GloVe 논문 리뷰
| 태그 | #NLP |
|---|---|
| 한줄요약 | Glove |
| Journal/Conference | #EMNLP |
| Link | Glove |
| Year(출판년도) | 2014 |
| 저자 | Jeffrey Pennington, Richard Socher, and Christopher Manning |
| 원문 링크 | Glove |
Abstract
저자들은 단어 벡터들에서 나타나는 특성을 분석하여 새로운 global log-bilinearl 회귀 모델 GloVe를 제안했다. 이 모델은 기존에 많이 연구되었던 global matrix factorization 방법과 local context window 방법의 장점을 모두 가지고있다. 또한, 단어-단어 동시 발생 행렬 내 nonzero elements(0이 아닌 값)만을 학습하여 통계적인 정보를 효율적으로 사용한다. GloVe는 word analogy, word similarity, named entity recogntion task에 이전 연구에 비해 뛰어난 성능을 달성했다.
Introduction
단어 벡터를 학습하는 방법이 활발히 연구되어 왔으며, 크게 2개의 방법이 존재한다. 두 방법 모두 큰 단점이 존재한다. Global matrix factorization methods(e.g., LSA)는 전체 코퍼스의 통계정보를 잘 담는다. 하지만 이 방식은 단어의 빈도 수에 기반하기 때문에 단어 유사도를 잘 잡지 못한다. 반면 Local context window methods(e.g., Skip-gram)은 단어 유사도는 잘 파악하지만 코퍼스의 통계 정보를 파악하지 못한다.
저자들이 제안한 global log-bilinear 회귀 모델인 GloVe는 단어 representation을 학습하는 모델이 필요한 특성들을 모두 가지고 있다. 단어-단어 동시발생 행렬을 학습하기 때문에 코퍼스 통계 정보를 잘 학습하고, 모델이 만든 단어 벡터가 word analogy task에 높은 성능을 보임을 확인했다. 이외에도 word similarity, named entity recogntition task에 이전 모델보다 우수한 성능을 보였다.
The Glo Ve Model
corpus 내 단어들의 등장 횟수에 대한 통계치는 word representation을 학습하는 모든 비지도 방법들에게 가장 중요한 정보를 제공하지만, 의미가 통계치들로부터 어떻게 생성되는지, 만들어진 word representation들이 그 의미를 어떻게 표현할수 있는지에 대한 의문은 풀리지 않았다.
저자들은 이러한 인사이트를 단어의 representation을 만드는 새로운 모델 Glo Ve에 활용했다. Global Vectors의 약자로, 해당 모델은 global corpus 통계치를 직접적으로 파악하기 때문에 붙여진 이름이다.
먼저 단어-단어 동시발생행렬(word-word co-occurance matrix) $X$ 가 있다고 하자. 행렬 원소 $X_{i,j}$ 는 단어 $i$의 context에 단어 $j$ 가 몇 번 등장했는지를 나타낸다. $X_i=\sum_k X_{ik}$ 는 단어 $i$ 의 context내에서 발생한 모든 단어들의 수 이다. 마지막으로, $P_{ij} = P(j\vert i)=X_{ij}/X_i$ 는 단어 $j$ 가 단어 $i$ 의 context에 등장할 확률이다.
예를 들어, $i=$ ice, $j=$ steam이라고 했을 때의 $P_{ik}/P_{jk}= P(k\vert i)/P(k\vert j)$ 를 알아보자.
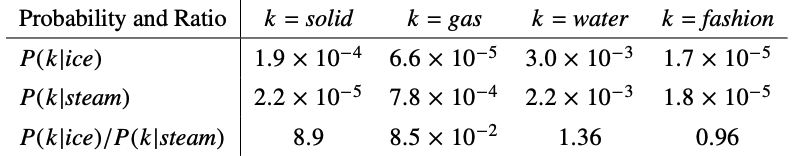
GloVe는 동시발생확률을 학습하는 것을 목표한다. 가장 간단하게 작성하면 GloVe는 함수 F의 모습을 가질 수 있다. ({w}는 단어의 임베딩벡터, \tilde{w}는 문맥 내 주변 단어의 임베딩 벡터이다.)
$k$ 가 solid일 때, ice와는 관련성이 높고
$\quad F(w_i, w_j, \tilde{w_k}) = {P_{ik} \over P_{jk}}$
벡터공간의 선형구조를 고려하여, 두 단어의 차이와 주변벡터를 내적하는 식으로 다시 표현할 수 있다.
$\quad F((w_i- w_j)^T \tilde{w_k}) = {P_{ik} \over P_{jk}}$
여기서 단어와 주변단어의 기준은 임의로 설정되었기 때문에 이 둘은 교환 가능해야한다는 특성이 있다. (즉, $i$ 와 $k$ 가 교환 가능해야한다.) 이러한 대칭성을 성립시키기 위해 다음과 같이 식을 유도할 수 있다.
$\quad F((w_i- w_j)^T \tilde{w_k}) = {F(w^T_i\tilde{w_k})\over F(w^T_j\tilde{w_k})}$
$\quad F(w^T_i\tilde{w_k}) = P_{ik} = {X_{ik} \over X_i}$
위 식을 풀면 $F$ 는 지수함수가 되기 때문에,
$\quad w^T_i\tilde{w_k} = log(P_{ik}) = log(X_{ik}) - log(X_i)$
여기에 $log(X_i)$ 을 bias term으로 대체하면,
\[\quad w^T_i \tilde{w_k} + b_i + \tilde{b}_k = log(X_{ik})\]와 같은 대칭적인 식을 얻을 수 있다.
이 식을 최소 제곱법의 형태로 치환하고 가중치 함수 $f(X_{ij})$ 를 도입하면, 다음과 같은 손실함수를 얻을 수 있다.
\[J = \sum^V_{i,j=1}(w^T_i\tilde{w_k}+b_j+\tilde{b_j}-logX_{ij})^2\]($V$ 는 단어사전의 크기이다)
가중치 함수 $f$ 는 다음과 같은 조건을 만족해야한다.
- $f(0)=0$
- $f(x)$ 는 non-decreasing함수여야 한다. (동시발생의 빈도가 매우 적은 경우 가중치가 너무 크면 안된다.)
- $f(x)$ 는 $x$ 값이 큰 경우 상대적으로 작아야한다. (동시발생의 빈도가 큰 경우 가중치가 너무 크면 안된다.)
따라서 이 조건들을 만족하는 다음과 같은 가중치 함수를 사용한다.
\[f(x)= \begin{cases} (x/x_{max})^\alpha & \text{if } x < x_{max} \\ \qquad 1 & \text{otherwise} \end{cases}\]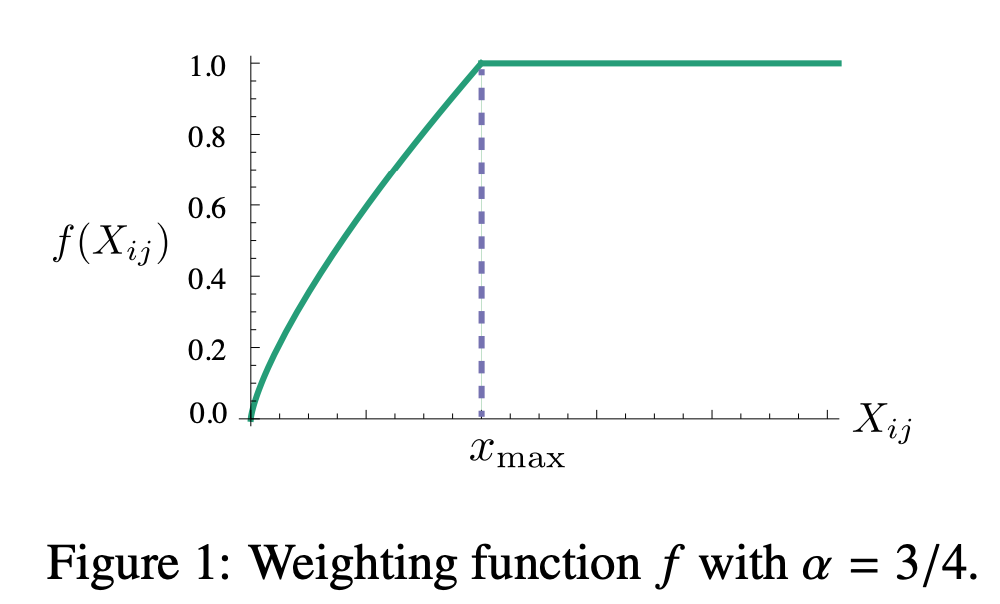
Relationship to Other Models
단어 벡터를 학습하는 비지도 학습은 대부분 코퍼스 내 동시발생의 통계를 기반하고 있다. 이 논문에서는 그 중에서도 최근에 나온 window기반 방법인 skip-gram과 ivLBL과 GloVe를 비교하였다.
먼저 skip-gram과 ivLBL모델은 단어 $i$ 의 문맥 내에서 단어 $j$ 가 등장할 softmax 확률 $Q_{ij}$ 을 학습시킨다.
\[\quad {Q}_{ij} = {exp(w^T_i\tilde{w_k})\over\sum^V_{k=1}exp(w^T_i\tilde{w_k})}\]이 로그 확률을 최대하기 위한 목적함수는 다음과 같다.
$\quad J = -\sum_{i\in corpus \ j \in context(i)}log\mathcal{Q}_{ij}$
(11)에서 각항에 대해 소프트맥스 정규화 계수를 구하는 것은 계산 비용이 많이 듭니
softmax계산은 비용이 많이 들기 때문에, 단어 $i$ 와 $j$ 가 같은 경우를 그룹지어 계산을 효율적으로 한다.
$J = -\sum^V_{i=1}\sum^V_{j=1}X_{ij}log\mathcal{Q}_{ij}$
이 식은 분포 $P_i$ 와 $Q_i$ 의 차이를 나타내는 Cross Entropy $H(P_i,Q_i)$ 로 다시 표현할 수 있다.
\[J = -\sum^V_{i=1} X_i\sum^V_{j=1}P_{ij}log\mathcal{Q}_{ij} = \sum^V_{i=1}X_iH(P_i,\mathcal{Q}_i)\]Cross entropy는 꼬리가 긴 확률분포의 경우 자주 발생하지 않는 사건에 대해 매우 큰 가중치를 부여하는 경우가 생길 수 있어 로그를 취한 $P$ 와 $Q$ 의 정규화 계수를 무시할 수 있는 최소제곱법을 사용한다.
\[\quad \hat{J} = \sum _{i,j}X_i(log\hat{P}_{ij}-log\hat{\mathcal{Q}}_{ij})^2 = \sum_{i,j}X_i(w^T_i\tilde{w}_j-logX_{ij})^2\]마지막으로 미리 정해진 가중치 값 대신 문맥 단어에 의존하지 않는 일반적인 가중치 함수를 이용하여 성능을 향상시켰다.
\[\quad \hat{J} = \sum_{i,j}f(X_{ij})(w^T_i\tilde{w}_j-logX_{ij})^2\]따라서 Skip-Gram과 ivLBL의 손실함수는 GloVe의 손실함수와 같은 형태임을 확인할 수 있다.
Experiments
Evaluation Methods
저자는 GloVe 모델을 3개의 task에 대해 평가했다.
Word Analogies
해당 task의 데이터셋은 semantic subset과 syntactic subset으로 이루어져있다.
- semantic question은 “Athen is to Greece as Berlin is to ___?”와 같이 사람이나 장소에 대해서 문맥적으로 비교하는 하여 빈칸을 맞추는 문제이다.
- syntactic question은 “Dance is dancing as fly is to ___?”와 같이 문법적인 비교를 통해 빈칸을 맞추는 문제이다.
Word Similarity
WordSim-353, MC, RG, SCWS, RW와 같은 word similarity 데이터셋으로 평가하였다.
Named Entity Recognition
CoNLL-2003 영문 벤치마크 데이터셋(사람, 장소, 조직 등의 개체명을 인식)으로 학습하고 CoNLL-03 test, ACE Phase2, ACE-2003, MUC7 Formal Run test 데이터셋으로 평가하였다.
Corpora and training details
다양한 크기를 가진 corpus 5개(2010 Wikipedia, 2010 Wikipedia, Gigaword5, Wikipedia2014, Common Crawl)를 학습했다. $x_{max}$ = 100, $\alpha$ = 3/4x 로 정하고, AdaGrad를 이용해 모델을 훈련했다. 300차원보다 작은 벡터에 대해서는 50 iteration, 반대의 경우는 100 iteration을 학습했다. 왼쪽에서 10개의 단어, 오른쪽에서 10개의 단어를 context로 사용했다.
다양한 SOTA 모델의 결과와, Word2Vec를 사용한 결과를 SVD를 이용한 다양한 baseline과 비교했다. Word2Vec에서는 상위 400,000개의 최빈 단어들과 context window size는 10으로 해서 Skip-gram와 CBOW모델로 60억개의 말뭉치를 학습했다. SVD baseline에 대해서는 10,000개의 최빈단어를 이용하여 각 단어가 얼마나 자주 발생하는 지에 대한 정보를 유지하는 truncated 행렬 $X_{trunc}$을 생성했다. 이 행렬의 singular vector로 “SVD”를 구성했고, $\sqrt{X_{trunc}}$의 SVD인 “SVD-S”와 $log{(1+X_{trunc})}$ 의 SVD인 “SVD-L” 또한 평가했다.
Results
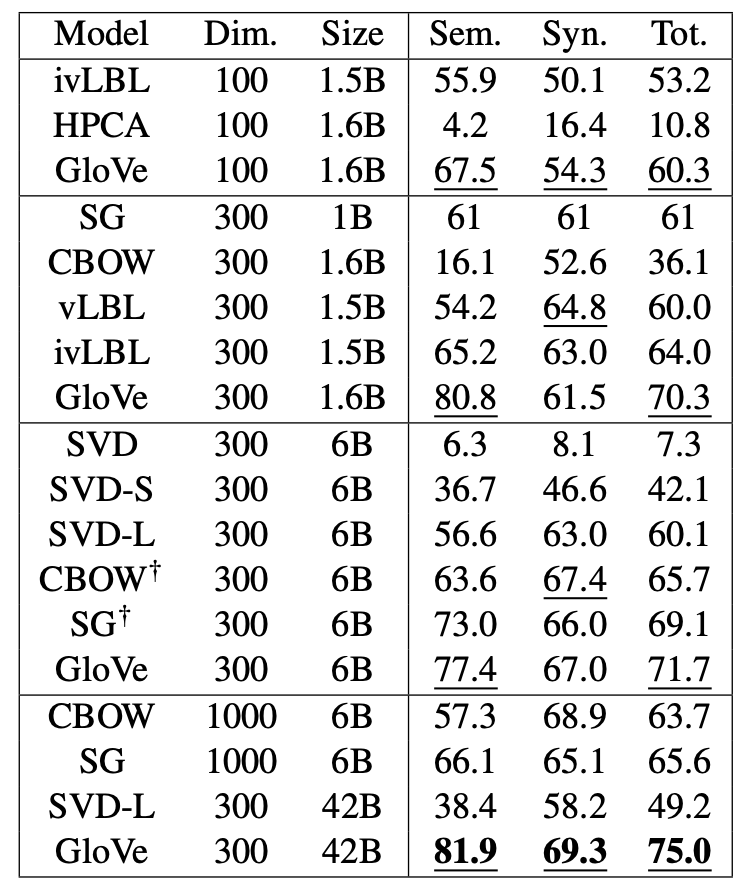
Word analogy task에 대해서 GloVe는 다른 baseline에 비해 뛰어난 성능을 보였다. 특히 42억개의 토큰 코퍼스에도 좋은 성능을 냈는데, SVD-L은 학습 코퍼스를 증가시켰음에도 성능이 떨어진 것을 확인할 수 있다. 이는 GloVe의 weighting scheme의 중요성을 내포하고 있다.
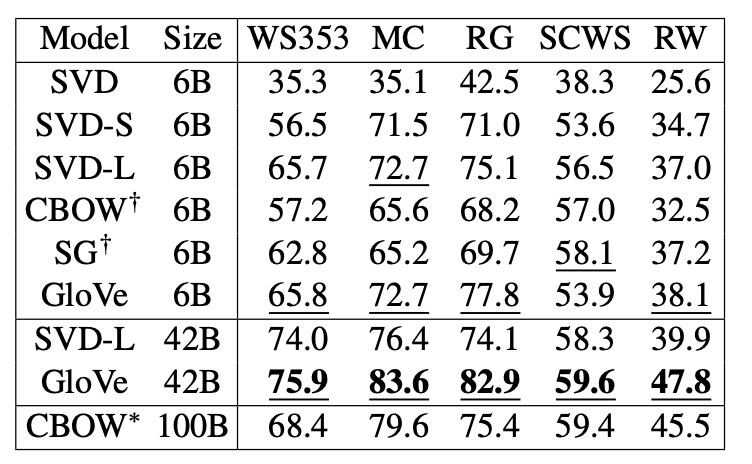
Word similarity task에 대해서 Spearman rank correlation을 계산한 결과이다. GloVe는 CBOW보다 작은 코퍼스를 사용했음에도 높은 성능을 보였다.
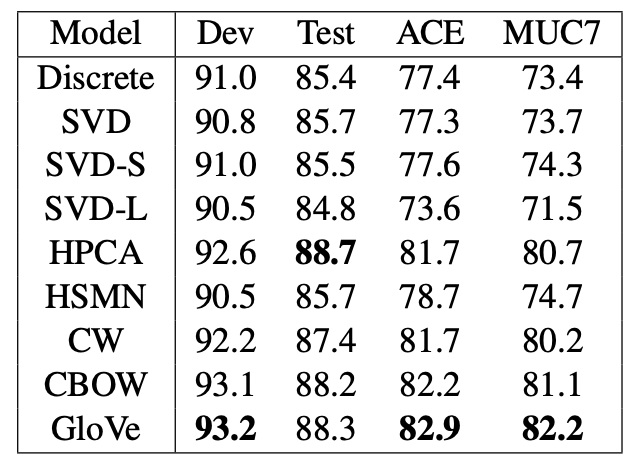
NERT task에 대해서 F1 score를 계산한 결과이다. GloVe가 CoNLL test를 제외한 데이터셋에 대해 더 높은 성능을 냈다.
Model Analysis
Vector Length and Context Size
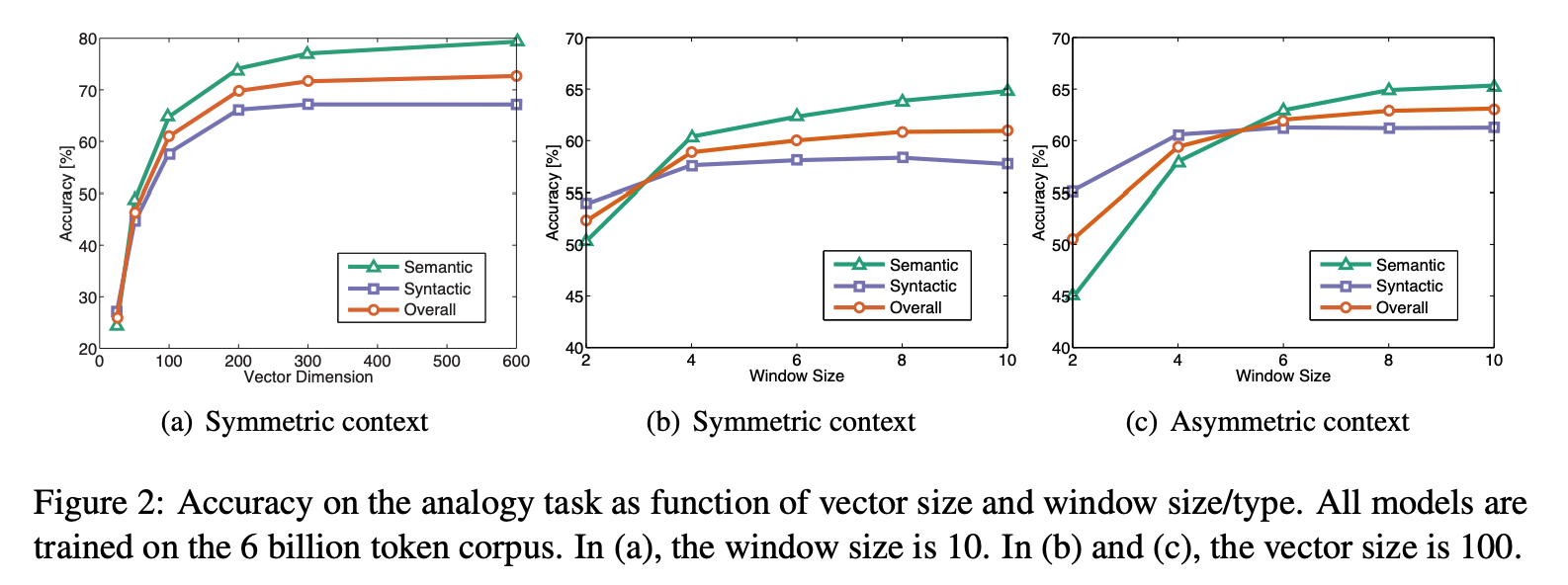
벡터 크기와 window의 크기, 타입에 따른 분석을 진행했다. 여기서 symmetric context는 window 크기가 양쪽으로 확장되는 것이고, asymmetric context는 window가 왼쪽으로 확장되는 것이다.
(a)를 통해 벡터의 크기가 200차원정도가 되면 성능이 수렴하는 것을 알 수 있다.
(b)와 (c)를 통해 syntactic은 작고 asymmetric한 window에 잘 작동하고, semantic은 큰 window에 잘 작동함을 알 수있다.
Corpus Size
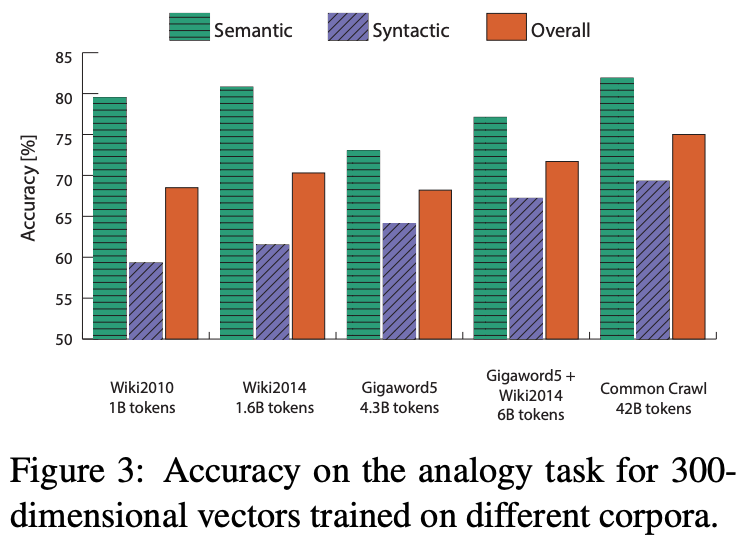
syntactic의 경우, 데이터에 상관없이 코퍼스 크기가 증가할수록 성능이 증가하고, semantic의 경우, Gigaword보다 Wiki로 학습한 성능이 더 높았다. 이는 Wikipedia가 포괄적인 정보가 많고, 새로운 지식들로 업데이트되는 특성을 가지고 있기 때문이라고 유추된다.
Run-time
동시발생행렬 $X$ 를 구성하는데에는 window 크기, 단어사전 크기, 코퍼스 크기 등 여러 요인이 작용하고, 모델을 학습시키는데는 벡터의 크기와 iteration 수에 영향을 받는다. 해당 논문의 실험환경에서는 각각 $X$ 구성에 85분, 학습시 1 iteration에 14분이 소요된다.
Comparison with Word2Vec 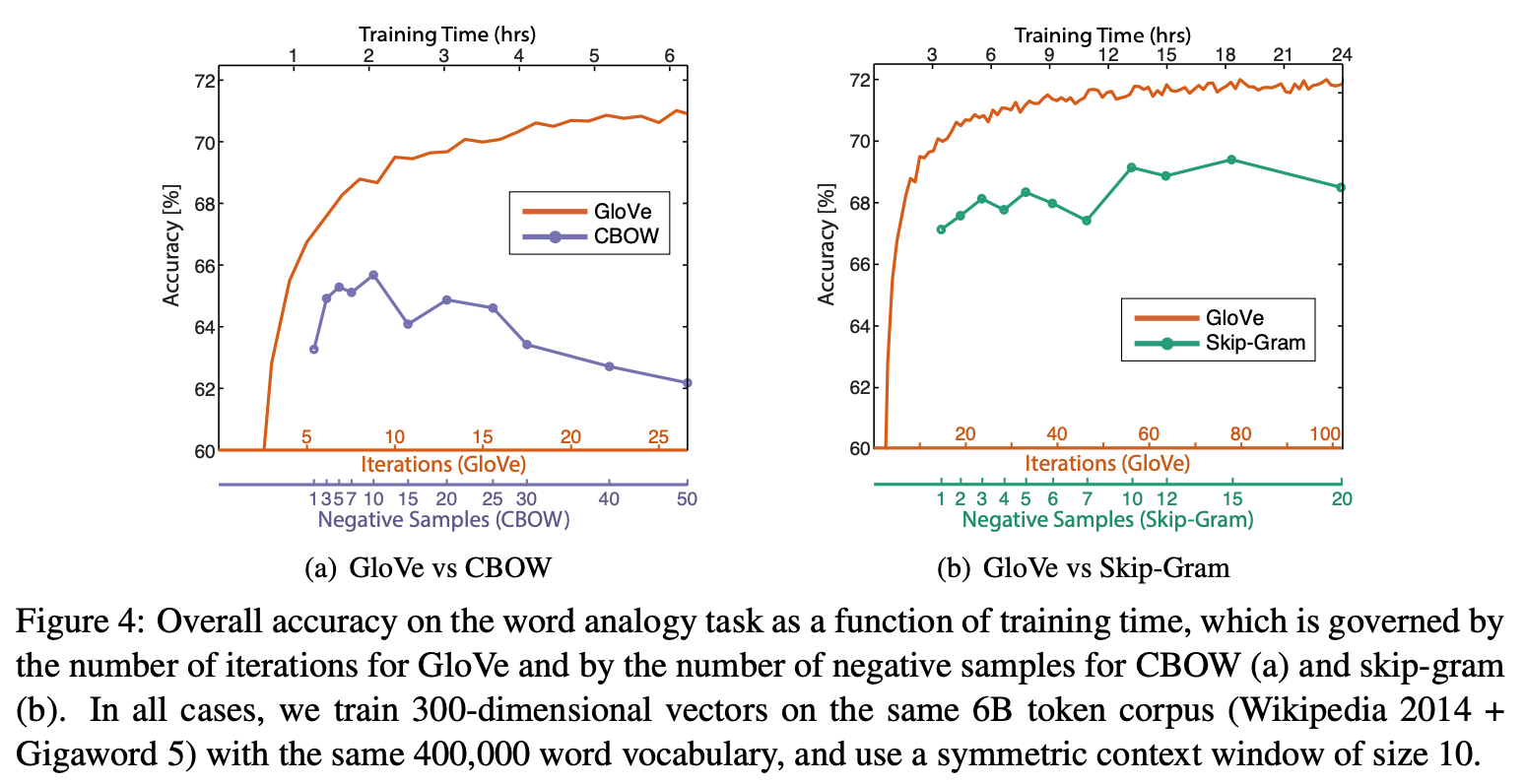
GloVe의 iteration 수, Word2Vec의 negative sample수에 따라 학습시간을 조절하여 성능을 확인한 결과이다. 학습시간이 길어질수록 성능이 향상되는 GloVe에 비해, Word2Vec은 성능이 떨어지는 경향을 보인다. 이는 Word2Vec의 negative sample 수가 많으면 target 확률 분포를 잘 예측하기 때문이라고 유추된다.
Conclusion
GloVe는 count 데이터의 이점을 살리면서 의미있는 선형 구조를 파악하는 모델이다. 단어의 represenation을 비지도로 학습하는 새로운 global log-bilinear 회귀 모델로, word analogy, word similarity, NER task에 대해 이전 모델 대비 우수한 성능을 달성했다.