게 한다. 이는 복잡한 모델을 점진적으로 학습하면서도 효율적인 메모리 사용을 가능하게 하는 중요한 특징이다.
구현
https://github.com/aladdinpersson/Machine-Learning-Collection/blob/master/ML/Pytorch/GANs/ProGAN/model.py
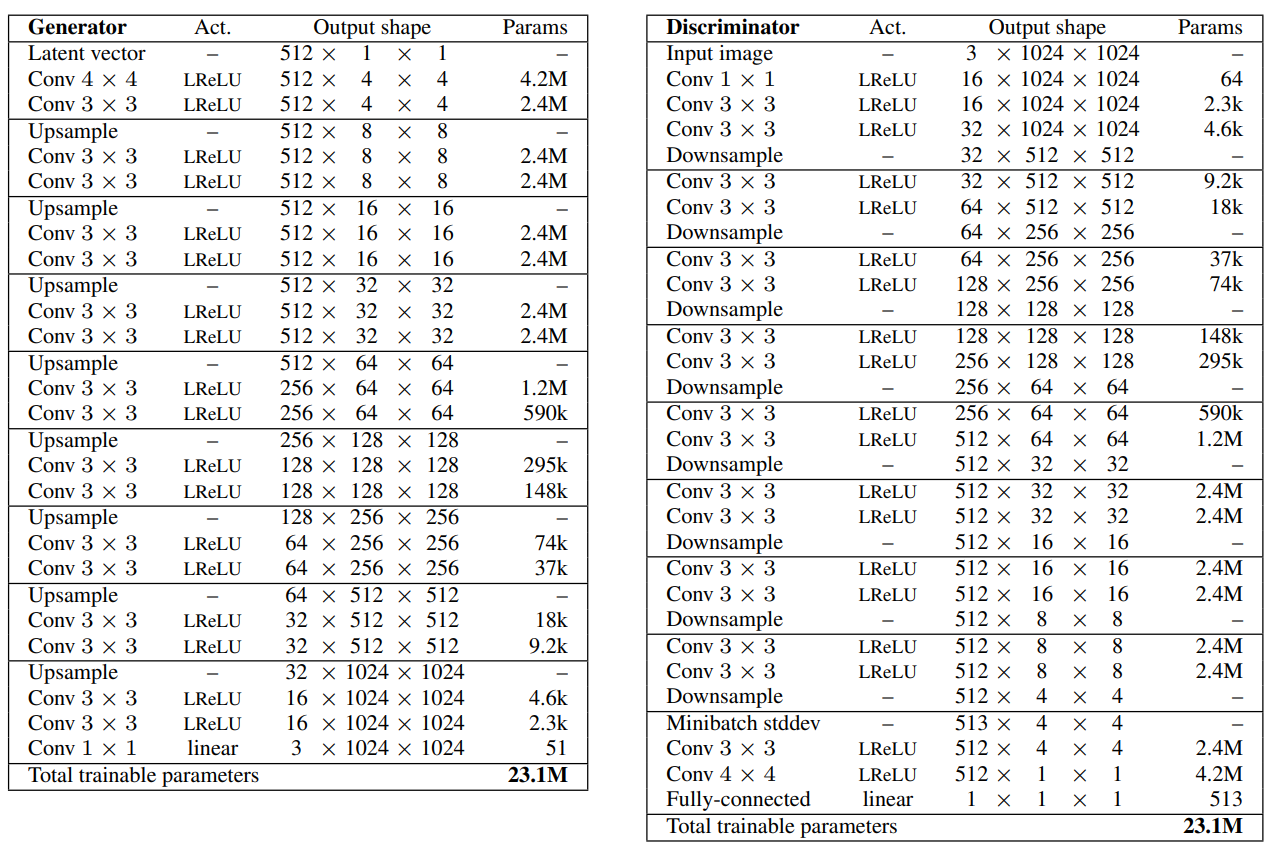 Generator n_channels: [512, 512, 512, 512, 256, 128, 64, 32, 16] 순으로 사용
Generator n_channels: [512, 512, 512, 512, 256, 128, 64, 32, 16] 순으로 사용
WSConv2d(Weight-Scaled Convolution 2D) 클래스는 Progressive GAN(ProGAN) 구현에서 중요한 역할을 하는 컴포넌트 중 하나이다. 이 클래스는 가중치 스케일링된 2D 컨볼루션 레이어를 구현하며, Equalized Learning Rate 기법을 적용해 학습 과정을 안정화하고 개선한다.
팬인(Fan-in) 수
팬인(fan-in) 수는 신경망에서 특정 뉴런으로 입력되는 연결의 총 수를 의미한다. 더 구체적으로는, 한 레이어의 뉴런이 이전 레이어로부터 받는 입력 신호의 수 이다. 예를 들어, 컨볼루션 레이어에서 팬인 수는 입력 채널의 수에 컨볼루션 필터(커널)의 크기를 곱한 값으로 계산한다. 즉, 팬인 수 = 입력 채널 수 * 커널 너비 * 커널 높이 이다. 팬인 수는 가중치 초기화 방법을 결정할 때 중요한 요소 중 하나이다.
He 초기화(He Initialization)
He 초기화는 깊은 신경망에서 ReLU(또는 ReLU 변형) 활성화 함수를 사용할 때 선호되는 가중치 초기화 방법이다. 이 초기화 방법은 신경망의 각 레이어에서 가중치를 초기화할 때, 그 레이어의 팬인 수를 기반으로 가중치의 분산을 설정한다.
He 초기화 공식:
\[\text{Var}(W) = \frac{2}{\text{팬인 수}}\]$\text{Var}(W)$ 는 가중치 $W$ 의 분산. 이 공식을 통해 초기화된 가중치는 레이어를 통과하는 신호의 분산을 유지하도록 도와주어, 깊은 네트워크에서도 각 레이어를 통과하는 신호가 소멸하거나 폭발하는 것을 방지한다.
He 초기화의 중요성
- 신호 소멸/폭발 문제 방지: 깊은 신경망에서는 신호가 네트워크를 통과하면서 점점 약해지거나 너무 강해질 수 있다. He 초기화는 이러한 문제를 방지하도록 설계되었다.
- 학습 속도 향상: 초기 가중치가 적절히 설정되면, 네트워크는 학습을 시작할 때부터 더 안정된 상태에 있게 되며, 이는 종종 학습 속도를 향상시킨다.
- 깊은 네트워크에서의 효율적 학습: He 초기화는 특히 ReLU 활성화 함수와 함께 사용될 때, 깊은 네트워크에서 효과적인 학습을 가능하게 한다.
He 초기화 방법은 깊은 합성곱 신경망(CNN)과 같은 복잡한 아키텍처에서 매우 유용하며, 깊은 신경망의 성공적인 학습에 중요한 기여를 한다.
WSConv2d 클래스에서 사용된 self.scale 계산 공식은 가중치 스케일링을 위해 설계된 특수한 형태로 이 공식은 표준 편차 공식과 직접적인 연관이 있다. He 초기화는 깊은 네트워크에서 ReLU 활성화 함수와 함께 사용될 때 효과적인 가중치 초기화 방법 중 하나로 알려져 있다.
WSConv2d에서의 스케일링 공식:
여기서,
gain은 초기화에 사용되는 이득(gain)으로, ReLU 함수와 같은 비선형 활성화 함수에 따라 조정될 수 있다. 일반적으로 ReLU의 경우 2 권장n은 가중치 행렬의 팬인(fan-in) 수, 즉 입력 채널 수에 커널 크기의 제곱을 곱한 값. (in_channels * (kernel_size ** 2))
스케일링 계산의 이유
- 균일한 학습 속도: 각 레이어의 가중치가 스케일링되면, 학습 과정 중 가중치 업데이트의 크기가 레이어마다 균등해집니다. 이는 모델이 더 안정적으로 학습되도록 하며, 특히 깊은 네트워크에서 중요.
- 과적합 방지: 균등한 학습 속도는 네트워크의 일부 레이어가 다른 레이어보다 빠르게 학습되어 과적합되는 것을 방지.
- 학습의 안정성: 초기 가중치의 적절한 스케일링은 학습 초기 단계에서의 안정성을 높이고, 학습 과정 전반에 걸쳐 더 나은 수렴을 달성할 수 있도록 돕는다
가중치 스케일링 (Equalized Learning Rate)
self.scale = (gain / (in_channels * (kernel_size ** 2))) ** 0.5
가중치 스케일링 계수(self.scale)을 계산한다. 이 계수는 He초기화 방법에서 사용되는 gain, 입력 채널 수(‘in_channels’), 그리고 커널 크기(‘kernel_size’)를 기반으로 한다. 특히, 컨볼루션 레이어의 가중치를 초기화할 때 이용되는 표준 편차와 유사한 방식으로 계산되며, 이는 Equalized Learning Rate를 구현하는 데 핵심적인 역할을 한다. Equalized Learning Rate는 학습 도중 각 레이어의 학습 속도를 동일하게 조정함으로써 학습 과정의 안정성을 개선하는 기법이다.
return self.conv(x * self.scale) + self.bias.view(1, self.bias.shape[0], 1, 1)
이 라인은 실제로 입력 x에 self.scale을 곱한 후, 정의된 컨볼루션 연산(self.conv)을 적용한다. 이 과정은 입력에 대한 가중치의 스케일링을 통해 Equalized Learning Rate의 효과를 실현한다. 이후, 별도로 저장된 bias(self.bias)를 추가하기 전에, bias의 형태를 적절히 조정한다. view(1, self.bias.shape[0], 1, 1)는 bias를 컨볼루션 연산의 결과와 맞는 형태로 변환해 각 출력 채널에 대해 적절한 bias를 더하도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import torch
import torch.nn as nn
import torch.nn.functional as F
from math import log2
# factors는 Discriminator와 Generator에서 각 레이어에 대해 채널이 얼마나 곱해지고 확장되어야 하는지를 결정하는데 사용
# 구체적으로는 처음 5개 레이어에서는 채널 수가 동일하게 유지되고, img_size를 증가시키면서(후반 레이어로 가면서) 채널 수를 1/2, 1/4 등으로 감소
factors = [1, 1, 1, 1, 1 / 2, 1 / 4, 1 / 8, 1 / 16, 1 / 32]
class WSConv2d(nn.Module):
"""
가중치 스케일링된 Conv2d (Equalized Learning Rate)
입력을 변경하는 대신 입력을 곱하는 방식을 사용하며,
이는 가중치를 변경하는 것과 같은 결과를 가져온다.
"""
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, gain=2):
super(WSConv2d, self).__init__()
# Convolutional Layer를 정의
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# 스케일. 이는 Equalized Learning Rate를 적용하기 위함.
self.scale = (gain / (in_channels * (kernel_size ** 2))) ** 0.5
# bias를 따로 저장하고, conv 레이어에서는 bias를 사용하지 않도록 설정.
self.bias = self.conv.bias
self.conv.bias = None
# conv 레이어를 초기화.
nn.init.normal_(self.conv.weight)
nn.init.zeros_(self.bias)
def forward(self, x):
# 입력 x에 scale을 곱하고 convolution 연산을 수행한 후, bias를 더한다.
return self.conv(x * self.scale) + self.bias.view(1, self.bias.shape[0], 1, 1)
WSConv2d는 가중치를 직접 변경하지 않고 입력 데이터에 스케일링 계수를 곱해 Equalized Learning Rate를 구현한다.
PixelNorm
픽셀 정규화(Pixel Normalization) 구현. 각 필셀을 그 픽셀의 벡터 크기로 나눠 feature map 내의 각 픽셀 간의 스케일을 정규화하는 기법이다.
1
2
3
4
5
6
7
8
9
10
11
class PixelNorm(nn.Module):
def __init__(self):
super().__init__()
self.epsilon = 1e-8 # 아주 작은 값으로 나누기 연산의 안정성을 보장하기 위한 epsilon 값
def forward(self, x):
# x: 입력 데이터. (batch_size, C, H, W)로, 배치 크기, 채널 수, 높이, 너비
out = x / torch.sqrt(torch.mean(x ** 2, dim=1, keepdim=True) + self.epsilon)
# torch.mean(x ** 2, dim=1, keepdim=True) + self.epsilon에서는 입력 x의 제곱에 대한 평균을 채널 차원(dim=1)을 따라 계산하고,
# keepdim=True로 차원을 유지. 이를 통해 각 픽셀의 벡터 크기를 계산하고, epsilon을 더해 나누기 연산 시 0으로 나누는 것을 방지.
return out
유클리드 노름은 벡터의 크기나 길이를 측정하는 방법으로, PixelNorm 클래스 엔서는 벡터의 크기를 측정하기 위해 사용 벡터 $\mathbf{v} = (v_1, v_2, …, v_n)$에 대한 유클리드 노름(2-노름) 공식: $|v|_2 = \sqrt{v_1^2 + v_2^2 + … + v_n^2}$
UpDownSampling
주어진 배율(size)에 따라 이미지 크기를 늘리거나 줄인다. 이 모듈은 이미지 해상도를 점진적으로 증가시킬 때 사용
1
2
3
4
5
6
7
8
9
10
11
class UpSampling(nn.Module):
def __init__(self, size):
super().__init__()
self.size = size # 이미지의 크기를 조정할 배율
def forward(self, x):
# x: 입력 데이터. (batch_size, C, H, W)
out = F.interpolate(x, scale_factor=self.size, mode="nearest")
# F.interpolate 함수를 사용하여 입력 x의 크기를 조정. scale_factor=self.size로 크기 조정 배율을 지정하고,
# mode="nearest"는 가장 가까운 이웃 보간법을 사용하여 크기를 조정하는 방식.
return out
GeneratorConvBlock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
class GeneratorConvBlock(nn.Module):
def __init__(self, step, scale_size):
super().__init__()
# 업샘플링 모듈 초기화. 이는 이미지의 해상도를 증가시키는 데 사용
self.up_sampling = UpDownSampling(size=scale_size)
# 첫 번째 컨볼루션 레이어:
# 이전 단계의 출력 채널 수를 현재 단계의 입력 채널 수로 사용.
# 이를 통해 네트워크가 점진적으로 성장할 때마다 채널 수를 적절히 조정할 수 있다.
# 예를 들어, step=1일 때, channel_list[0]은 이전 단계(초기 단계)의 채널 수를 의미하고,
# channel_list[1]은 현재 단계의 목표 채널 수를 나타낸다.
self.conv1 = WSConv2d(in_channels=channel_list[step-1], out_channels=channel_list[step], kernel_size=3, stride=1, padding=1)
# 두 번째 컨볼루션 레이어:
# 첫 번째 컨볼루션 레이어의 출력 채널 수(=현재 단계의 채널 수)를 유지한다.
# 이 레이어는 추가적인 특성 추출을 위해 적용된다.
self.conv2 = WSConv2d(in_channels=channel_list[step], out_channels=channel_list[step], kernel_size=3, stride=1, padding=1)
# 비선형 활성화 함수와 픽셀 정규화 적용
self.leakyrelu = nn.LeakyReLU(0.2)
self.pn = PixelNorm()
def forward(self, x):
# 입력 이미지의 해상도를 업샘플링
scaled = self.up_sampling(x)
# 업샘플링된 이미지를 첫 번째 컨볼루션 레이어에 통과시킨 후,
# LeakyReLU 활성화 함수와 픽셀 정규화 적용
out = self.conv1(scaled)
out = self.leakyrelu(out)
out = self.pn(out)
# 두 번째 컨볼루션 레이어를 통과시킨 후, 동일하게 LeakyReLU 활성화 함수와
# 픽셀 정규화 적용하여 최종 출력 생성
out = self.conv2(out)
out = self.leakyrelu(out)
out = self.pn(out)
return out # 최종 출력 반환
Generator
Generator 클래스의 목적은 점차적으로 해상도를 증가시키면서 고해상도 이미지를 생성하는 것이다. 생성자는 초기 단계에서부터 시작하여, 주어진 steps에 따라 점차 복잡도를 높여간다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
class Generator(nn.Module):
def __init__(self, steps):
super().__init__()
self.steps = steps # 생성자가 진행할 전체 단계 수
# 초기 블록: z 벡터(잠재 공간 벡터)에서 첫 번째 피처 맵을 생성
self.init = nn.Sequential(
PixelNorm(), # 픽셀 정규화 적용
# 첫 번째 피처 맵 생성: 잠재 벡터에서 초기 해상도(예: 4x4)의 피처 맵으로 변환
nn.ConvTranspose2d(in_channels=channel_list[0], out_channels=channel_list[0], kernel_size=4, stride=1, padding=0),
nn.LeakyReLU(0.2), # 비선형 활성화 함수
# 추가 컨볼루션 레이어로 피처 맵의 품질 개선
WSConv2d(in_channels=channel_list[0], out_channels=channel_list[0], kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.2),
PixelNorm() # 다시 픽셀 정규화 적용
)
# 첫 번째 RGB 변환 레이어: 초기 피처 맵을 RGB 이미지로 변환
self.init_torgb = WSConv2d(in_channels=channel_list[0], out_channels=3, kernel_size=1, stride=1, padding=0)
# 생성자의 점진적 성장을 위한 모듈 리스트 초기화
self.prog_blocks = nn.ModuleList([self.init]) # 모든 생성 블록을 저장
self.torgb_layers = nn.ModuleList([self.init_torgb]) # 각 단계의 피처 맵을 RGB 이미지로 변환하는 레이어
# 추가 단계의 생성 블록과 RGB 변환 레이어 추가
for step in range(1, self.steps+1):
self.prog_blocks.append(GeneratorConvBlock(step, scale_size=2)) # 새로운 생성 블록 추가
# 새로운 RGB 변환 레이어 추가
self.torgb_layers.append(WSConv2d(in_channels=channel_list[step], out_channels=3, kernel_size=1, stride=1, padding=0))
# 알파 값에 따라 이전 단계의 이미지와 새로 생성된 이미지를 혼합
def fade_in(self, alpha, upsampling, generated):
# alpha: 현재 단계와 이전 단계 사이의 이미지를 혼합하는 비율
return alpha * generated + (1 - alpha) * upsampling
# 입력 잠재 벡터(x)를 받아 최종 이미지 생성
def forward(self, x, alpha):
out = self.prog_blocks[0](x) # 초기 생성 블록을 통한 처리
if self.steps == 0: # 단 하나의 단계만 있는 경우, 바로 RGB 이미지로 변환
return self.torgb_layers[0](out)
# 점진적 성장을 통한 추가 단계 처리
for step in range(1, self.steps+1):
out = self.prog_blocks[step](out) # 현재 단계의 생성 블록을 통한 처리
# 이전 단계의 이미지와 현재 단계의 이미지를 혼합
upsampling = self.torgb_layers[step-1](self.prog_blocks[step].scaled) # 이전 단계의 이미지
generated = self.torgb_layers[step](out) # 현재 단계의 이미지
# 혼합된 이미지 반환
return self.fade_in(alpha, upsampling, generated)
- 초기 단계: 생성자는 잠재 벡터
x를 받아, 초기 블록(self.init)을 통해 4x4 해상도의 피처 맵을 생성. 이 피처 맵은 첫 번째torgb레이어를 통해 RGB 이미지로 변환
- 점진적 성장: 해상도를 8x8, 16x16으로 증가시키면서, 각 단계에서 새로운
GeneratorConvBlock과torgb레이어를 추가. 이 과정에서,alpha값을 사용하여 이전 단계의 이미지와 새로운 단계의 이미지를 점진적으로 혼합. 이렇게 하여 사용자는 네트워크가 해상도를 점차 증가시키는 과정에서 부드러운 전환을 경험할 수 있다.
- 이미지 생성: 최종 단계에서, 생성자는 현재 단계의
torgb레이어를 통해 생성된 이미지와 이전 단계의 이미지를fade_in함수를 사용하여 혼합한 후, 최종 이미지를 출력.
DiscriminatorConvBlock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class DiscriminatorConvBlock(nn.Module):
def __init__(self, step):
super().__init__()
# 첫 번째 컨볼루션 레이어: 현재 단계의 채널 수를 유지하며 특성 추출
# 이 레이어는 입력 이미지의 특성을 더 세밀하게 분석하기 위해 사용.
self.conv1 = WSConv2d(in_channels=channel_list[step], out_channels=channel_list[step], kernel_size=3, stride=1, padding=1)
# 두 번째 컨볼루션 레이어: 채널 수를 줄임 (C_step -> C_(step-1))
# 이 레이어는 특성 맵의 차원을 줄여 다음 단계로 넘어가기 쉽게 만들어 줌
self.conv2 = WSConv2d(in_channels=channel_list[step], out_channels=channel_list[step-1], kernel_size=3, stride=1, padding=1)
# 다운샘플링: 해상도를 절반으로 줄임 (H, W -> H/2, W/2)
# 이 과정은 이미지에서 더 큰 영역의 특성을 추출할 수 있게 하며, 계산 효율성을 높힘
self.downsample = nn.AvgPool2d(kernel_size=2, stride=2, padding=0)
# 비선형 활성화 함수: LeakyReLU
# LeakyReLU는 일반적인 ReLU와 달리 음수 입력에 대해서도 작은 기울기를 허용하여,
# 정보 손실을 줄이고 모델의 학습 능력을 개선.
self.leakyrelu = nn.LeakyReLU(0.2)
def forward(self, x):
# 첫 번째 컨볼루션 레이어를 통과
out = self.conv1(x)
out = self.leakyrelu(out) # 활성화 함수 적용
# 두 번째 컨볼루션 레이어를 통과
out = self.conv2(out)
out = self.leakyrelu(out) # 활성화 함수 적용
# 이미지 해상도를 줄이는 다운샘플링 적용
out = self.downsample(out)
return out # 처리된 특성 맵 반환
- 채널 수 변화: 이 블록은 두 개의 컨볼루션 레이어를 사용하여 특성을 추출. 첫 번째 레이어(
conv1)는 입력된 특성 맵의 채널 수를 유지하지만, 두 번째 레이어(conv2)는 채널 수를 줄여 (C_step에서C_(step-1)로) 다음 단계의 입력으로 사용될 수 있는 더 작은 차원의 특성 맵을 생성.
- 다운샘플링의 역할:
downsample은AvgPool2d를 사용하여 입력 이미지의 해상도를 절반으로 줄인다. 이는 판별자가 이미지의 전반적인 구조와 패턴을 더 넓은 시야에서 파악하게 하고, 네트워크의 계산 부담을 줄이는 데 도움이 된다.
- 활성화 함수:
LeakyReLU활성화 함수는 각 컨볼루션 레이어 후에 적용된다. 이는 모델이 비선형 문제를 더 잘 해결할 수 있도록 하며, 음수 값에 대해 작은 기울기를 허용함으로써, 판별자가 더 다양한 특성을 학습할 수 있게 한다.
이 구성은 판별자가 이미지를 점차적으로 분석하면서, 실제와 가짜 이미지 사이의 구별을 더 잘 학습할 수 있도록 설계되었다.
Discriminator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
class Discriminator(nn.Module):
def __init__(self, steps):
super().__init__()
self.prog_blocks = nn.ModuleList([]) # 판별자의 컨볼루션 블록을 저장하는 리스트
self.fromrgb_layers = nn.ModuleList([]) # RGB 이미지를 첫 번째 피처 맵으로 변환하는 레이어
self.leakyrelu = nn.LeakyReLU(0.2) # 비선형 활성화 함수
self.steps = steps # 판별자가 처리할 이미지의 최대 해상도 단계
# 각 단계에 대한 컨볼루션 블록과 fromrgb 레이어 추가
for step in range(steps, 0, -1):
self.prog_blocks.append(DiscriminatorConvBlock(step))
self.fromrgb_layers.append(WSConv2d(in_channels=3, out_channels=channel_list[step], kernel_size=1, stride=1, padding=0))
# 최종 블록 추가
self.fromrgb_layers.append(
WSConv2d(in_channels=3, out_channels=channel_list[0], kernel_size=1, stride=1, padding=0)
)
# 마지막 컨볼루션 블록에는 미니배치 표준편차, 컨볼루션 레이어, 비선형 활성화 함수, 최종 출력 레이어를 포함
self.prog_blocks.append(
nn.Sequential(
MinibatchStd(), # 미니배치 표준편차를 추가하여 다양성을 증가
WSConv2d(in_channels=channel_list[0]+1, out_channels=channel_list[0], kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.2),
WSConv2d(in_channels=channel_list[0], out_channels=channel_list[0], kernel_size=4, stride=1, padding=0),
nn.LeakyReLU(0.2),
WSConv2d(in_channels=channel_list[0], out_channels=1, kernel_size=1, stride=1, padding=0),
nn.Sigmoid() # 이미지가 실제일 확률을 출력
)
)
self.avgpool = nn.AvgPool2d(kernel_size=2, stride=2) # 이미지 해상도를 절반으로 줄이는 평균 풀링
def fade_in(self, alpha, downscaled, out):
# 이전 단계의 이미지와 현재 단계의 이미지를 alpha 값에 따라 혼합
return alpha * out + (1 - alpha) * downscaled
def forward(self, x, alpha):
# 첫 번째 fromrgb 레이어를 통해 RGB 이미지를 피처 맵으로 변환
out = self.leakyrelu(self.fromrgb_layers[0](x))
if self.steps == 0: # 이미지 크기가 4x4인 경우, 바로 최종 블록 처리
out = self.prog_blocks[-1](out)
return out.view(out.size(0), -1) # 배치 크기별로 결과 반환
# 현재 단계와 이전 단계의 이미지를 혼합
downscaled = self.leakyrelu(self.fromrgb_layers[1](self.avgpool(x)))
out = self.prog_blocks[0](out)
out = self.fade_in(alpha, downscaled, out)
# 추가 단계의 컨볼루션 블록을 통해 이미지 처리
for i in range(1, self.steps+1):
out = self.prog_blocks[i](out)
return out.view(out.size(0), -1) # 최종 결과 반환
- RGB 이미지 처리:
fromrgb_layers리스트에 저장된 각 레이어는 다양한 해상도의 RGB 이미지를 해당 해상도의 첫 번째 피처 맵으로 변환합니다. 이는 판별자가 다양한 해상도의 이미지를 처리할 수 있게 한다.
- 다운스케일링과 혼합: 이미지의 해상도가 점차 줄어들면서,
fade_in함수는 이전 단계와 현재 단계 사이의 부드러운 전환을 만들기 위해 두 이미지를 혼합합니다.alpha값은 이 혼합에서 현재 단계의 이미지가 차지하는 비율을 결정한다.
- 미니배치 표준편차:
MinibatchStd는 판별자에게 배치 내의 이미지들 사이의 다양성에 대한 정보를 제공합니다. 이를 통해 판별자가 생성된 이미지들 사이의 미묘한 차이를 더 잘 감지할 수 있게 돕는다.
- 해상도 절반으로 줄이기:
avgpool은 이미지 해상도를 절반으로 줄이는 데 사용됩니다. 이는 판별자가 이미지를 점차적으로 분석하면서 더 넓은 영역의 특성을 파악할 수 있도록 한다.
Train
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.utils.data import DataLoader
from utils import merge_test_pred
import gc
from models import Generator, Discriminator
# 각 해상도 단계별로 데이터셋과 모델 상태 딕셔너리가 저장될 경로를 정의합니다.
resolution_list = ["4x4", "8x8", "16x16", "32x32", "64x64", "128x128", "256x256"]
dataset_path = [f"./dataset/{i}" for i in resolution_list]
model_state_dict_path = [f"./model_state_dict/{i}" for i in resolution_list]
class Trainer():
def __init__(self, steps: int, batch_size: int, device: torch.device, test_size: int):
self.steps = steps # 학습할 해상도 단계
self.batch_size = batch_size # 배치 크기
self.device = device # 학습에 사용할 디바이스 (CPU 또는 GPU)
self.test_size = test_size # 테스트 이미지의 수
# 학습 및 검증 데이터셋 로드
directory_path = dataset_path[self.steps]
self.trainloader = DataLoader(torch.cat((torch.load(f"{directory_path}/train_cat.pt"), torch.load(f"{directory_path}/train_dog.pt")), dim=0).type(torch.float32), batch_size=self.batch_size, shuffle=True)
self.validloader = DataLoader(torch.cat((torch.load(f"{directory_path}/valid_cat.pt"), torch.load(f"{directory_path}/valid_dog.pt")), dim=0).type(torch.float32), batch_size=self.batch_size, shuffle=True)
# 생성자 및 판별자 모델 초기화 및 디바이스 할당
self.generator = Generator(steps=self.steps).to(self.device)
self.discriminator = Discriminator(steps=self.steps).to(self.device)
# 손실 함수 및 최적화 알고리즘 설정
self.criterion = nn.BCELoss()
self.generator_optim = Adam(self.generator.parameters(), lr=0.002, betas=(0.5, 0.999))
self.discriminator_optim = Adam(self.discriminator.parameters(), lr=0.002, betas=(0.5, 0.999))
# 테스트를 위한 잠재 벡터 초기화
self.test_z = torch.randn((self.test_size, 128, 1, 1)).to(self.device)
# 모델 상태 불러오기 (이전 단계가 있다면)
self.load_model()
# 모델 상태 저장 메서드
def save_model(self):
# 생성자 모델 상태 저장
for i in range(self.steps+1):
torch.save(self.generator.prog_blocks[i].state_dict(), f"{model_state_dict_path[self.steps]}/generator_model/prog_blocks_{i}.pt")
torch.save(self.generator.torgb_layers[i].state_dict(), f"{model_state_dict_path[self.steps]}/generator_model/torgb_layers_{i}.pt")
# 판별자 모델 상태 저장
for i in range(self.steps+1):
torch.save(self.discriminator.prog_blocks[i].state_dict(), f"{model_state_dict_path[self.steps]}/discriminator_model/prog_blocks_{i}.pt")
torch.save(self.discriminator.fromrgb_layers[i].state_dict(), f"{model_state_dict_path[self.steps]}/discriminator_model/fromrgb_layers_{i}.pt")
# 모델 상태 불러오기 메서드
def load_model(self):
if self.steps == 0:
return # 첫 단계에서는 불러올 모델이 없음
# 이전 단계의 생성자 모델 상태 불러오기
for i in range(self.steps):
self.generator.prog_blocks[i].load_state_dict(torch.load(f"{model_state_dict_path[self.steps-1]}/generator_model/prog_blocks_{i}.pt"))
self.generator.torgb_layers[i].load_state_dict(torch.load(f"{model_state_dict_path[self.steps-1]}/generator_model/torgb_layers_{i}.pt"))
# 이전 단계의 판별자 모델 상태 불러오기
for i in range(1, self.steps+1):
self.discriminator.prog_blocks[i].load_state_dict(torch.load(f"{model_state_dict_path[self.steps-1]}/discriminator_model/prog_blocks_{i-1}.pt"))
self.discriminator.fromrgb_layers[i].load_state_dict(torch.load(f"{model_state_dict_path[self.steps-1]}/discriminator_model/fromrgb_layers_{i-1}.pt"))
# CUDA 메모리 정리 메서드
def clear_cuda_memory(self):
gc.collect()
torch.cuda.empty_cache()
# 테스트 실행 및 이미지 저장 메서드
def test(self, epoch):
self.generator.eval()
self.discriminator.eval()
pred = self.generator(self.test_z, alpha=self.alpha)
pred = pred.detach().cpu()
test_image = merge_test_pred(pred)
test_image.save(fp=f"./train_log/{resolution_list[self.steps]}/epoch-{epoch}.jpg")
# 학습 실행 메서드
def train(self):
self.generator.train()
self.discriminator.train()
generator_avg_loss = 0
discriminator_avg_loss = 0
for _ in range(len(self.trainloader)):
self.alpha += self.alpha_gap # 점진적 학습을 위한 알파 값 조절
real_image = next(iter(self.trainloader)).to(self.device)
real_label = torch.full((real_image.size(0), 1), 1).type(torch.float).to(self.device)
fake_label = torch.full((real_image.size(0), 1), 0).type(torch.float).to(self.device)
# 판별자 학습
z = torch.randn(real_image.size(0), 128, 1, 1).to(self.device)
fake_image = self.generator(z, alpha=self.alpha)
d_fake_pred = self.discriminator(fake_image, alpha=self.alpha)
d_fake_loss = self.criterion(d_fake_pred, fake_label)
d_real_pred = self.discriminator(real_image, alpha=self.alpha)
d_real_loss = self.criterion(d_real_pred, real_label)
d_loss = d_fake_loss + d_real_loss
self.discriminator_optim.zero_grad()
d_loss.backward()
self.discriminator_optim.step()
discriminator_avg_loss += (d_loss.item() / 2)
# 생성자 학습
z = torch.randn(real_image.size(0), 128, 1, 1).to(self.device)
fake_image = self.generator(z, alpha=self.alpha)
d_fake_pred = self.discriminator(fake_image, alpha=self.alpha)
g_loss = self.criterion(d_fake_pred, real_label)
self.generator_optim.zero_grad()
g_loss.backward()
self.generator_optim.step()
generator_avg_loss += g_loss.item()
self.clear_cuda_memory() # CUDA 메모리 정리
generator_avg_loss /= len(self.trainloader)
discriminator_avg_loss /= len(self.trainloader)
return generator_avg_loss, discriminator_avg_loss
# 검증 실행 메서드
def valid(self):
self.generator.eval()
self.discriminator.eval()
generator_avg_loss = 0
discriminator_avg_loss = 0
for _ in range(len(self.validloader)):
real_image = next(iter(self.validloader)).to(self.device)
real_label = torch.full((real_image.size(0), 1), 1).type(torch.float).to(self.device)
fake_label = torch.full((real_image.size(0), 1), 0).type(torch.float).to(self.device)
# 판별자 검증
z = torch.randn((real_image.size(0), 128, 1, 1)).to(self.device)
fake_image = self.generator(z, alpha=self.alpha)
d_fake_pred = self.discriminator(fake_image.detach(), alpha=self.alpha)
d_fake_loss = self.criterion(d_fake_pred, fake_label)
d_real_pred = self.discriminator(real_image, alpha=self.alpha)
d_real_loss = self.criterion(d_real_pred, real_label)
discriminator_avg_loss += ((d_fake_loss + d_real_loss).item() / 2)
# 생성자 검증
z = torch.randn((real_image.size(0), 128, 1, 1)).to(self.device)
fake_image = self.generator(z, alpha=self.alpha)
d_fake_pred = self.discriminator(fake_image.detach(), alpha=self.alpha)
g_loss = self.criterion(d_fake_pred, real_label)
generator_avg_loss += g_loss.item()
self.clear_cuda_memory() # CUDA 메모리 정리
generator_avg_loss /= len(self.validloader)
discriminator_avg_loss /= len(self.validloader)
return generator_avg_loss, discriminator_avg_loss
# 전체 학습 및 검증 과정 실행 메서드
def run(self, epochs):
train_history = []
valid_history = []
self.alpha = 0 # 현재 단계와 이전 단계의 이미지를 혼합하는 비율
self.alpha_gap = 1 / (len(self.trainloader) * (epochs[1] - epochs[0])) # 알파 값을 조절하기 위한 간격
for epoch in range(*epochs):
print("-"*100 + "\n" + f"Epoch: {epoch}")
train_history.append(self.train()) # 학습 실행
print(f"\tTrain\n\t\tG Loss: {train_history[-1][0]},\tD Loss: {train_history[-1][1]}")
valid_history.append(self.valid()) # 검증 실행
print(f"\tValid\n\t\tG Loss: {valid_history[-1][0]}, \t D Loss: {valid_history[-1][1]}")
self.test(epoch) # 테스트 실행 및 이미지 저장
return train_history, valid_history
# 스크립트 실행 부분
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 학습에 사용할 디바이스 설정
for steps in range(7): # 7단계의 해상도에 대해 학습 실행
trainer = Trainer(steps=steps, batch_size=16, device=device, test_size=16) # 트레이너 인스턴스 생성
train_history, valid_history = trainer.run((0, 30)) # 학습 및 검증 실행
trainer.save_model() # 모델 상태 저장
- init 메서드: 학습에 필요한 변수들을 초기화. 데이터셋을 로드하고, 생성자와 판별자 모델을 초기화하며, 손실 함수와 옵티마이저 설정. 또한, 모델을 저장하고 불러오는 메서드와 CUDA 메모리 정리를 위한 메서드 정의.
- save_model 메서드: 학습된 모델의 상태를 저장. 이 메서드는 각 단계별로 생성자와 판별자의 파라미터를 디스크에 저장.
- load_model 메서드: 이전 단계에서 저장된 모델 상태를 불러온다. 이는 점진적 학습 과정에서 이전 단계의 학습 결과를 현재 단계의 초기 상태로 사용하기 위함.
- clear_cuda_memory 메서드: CUDA 메모리를 정리하여 GPU 메모리 누수를 방지.
- test 메서드: 생성자가 생성한 이미지를 저장하여, 학습 과정을 시각적으로 검증할 수 있다.
- train 메서드: 생성자와 판별자의 학습을 수행한다. 실제 이미지에 대한 판별자의 손실과 생성된 이미지에 대한 판별자의 손실을 계산하여 업데이트하고, 생성자의 손실도 계산하여 업데이트한다.
- valid 메서드: 검증 데이터셋에 대해 모델의 성능을 평가한다.
- run 메서드: 주어진 에포크 수만큼 학습과 검증 과정을 반복 실행한다. 각 에포크마다 학습 및 검증 손실을 출력하고, 주기적으로 생성된 이미지를 저장하여 학습 진행 상황을 모니터링.
alpha와 fade_in 메서드: alpha 값은 현재 단계와 이전 단계의 이미지를 혼합하는 비율을 결정한다. 학습 과정에서 점진적으로 0에서 1까지 증가시키면서, 새로운 해상도의 특성을 학습하는 동안 이전 단계의 특성도 유지할 수 있도록 한다. fade_in 메서드의 주된 목적은 새로운 해상도의 특성을 점진적으로 모델에 학습시키는 동안 이전 단계의 중요한 특성을 잃지 않게 하는 것 이다. 이 메서드를 통해 모델은 새로운 해상도의 이미지를 생성하면서도, 이전 해상도에서 학습한 중요한 디테일과 패턴을 유지할 수 있게 된다. 이러한 점진적 학습 방식은 모델이 더 높은 해상도로 성장함에 따라, 학습 과정이 안정적으로 이루어지도록 돕고, 최종적으로는 더 정교한 이미지를 생성할 수 있게 한다.
Dataset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
class Dataset:
def __init__(self, directory_list, resolution):
# 디렉토리 경로 리스트와 이미지 해상도 초기화
self.directory_list = directory_list
self.resolution = resolution
def image_to_tensor(self, path, res):
# 주어진 경로의 이미지를 열고, 지정된 해상도로 조정한 뒤 텐서로 변환
img = Image.open(path).resize(res)
tensor_img = transforms.ToTensor()(img)
tensor_img = tensor_img.type(torch.float16)
return tensor_img
def dataset_to_tensor(self, directory_path):
# 주어진 디렉토리 내 모든 이미지 파일을 텐서로 변환하여 텐서 데이터셋 생성
files = os.listdir(directory_path)
tensor_dataset = torch.zeros((len(files), 3, *self.resolution)).type(torch.float16)
for i, file in enumerate(files):
tensor_dataset[i] = self.image_to_tensor(os.path.join(directory_path, file), self.resolution)
return tensor_dataset
def extract_dataset(self):
# directory_list에 포함된 모든 디렉토리로부터 데이터셋을 추출
dataset_pair = [self.dataset_to_tensor(directory_path) for directory_path in self.directory_list]
return dataset_pair
def make_gif(paths, save_path, fps=500):
# 주어진 이미지 경로 리스트를 사용해 GIF 파일을 생성
img, *imgs = [Image.open(path) for path in paths]
img.save(fp=save_path, format="GIF", append_images=imgs, save_all=True, duration=fps, loop=1)
def merge_test_pred(pred):
# 예측된 텐서 이미지들을 하나의 큰 이미지로 병합
test_size = pred.size(0)
# 병합할 이미지의 그리드 크기 계산
for i in range(int(np.sqrt(test_size)), test_size + 1):
if test_size % i == 0:
n_height = max(i, test_size // i)
n_weight = min(i, test_size // i)
break
# 최종 이미지의 크기 결정
image_size = (1024 - (1024 % n_weight), 1024 - (1024 % n_height))
one_image_size = (image_size[0] // n_weight, image_size[1] // n_height)
# 새로운 이미지를 생성하고 각 예측 이미지를 해당 위치에 붙인다.
image = Image.new('RGB', image_size)
for w in range(n_weight):
for h in range(n_height):
img = transforms.ToPILImage()(pred[n_height*w + h])
img = img.resize(one_image_size)
image.paste(img, (one_image_size[0] * w, one_image_size[1] * h))
return image
# 주석 처리된 부분은 데이터셋을 텐서로 변환하고 저장하는 과정
# 해상도별로 이미지 데이터셋을 로드하고, 각 이미지를 지정된 해상도로 조정한 후 텐서로 변환
# 학습 로그 이미지들을 사용하여 GIF 파일을 생성하는 과정
# 각 해상도 단계별로 저장된 학습 로그 이미지들을 순서대로 읽고, 이를 GIF로 변환하여 저장
resolution_list = ["4x4", "8x8", "16x16", "32x32", "64x64", "128x128", "256x256"]
train_log_file_list = []
cnt = 0
for resolution in resolution_list:
directory = f"./train_log/{resolution}"
for file_name in os.listdir(directory):
current_epoch = int(file_name.replace("epoch-", "").replace(".jpg", ""))
train_log_file_list.append((cnt + current_epoch, f"{directory}/{file_name}"))
cnt += len(os.listdir(directory))
train_log_file_list.sort(key=lambda x: x[0])
train_log_file_list = [i[1] for i in train_log_file_list]
for i in range(10): # 마지막 이미지를 반복하여 GIF의 끝을 연장
train_log_file_list.append(train_log_file_list[-1])
make_gif(train_log_file_list, "./train_log/train.gif", 2) # GIF 생성
- 데이터셋 처리:
Dataset클래스는 디스크에서 이미지 파일을 읽어 해상도를 조정한 후, 이를 텐서로 변환하는 과정을 담당한다. 이 과정은 모델 학습에 필요한 데이터를 준비하는 데 필수적이다.
- GIF 생성: 학습 과정에서 생성된 이미지들을 시각적으로 확인하기 위해 GIF 파일을 생성한다.
make_gif함수는 학습 로그의 이미지들을 입력받아 순서대로 GIF 파일을 만든다. 이를 통해 모델의 학습 진행 상황을 시각적으로 확인할 수 있다.
- merge_test_pred 함수: 이 함수는 여러 작은 이미지를 하나의 큰 이미지로 병합하는 역할을 한다. 병합 과정에서는 각 이미지의 위치를 계산하여, 최종적으로는 그리드 형태의 하나의 큰 이미지를 생성한다. 이 기능은 학습된 모델의 출력을 시각적으로 확인할 때 유용하다.