Transfer Learning 논문 리뷰
| 태그 | #TransferLearning |
|---|---|
| 한줄요약 | Transfer Learning |
| Journal/Conference | #NIPS |
| Link | Transfer Learning |
| Year(출판년도) | 2014 |
| 저자 | Jason Yosinski, Jeff Clune, Yoshua Bengio, Hod Lipson |
| 원문 링크 | Transfer Learning |
핵심 요약
- 기존에 학습한 모델의 가중치를 재사용하는 Transfer Learning 방법론을 딥러닝에 적용하는 논문이다.
- 딥러닝 모델 내부에서 전이 학습이 효과적인 부분을 결정하는 실험적인 결과를 제시한다.
- 학습된 가중치를 초기값으로 사용해 fine-tuning 했을 때 딥러닝 모델의 일반화 성능을 향상시킬 수 있음을 제시한다.
Introduction
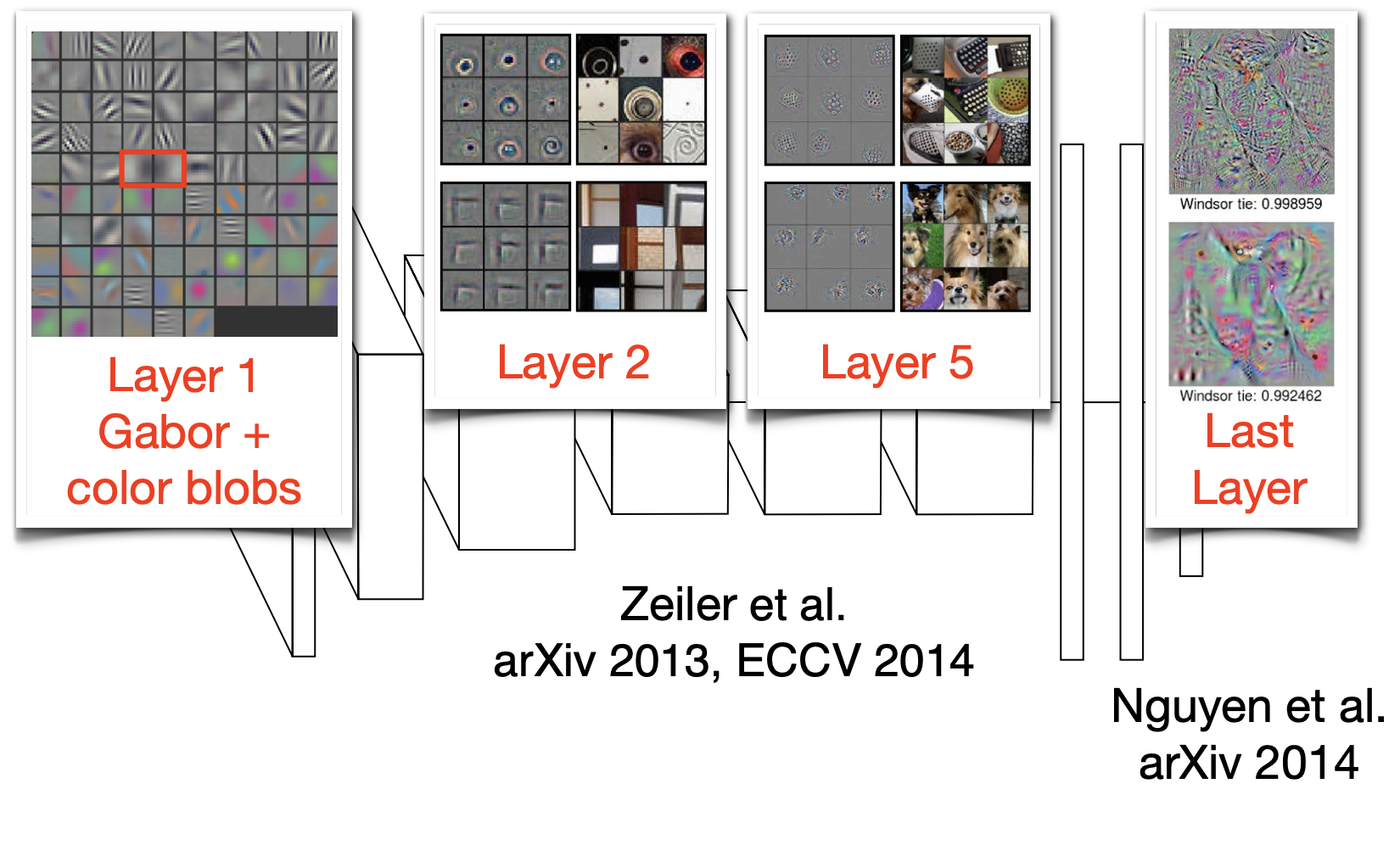
서로 다른 데이터셋을 사용하고 다른 목적으로 학습하였음에도, 이미지 기반 딥러닝 모델의 1번째 레이어의 feature 가 모두 유사한 형태(Gabor + color blobs)로 학습되는 현상을 볼 수 있다. 이러한 1번째 레이어의 feature 를 general 하다고 표현한다.
반면, 마지막 레이어의 feature 는 서로 다른 모델에서 굉장히 다른 양상을 보인다. 이를 specific 하다고 표현한다.
논문은 딥러닝 모델 내부에서 general 한 feature 를 특정하여, 전이 학습에 사용할 수 있는 방법을 제시한다
이렇게 딥러닝 모델을 구성하는 레이어에는 general/specific feature 가 혼합되어 있다. 논문은 여기서 다음과 같은 질문을 제시한다.
- 특정한 layer 의 feature 가 general / specific 한 정도를 측정할 수 있을까?
- general 에서 specific 한 feature 로의 변화는 단일 layer 에서 발생할까? 혹은 넓은 layer 에 걸쳐서 일어날까?
- general 에서 specific 한 feature 로의 변화는 모델의 어느 지점에서 일어날까?
논문은 모델에서 general 한 feature 를 특정하여 전이 학습(transfer learning) 에 사용할 수 있는 방법을 제시한다.
전이 학습(transfer learning)은 base 데이터셋과 과제로 학습한 base 네트워크의 feature 를 다른 데이터셋과 과제를 수행해야하는 target 네트워크에 전이하여 사용하는 학습 방법이다.
이를 통해 작은 크기의 dataset 에도 과적합없이 훈련을 수행할 수 있다.
대부분의 전이 학습은 base 네트워크를 훈련한 뒤 첫번째부터 n 개의 레이어를 복사해 target 네트워크에 붙여넣는다. target 네트워크의 나머지 layer들은 랜덤하게 초기화하고 target task 를 사용하려 훈련을 진행한다.
이 때, base 네트워크의 layer 는 두가지 방법을 선택할 수 있다.
- frozen : 새로운 task에 대해 훈련을 하는 동안 update를 하지 않는다.
- target dataset의 크기가 작고 parameter의 수가 많은 경우
- fine-tune : error backpropagation 을 통해 update를 한다.
- target dataset의 크기가 크고 parameter수가 적은 경우
논문은 두 방법을 비교한 결과 또한 제시한다.
Generality vs. Specificity Measured as Transfer Performance
논문은 generality 를 다음과 같이 정의합니다.
- task A 에서 학습된 feature 가 다른 task B 에 사용될 수 있는 정도
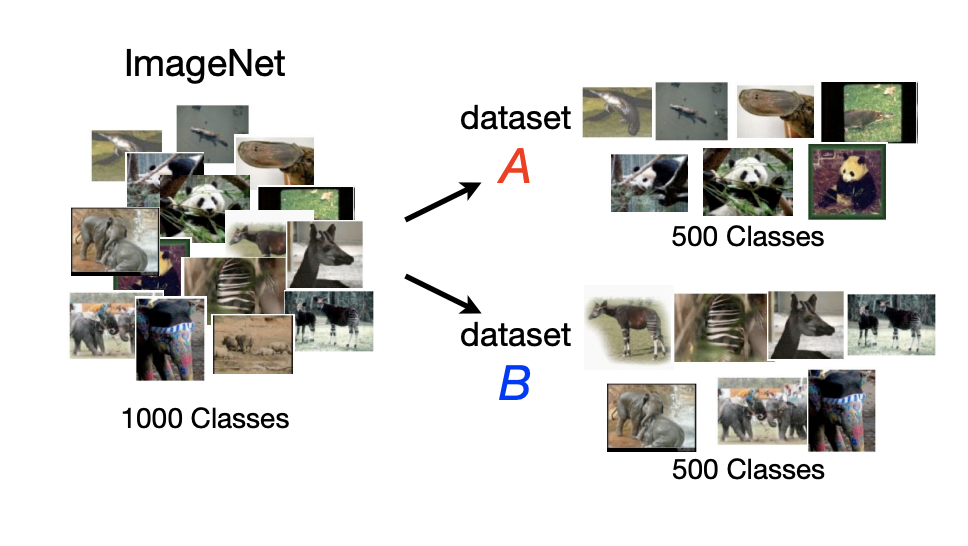
이를 분석하기 위해 위와 같이 ImageNet dataset의 1000개의 클래스를 500개씩 무작위로 분할하여 task dataset A/B 를 생성한다.
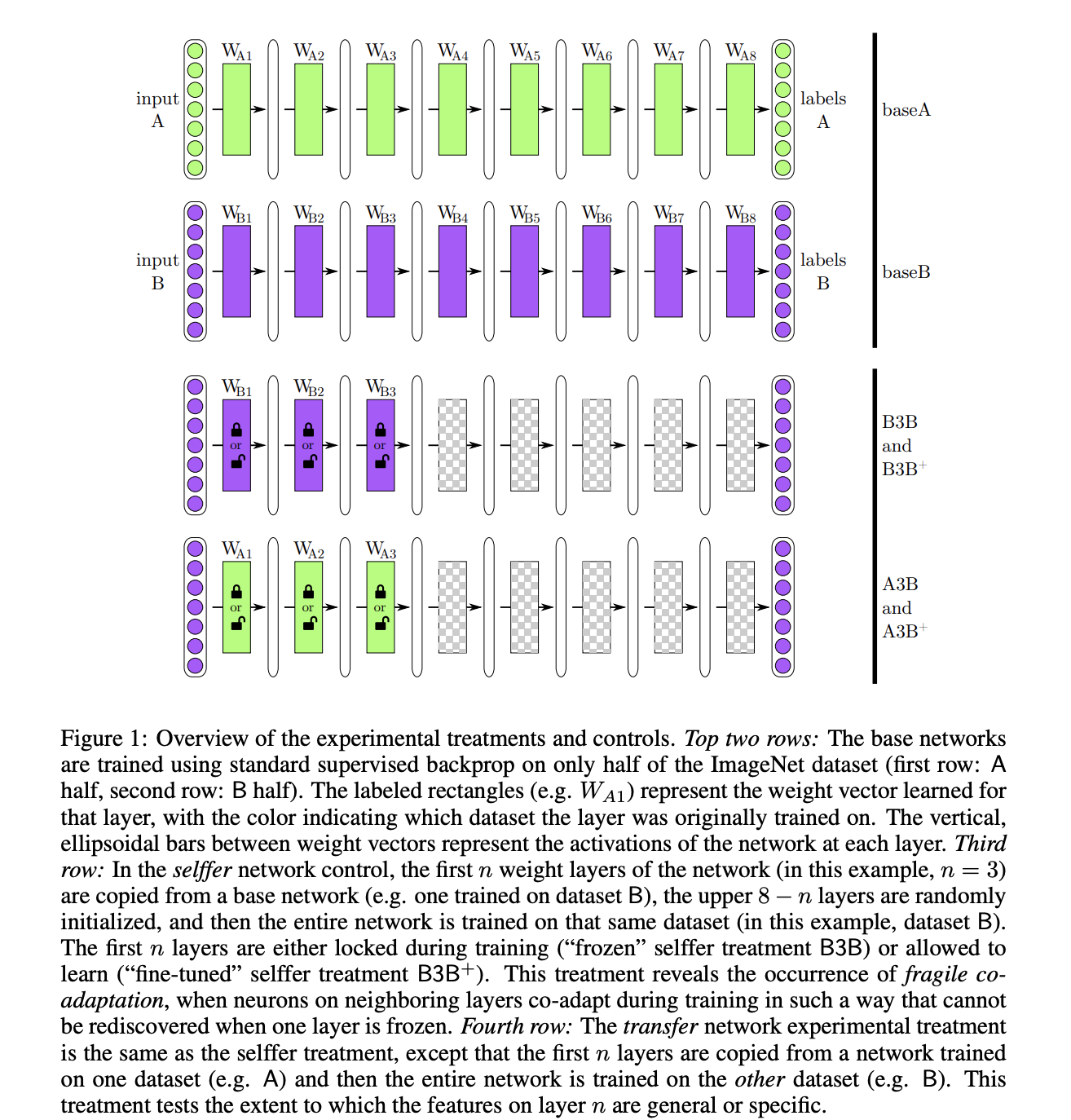
task A / B 는 그림과 같은 8-layer CNN 모델을 사용하여 학습합니다. 이를 baseA/baseB 네트워크로 부르며, 이를 이용해 새로운 네트워크를 생성한다.
- B3B selffer 네트워크
- base B 에서 처음 3 layer 를 복사한뒤 고정(frozen)
- 뒤의 5 layer 는 랜덤 초기화 수행후 데이터셋 B 로 학습
- 자기 자신을 transfer 하는 대조군 모델
- A3B trasnfer 네트워크
- base A 에서 처음 3 layer 를 복사한 뒤 고정
- 뒤의 5 layer 는 랜덤 초기화 수행후 데이터셋 B 로 학습
- 네트워크의 성능으로 처음 3 layer 의 generality 판단
같은 방법으로 $n={1,2,\dots,7}$ 일 때 AnB/BnA 모델 또한 생성할 수 있다.
또한, transfer 후 layer 를 고정하지 않고 fine-tuning 하는 네트워크를 생성한다.
- B3B+ selffer 네트워크 : B3B 와 동일하지만 fine-tuning 수행
- A3B+ transfer 네트워크 : A3B 와 동일하지만 fine-tuning 수행
generality 는 task A/B 의 유사성에 따라 달라질 수 있다. 논문은 ImageNet 이 유사한 class 에 대한 계층적 정보(예시 : 고양이과 동물 - 샴, 표범, 재규어, 사자, 호랑이 등) 를 제공한다는 점에 주목한다. 무작위로 class 를 분할하는 경우 계층 내부의 class 또한 비슷하게 분할될 확률이 높다. 따라서, 무작위 분할의 경우 task A/B 의 유사도가 높다고 설명한다.
Experimental Setup
전이 학습의 효과를 검증하는 것이 목적이므로, 실험 관련 항목을 세세하게 조정하지 않았다고 설명한다. 자세한 사항은 http://yosinski.com/transfer 에서 확인할 수 있다.
Results and Discussion
Similar Datasets: Random A/B splits
데이터를 랜덤하게 분할하여 데이터셋이 유사한 경우에 전이학습을 수행한 결과를 분석한다. 이 때는 이론적으로 AnA 와 BnB 네트워크의 통계적 성질이 동일하며, BnA 와 AnB 또한 동일하다. 따라서 편의를 위해 모델 표기를 BnB, AnB 로 통합했다.
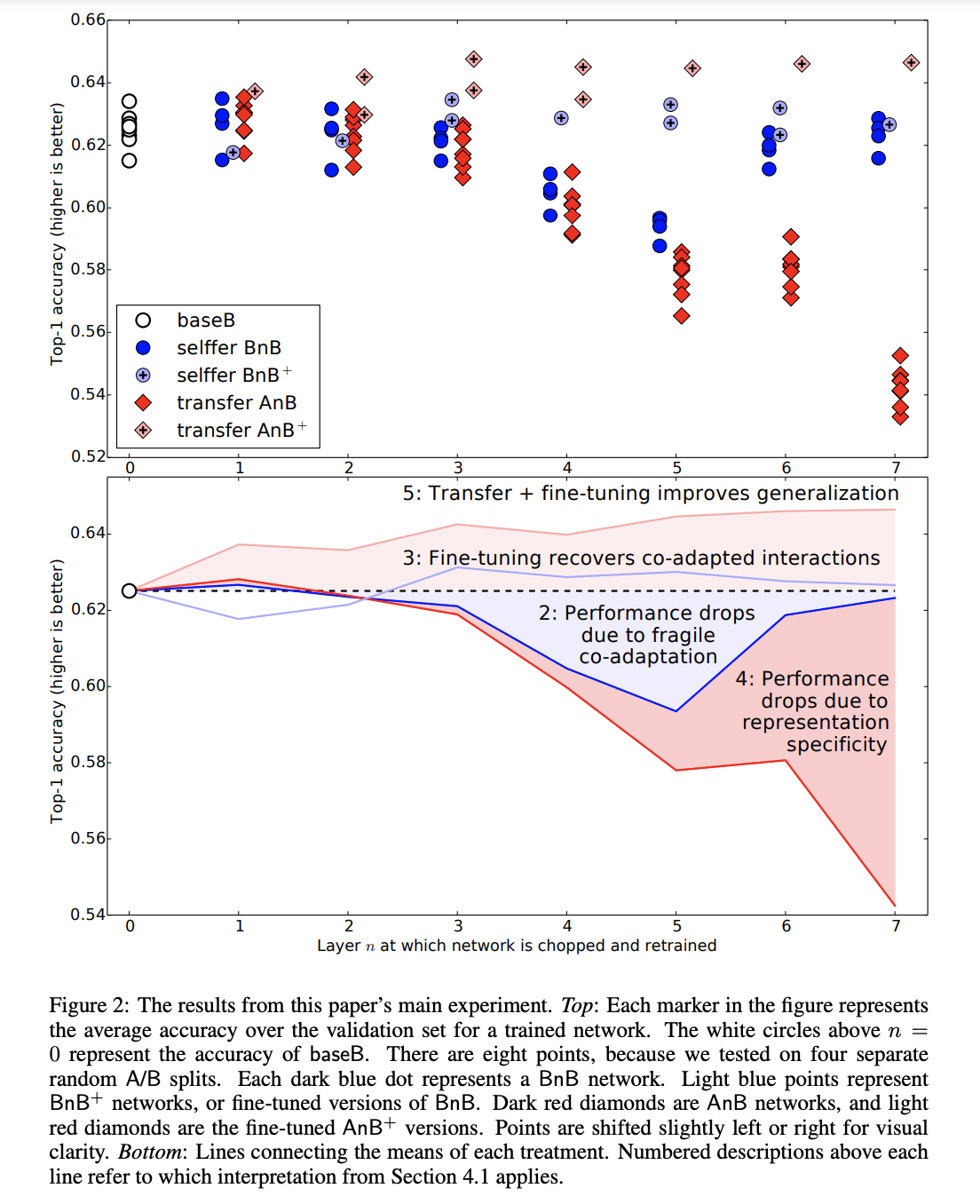
위의 성능 실험 그래프에 대한 분석 결과를 다음과 같이 제시한다.
- baseB
- 500개 클래스들의 랜덤한 서브셋을 분류하는 네트워크
- 1000개 클래스를 학습한 네트워크 보다 더 낮은 오차를 보임 → 적은 데이터로 인한 과적합의 가능성 존재
- BnB
- B1B, B2B 는 base B 와 성능이 유사 → 2번째 layer 까지는 general feature로 볼수 있음
- B3B 부터 성능이 감소하며, B4B/B5B 에서는 더 심하게 감소함 → baseB 가 fragile co-adapted features를 가지고 있음 → co-adaptiation으로 인해 upper-layer에 의해 학습이 불가능한 feature 를 포함함
- B6B 부터는 다시 성능이 증가함 → 학습양이 줄어듬으로 인해 학습이 쉬워짐을 의미
- BnB+
- baseB 와 비슷한 성능을 보임
- BnB 와 비교했을 때, fine-tune을 통해 성능 저하 문제를 개선했음을 시사
- AnB
- A1B,A2B 는 비슷한 성능을 보임
- layer 수가 증가할 수록 성능이 감소
- 3,4,5 layer : co-adaptation
- 6,7 layer : specific features
- AnB+
- BnB+ 와 동일한 시간 훈련했음에도 가장 좋은 성능을 보임
- 450k iteration 후에도 base dataset의 영향이 여전히 존재하며 일반화 성능을 높이고 있다고 설명
Dissimilar Datasets: Splitting Man-made and Natural Classes Into Separate Datasets
데이터를 분할할 때 인공물(551 class)/자연물(440 class)로 유사성이 없도록 분할한 뒤 수행한 실험 결과를 제시한다.
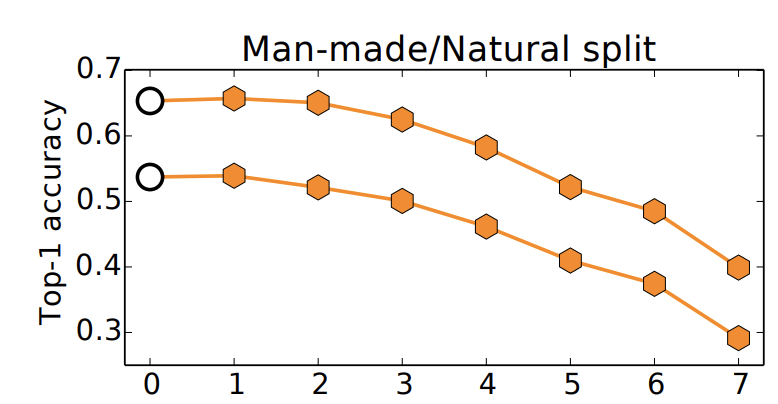
윗 줄은 baseB 와 AnB, 아랫줄은 baseA 와 BnA 성능을 나타낸다
class 갯수의 차이로 성능에 차이가 존재하지만, transfer layer 가 증가할수록 성능이 감소하는 것을 확인할 수 있다. 논문은 데이터의 유사성이 적어 feature transfer의 효과가 감소하였다고 설명한다.
Random Weights
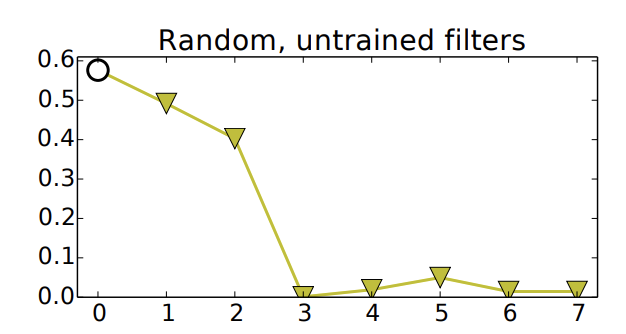
일부 레이어에 학습되지 않은 랜덤한 가중치를 전이했을 때의 결과로, 좋지 않은 성능을 보인다.
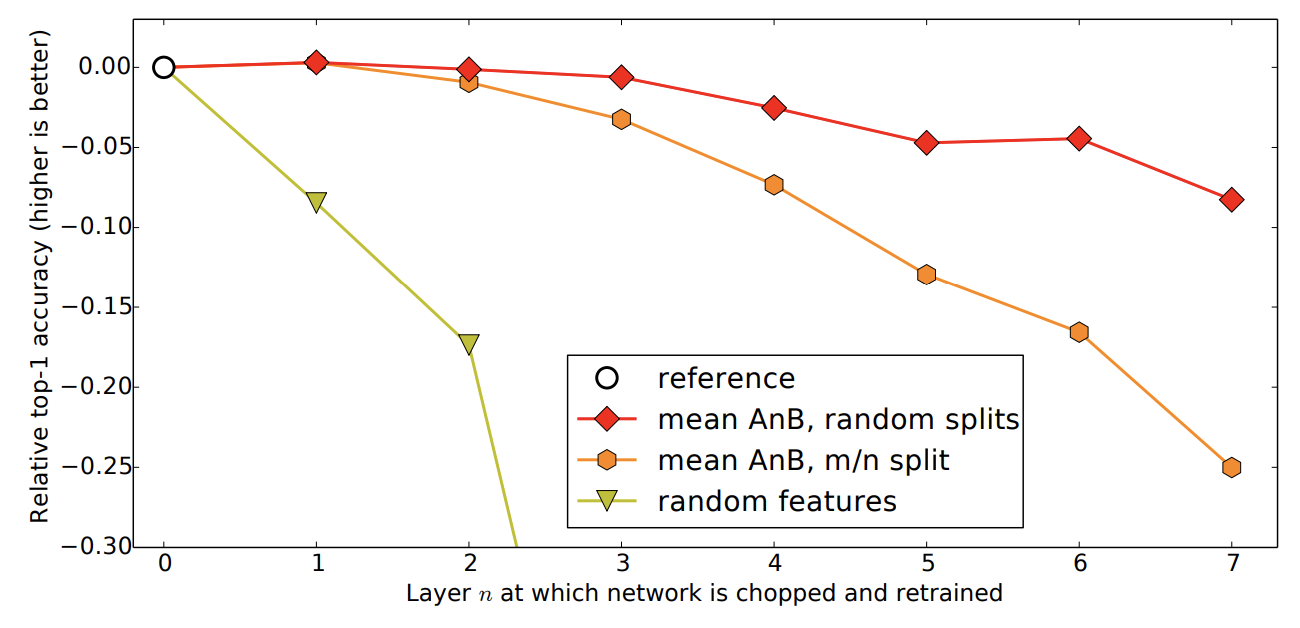
이후 논문은 실험결과를 종합한 그래프와 그 설명을 제시한다.
- feature 를 전이하고 고정했을 때, 전이하는 layer 갯수가 증가할수록 유사한 task 보다 유사하지 않은 task 의 성능이 더 크게 감소
- 유사하지 않은 task 의 feature 를 전이했을 때도 random feature 보다 좋은 성능을 보임
Conclusions
딥러닝 모델에서 각 layer 의 feature 의 전이 가능성을 정량화 할수 있는 방법을 제시했다.
또한, 전이 학습이 원활하게 작동하지 않는 경우 대한 설명으로 두가지를 제시한다.
- co-adapted 된 layer 를 분할함으로 인해 생기는 훈련의 어려움
- higher layer feature 의 sepcific 한 성질
또한, 모델에서 layer 를 전이하는 위치의 특성에 따라 학습의 성능이 달라질 수 있음을 제시한다.
또한, 전이 학습의 가중치를 초기값으로 사용한 경우 일반화 성능이 향상될 수 있으며, 이를 통해 딥러닝 모델의 전반적인 성능을 개선할 수 있음을 강조한다.