4. Issues in GANs
1. Problems with GANs
- 확률 분포가 암시적
- 생성된 이미지의 확률 분포를 직접 계산하는 것은 간단하지 않음
따라서, 일반적인 GAN은 샘플링/생성에만 적합
- 훈련이 어려움
- 수렴하지 않음
- 모드 붕괴가 발생할 수 있음
확률 분포의 암시성: GAN에서 생성된 이미지의 확률 분포를 직접적으로 계산하기는 어렵다. 이는 생성된 이미지가 실제 이미지 분포와 일치하는지 확인 하는 것을 어렵게 만든다.
샘플링/생성에만 적합함: 일반적으로 Vanilla GAN은 이미지를 샘플링 하거나 생성하는 데에만 적합하다. 확률 분포를 직접적으로 계산하기 어려우므로 GAN을 이용해 데이터 생성이나 이미지 샘플링하는데 주로 사용
훈련의 어려움: GAN은 수렴하기까지 훈련이 어려운 특성이 존재. 종종 수렴하지 않거나 모드 붕괴와 같은 문제가 발생할 수 있다. 모드 붕괴는 생성기가 특정한 종류의 이미지만을 생성하고 다양성이 부족한 형상을 나타낸다.
</br>
2. Training problems
- Non-Convergence (수렴 하지 않음)
- Mode-Collapse (모드 붕괴)
</br>
Non-Convergence
- Non-Convergence(수렴하지 않음) : GAN의 훈련은 종종 수렴하지 않는 경우가 있다. 이는 생성자와 판별자 간의 균형을 유지하는 것이 어려워 발생
- Mode-Collapse(모드 붕괴) : 모드 붕괴는 생성자가 특정한 이미지만을 생성하고 다양성이 부족한 현상을 의미. 이는 생성자가 학습 과정에서 다양한 이미지를 생성하는 대신 특정한 이미지에만 집중하여 발생
- 일반적으로 딥러닝 모델은 하나의 플레이어를 포함한다.
- 해당 플레이어는 보상을 최대화하려고 한다(손실을 최소화)
- 최적의 매개변수를 찾기 위해 역전파와 SGD를 사용한다.
- SGD는 특정 조건 하에서 수렴 보장을 제공한다.
- 문제 : 비볼록 최적화 문제에서 지역 최적값으로 수렴할 수 있음.
- $\underset{G}{\min}L(G)$
- 반면, GAN은 두개 이상의 플레이어를 포함한다.
- Discriminator는 보상을 최대화하려고 함.
- Generator는 Discriminator의 보상을 최소화하려고 함
- 이러한 관계로 나타나는 게임의 균형을 찾기 위해 SGD를 사용하는 것은 적합하지 않음
- 문제: Nash 균형에 수렴하지 않을 수 있음.
- $\underset{G}{\min} \underset{D}{\max} V(D, G)$
\(\underset{G}{\min} \underset{D}{\max} V(D, G)\) \(\text{Let } V(x, y) = xy\)  비수렴(Non-convergence)은 GAN 훈련 과정에서 생성자와 판별자가 안정적인 균형점에 도달하지 못하고 지속적으로 서로의 성능을 침범하여 훈련이 불안정해지는 현상을 말한다.
비수렴(Non-convergence)은 GAN 훈련 과정에서 생성자와 판별자가 안정적인 균형점에 도달하지 못하고 지속적으로 서로의 성능을 침범하여 훈련이 불안정해지는 현상을 말한다.
이 이미지는 GAN(Generative Adversarial Networks)의 학습 과정에서 발생할 수 있는 비수렴(non-convergence) 현상을 게임 이론의 관점에서 설명하고 있다. 이러한 비수렴 상태는 GAN 학습이 안정적인 균형점에 도달하지 못하고 계속해서 변화하는 상태를 의미한다.
GAN은 두 개의 신경망, 즉 생성자(Generator)와 판별자(Discriminator)가 서로의 반대 목표를 가지고 경쟁하면서 학습하는 구조이다. 생성자는 진짜와 구분이 안 가는 가짜 데이터를 생성하려고 시도하고, 판별자는 진짜 데이터와 가짜 데이터를 구별하려고 한다. 이러한 경쟁 과정은 미니맥스 게임(minimax game)의 형태를 띠고 있는데, 한 플레이어가 최소화하려는 것을 다른 플레이어가 최대화하려는 형태이다.
</br>
이미지에 나타난 내용은 다음과 같다:
min_x max_y V(x, y)는 판별자(y)가 자신의 손실을 최대화하려 하고, 생성자(x)는 손실을 최소화하려 하는 미니맥스 게임을 나타낸다.V(x, y) = xy는 이 게임에서의 가치 함수(value function)로 여기서x는 생성자의 출력을,y는 판별자의 출력을 나타낸다
</br>
비수렴 상태는 다음과 같이 나타난다.
- State 1: 두 플레이어 모두 자신의 가치를 늘리려고 시도 (
x>0,y>0로 가치 함수V가 양수). 이 상태에서 판별자는 자신의 가치를 늘리기 위해 더 많이y를 증가시키려 하고, 생성자는x를 감소시키려고한다. - State 2: 생성자는
x를 줄임으로써 가치 함수를 음수로 만들고 (x<0), 판별자는 여전히y를 증가시키려한다. 이 상태에서 판별자는y를 줄이고 생성자는x를 계속 줄인다. - State 3: 이제 두 플레이어 모두 음수 값을 가지고 (
x<0,y<0로V가 양수), 판별자는y를 줄이려 하고 생성자는x를 증가시키려한다. - State 4: 생성자가
x를 증가시키고 판별자가y를 줄이면, 가치 함수가 다시 음수가 되고 (x>0,y<0), 판별자는y를 증가시키고 생성자는x를 증가시키려한다. - State 5: 이 상태는 상태 State 1 동일하며 (
x>0,y>0), 이 과정이 계속 반복되어 시스템이 비수렴 상태에 빠지게 된다.
이러한 순환은 각 플레이어(여기서는 생성자와 판별자)가 자신의 전략을 조정함에 따라 상대방도 그에 맞추어 전략을 조정 해야 하기 때문에 발생한다.
</br>
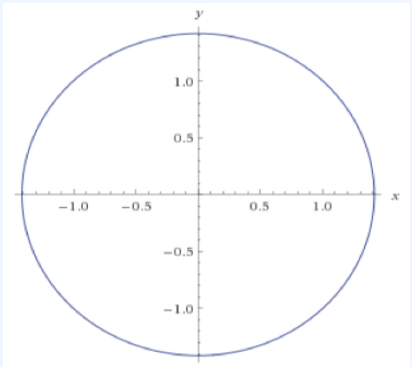 이 이미지는 최적화 문제와 관련된 미분방정식이 수렴하지 않는 상황을 설명.
이 이미지는 최적화 문제와 관련된 미분방정식이 수렴하지 않는 상황을 설명.
</br>
문제는 $\underset{x}{\min} \underset{y}{\max} xy$ 로 표현되며, 이는 xy를 최소화하는 x 값을 찾고, 동시에 xy를 최대화하는 y 값을 찾는 문제로 볼 수 있다.
- 미분 방정식
- ${∂\over{∂x}} = -y$
- ${∂\over∂y} = x$
- ${∂²\over∂y²} = {∂\over∂x} = -y$
</br>
이러한 미분 방정식의 해가 사인(sinusoidal) 항을 포함한다. 이는 해가 주기적인 성질을 가지고 있음을 의미하며, 이는 일반적으로 최적화 문제에서 수렴하는 해를 찾는 것과 상충된다.
학습률이 작더라도 이러한 미분방정식의 해가 수렴하지 않는다. 이는 최적화 알고리즘에서 학습률을 작게 설정하여 점진적으로 최적의 해에 다가가려는 시도가 이 경우에는 실패할 것.
</br>
그래프는 이러한 미분방정식의 해가 어떻게 비주기적인 경로를 따르는지를 시각적으로 나타내고 있으며, 이는 일반적으로 원하는 최적화 문제의 수렴 패턴과 다르다. 이 경우, 최적화 알고리즘이 전역 최적점(global minimum or maximum)에 도달하지 못하고 주기적인 경로를 계속 따르게 된다.
</br>
Mode-Collapse


</br> </br>
3. Basic solutions
- Mini-Batch GANs
- Supervision with labels
</br>
Mini-Batch GANs
- 모드 붕괴 시,
- 생성자는 좋은 샘플을 생성하지만 그 중 일부만 생성
- 따라서, 판별자는 그것들을 가짜로 판별할 수 없다
- 이 문제를 해결하기 위해,
- 판별자에게 이 극단적인 경우에 대해 알려둔다.
- 보다 형식적으로,
- 판별자가 단일 예제가 아닌 전체 배치를 살펴보도록 한다.
- 다양성이 부족한 경우, 이 예제들을 가짜로 표시한다.
- 따라서,
- 생성자는 다양한 샘플을 생성하도록 강제된다.
모드 붕괴는 생성자가 특정한 종류의 이미지만을 생성하고 다양성이 부족한 현상을 의미한다. 이 문제를 해결하기 위해 판별자를 개선하여 전체 배치를 고려하도록 만들면, 판별자는 다양성이 부족한 경우에는 이를 가짜로 판별할 수 있다. 이는 생성자가 다양한 샘플을 생성하도록 강제하여 모드 붕괴를 피할 수 있도록 도와준다.
- 미니 배치에서 다양성을 포착하는 특징을 추출
- 예를 들어, 배치 내의 모든 쌍의 차이를 L2 Norm 으로
해당 특징들을 이미지와 함께 판별자에게 전달
- 특정 값은 다양한 배치와 다양하지 않은 배치 사이에서 다를 것
- 따라서, 판별자는 분류를 위해 해당 특징에 의존할 것
- 이는 차례대로,
- 생성자가 실제 데이터와 해당 특징 값이 일치하도록 강제할 것
- 다양한 배치를 생성
이러한 접근 방식은 다양성을 캡처하기 위해 배치의 특징을 활용한다. 특징을 판별자에게 제공함으로써 판별자는 다양성 있는 배치와 그렇지 않는 배치를 구별할 수 있다. 이러한 구별을 통해 생성자는 다양한 샘플을 생성해 실제 데이타와 해당 특징 값이 일치하도록 강제된다. 결과적으로 생성자는 다양성 있는 배치를 생성하게 된다.
</br>
Supervision with labels
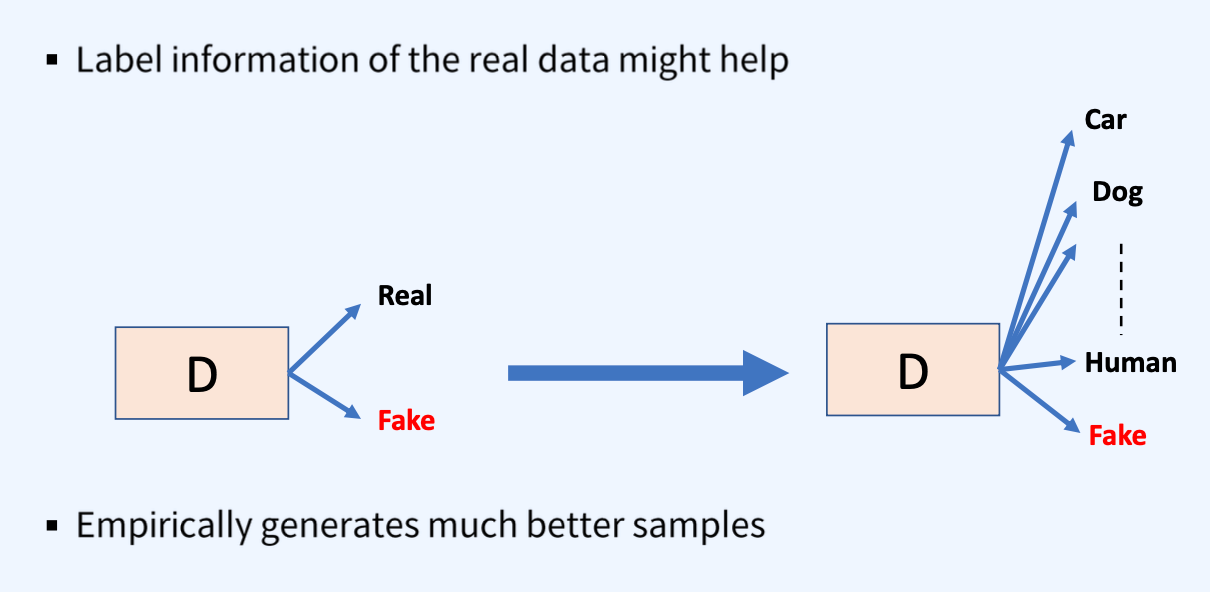
- 두번째 D는 판별자가 단순히 데이터가 실제인지 가짜인지를 구분하는 것을 넘어, 실제 데이터의 레이블 정보를 사용해 보다 구체적인 피드백을 제공할 수 있음을 나타낸다.
- 실제 데이터의 레이블 정보가 판별자가 더 정확한 판단을 내리는 데 도움이 될 수 있다.
- 레이블 정보를 사용함으로써 생성자가 실제와 더 비슷한, 즉 품질이 더 높은 데이터 샘플을 생성할 수 있음을 나타낸다.
</br>
일반적인 GAN구조에 지도 학습 요소를 추가해 생성자가 더 높은 품질의 데이터를 생성할 수 있게하고, 판별자가 더 정확하게 가짜 데이터를 식별하도록 하는것이며. 이는 GAN이 특정 종류의 데이터를 생성할 때 그 효율성을 향상시키는 한 방법이다.