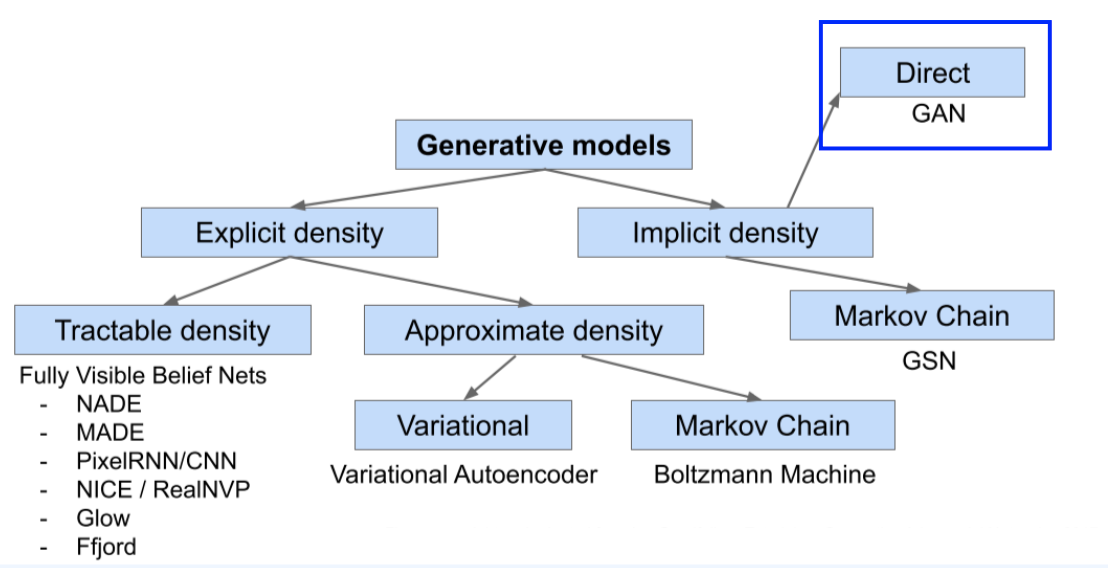
6. Evaluation of GANs
1. Evaluation of generative models
- 생성모델을 평가하는 것은 매우 까다로울 수 있다.
- Key question: 어떤 작업이 중요한가?
- 샘플링 / 생성
- 밀도 추정
- 압축
- 잠재적 표현 학습
생성 모델을 평가하는 것은 매우 어려울 수 있으며, 성공적인 평가를 위해서는 어떤 작업이 중요한지를 명확히 이해해야 한다. 주요 작업은 다양할 수 있으며, 주로 샘플링 또는 생성된 데이터의 품질, 데이터 분포의 밀도 추정, 데이터의 압축률, 잠재적 표현의 품질 등을 평가할 수 있다. 또한 여러 작업을 동시에 수행해야 할 수도 있으며, 이러한 작업들은 다양한 사용자 정의 하향 작업에 사용될 수 있다.
2. Sample Quality
- ground truth 를 알 수 없을때
- IS, FID, KID, Precision / Recall
- ground truth 를 알 수 있을 때
- MSE, PSNR, SSIM, LPIPS
- human evaluation
- Ranking vs Contrast
- Tools : AMT
생성된 이미지의 품질은 Ground Truth를 알 수 없을 때 또는 Ground Truth를 알 수 있을 때에 따라 다르게 측정 될 수 있다. Ground Truth를 알 수 없을 때에 대한 평가에서는 다양한 메트릭을 사용할 수 있으며, IS(Inception Score), FID(Fréchet Inception Distance), KID(Kernel Inception Distance), Precision / Recall 등이 포함될 수 있다. 반면 Ground Truth를 알 수 있을때에 대한 평가에서는 MSE, PSNR(Peak Signal-to-Noise Ratio), SSIM(Structural Similarity Index), LPIPS(Learned Perceptual Image Patch Similarity) 등의 메트릭을 사용할 수 있다. 또한 인간 평가를 통해 샘플의 품질을 평가할 수 있으며, 이때는 Ranking 또는 Contrast 를 통해 샘플을 비교하고 평가할 수 있다. 이러한 평가를 위해 Amazon Mechanical Turk와 같은 도구를 사용할 수 도 있다.
2-1. Unknown Ground Truth
- 생성된 이미지의 Ground Truth를 알 수 없음
- 데이터가 unpaired 상태
- 생성된 이미지를 직접적으로 실제 값 이미지와 비교하는것은 불가능
- 비대응 데이터는 매우 흔함
- Metrics: IS, FID, KID, Precision, Recall

생성된 이미지의 실제 값이 알려지지 않은 경우 생성된 이미지와 실제 값 이미지를 직접적으로 비교하는 것은 불가능 하다. 이러한 상황은 데이터가 비대응 상태인 경우에 흔히 발생한다. 이러한 경우, 생성된 이미지의 품질을 평가하기 위해 IS, FID, KID, Precision, Recall 등과 같은 메트릭을 사용할 수 있다.
2-1-1. Inception Scores (IS)
- 가정 1: 레이블이 지정된 데이터셋에서 훈련된 생성 모델의 샘플 품질을 평가
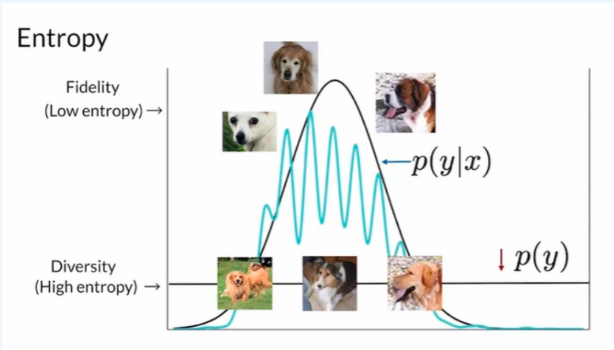
가정 2: 임의의 점 x에 대해 레이블 y를 예측하기 위한 좋은 확률적 분류기 c(y x) 가 있다고 가정 - 좋은 생성 모델에서 나오는 샘플이 두가지 기준을 충족시켜야 한다 : sharpness와 다양성
Sharpness (S)

- High sharpness는 classifier가 생성된 이미지에 대해 확신을 가지고 예측하는 것을 의미
즉 classifier의 예측 분포 c(y x)가 낮은 엔트로피를 가지고 있다.
Diversity(D)
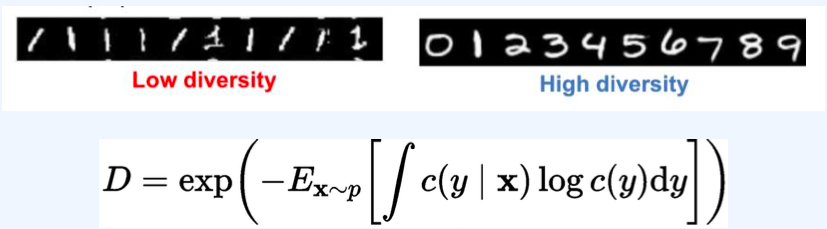
여기서 $c(y) = E_{x\backsim p} [c(y x)]$ 는 calssifier의 주변 예측 분포 - 높은 다양성은 c(y)가 높은 엔트로피를 가지고 있다는 것을 의미
Inception scores (IS)
- IS 는 sharpness와 다양성 두가지 기준을 메트릭으로 결합한 것 \(IS = D \times S\)
- 높은 IS는 더 나은 품질을 나타낸다
- classifier가 없는 경우 대규모 데이터셋(예: ImageNet 데이터셋에서 학습된 Inception Net)으로 학습된 classifier를 사용할 수 있다.
2-1-2. Fréchet Inception Distance (프레셰 인셉션 거리)
- 인셉션 점수(IS)는 $p_\theta$ 에서 샘플만 필요로 하며 원하는 데이터 분포 $p_{data}$ 를 직접 고려하지 않는다. (classifier를 통해서 암묵적으로만 고려)
FID는 $p_\theta$ 에서 샘플링된 데이터 포인트와 테스트 데이터셋 간(예: 사전 훈련 된 분류기에 의해 학습된)특성 표현에서의 유사성을 측정한다.
- FID 계산
- 먼저, 생성된 이미지와 실제 이미지를 특징 추출을 위해 미리 훈련된 인셉션 네트워크를 사용하여 각 이미지의 특성을 추출
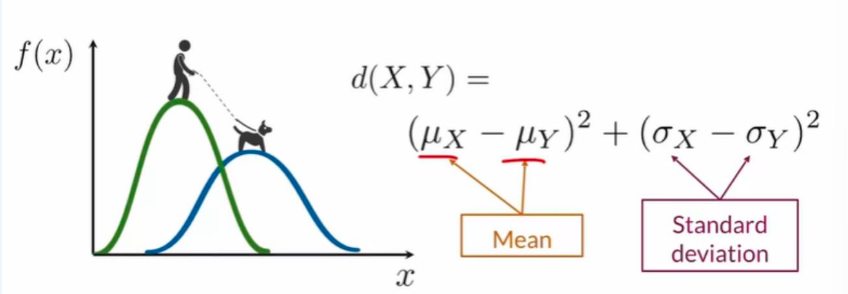
- 각 이미지의 특성을 사용하여 다변량 가우시안 분포를 추정합니다. 이때, 추출된 특성 벡터들을 모아서 해당 이미지의 다변량 가우시안 분포를 정의
- 생성된 이미지와 실제 이미지의 특성에 대해 추정된 다변량 가우시안 분포를 이용하여 각각의 평균(Mg, My)과 공분산(Σg, Σy)을 계산
- 계산된 평균과 공분산을 사용하여 두 다변량 가우시안 분포 간의 Fréchet distance를 계산합니다. Fréchet distance는 두 가우시안 분포의 평균 사이의 거리와 공분산 사이의 거리를 고려하여 계산
- Fréchet distance가 FID로 사용되며, 일반적으로 다음과 같은 공식을 사용하여 계산
| 여기서 | ⋅ | 은 벡터의 유클리드 노름을 나타내며, Tr은 행렬의 trace (대각 요소의 합)를 나타낸다. |
FID가 작을수록 생성된 이미지와 실제 이미지 간의 유사성이 높다고 해석된다. 따라서 품질이 높은 생성 모델은 FID가 낮은 값을 갖게 된다.
2-1-3. Kernel Inception Distance
- MMD(Maximum Mean Discrepancy)란?
- MMD는 두 확률분포 pp와 qq에서 샘플을 비교하는 두 샘플 검정 통계량이다. 이는 p와 q 각각에서 샘플링한 데이터의 모멘트(평균, 분산 등) 차이를 계산함으로써 이루어진다. 직관적으로, MMD는 p 내의 샘플들과 q 내의 샘플들이 서로 얼마나 “유사한지”, 그리고 그들이 p와 q의 혼합에서 나온 샘플들과 얼마나 유사한지를 비교합니다.
- MMD를 이용하면 두 분포 사이의 차이를 정량화할 수 있으며, 이는 두 데이터 집합이 같은 분포에서 왔는지를 테스트하는 데 사용될 수 있다.
- KID(Kernel Inception Distance)란?
- KID는 MMD를 분류기(예: 인셉션 네트워크)의 특성 공간에서 계산하는 방법이다. 즉, 원래 데이터 공간이 아닌, 분류기를 통해 변환된 특성 공간에서 두 분포의 유사도를 측정한다. 이 접근 방식은 이미지 생성 모델의 성능 평가에서 자주 사용되며, 특히 생성된 이미지와 실제 이미지 사이의 차이를 정량화하는 데 유용하다.
- FID(Fréchet Inception Distance) 대비 KID
- 편향성: FID는 항상 양수 값을 가지는 경향이 있어 편향될 수 있다. 반면, KID는 무편향 추정치를 제공한다.
- 계산 복잡도: FID는 $O(n)$ 시간에 평가될 수 있는 반면, KID의 계산은 보통 더 복잡하다. KID는 더 정밀한 평가를 위해 추가 계산이 필요할 수 있으며, 이는 $O(n^2)$ 시간 복잡도를 가질 수 있다. (정확한 복잡도는 구현 방법에 따라 달라진다.)
\(\text{MMD}^2(p, q) = \mathbb{E}_{x, x' \sim p}[K(x, x')] + \mathbb{E}_{y, y' \sim q}[K(y, y')] - 2\mathbb{E}_{x \sim p, y \sim q}[K(x, y)]\) 위 MMD의 공식은 커널 함수를 사용하여 두 분포 $p$와 $q$ 사이의 거리를 측정하는 방식을 나타낸다. 여기서 $K(x, x’)$는 커널 함수로, 두 샘플 $x$와 $x’$ 사이의 유사도를 측정한다.
여기서:
- $\mathbb{E}_{x, x’ \sim p}[K(x, x’)]$는 분포 $p$에서 뽑은 두 샘플 $x, x’$ 간의 커널 함수 값의 기대치
- $\mathbb{E}_{y, y’ \sim q}[K(y, y’)]$는 분포 $q$에서 뽑은 두 샘플 $y, y’$ 간의 커널 함수 값의 기대치
- $\mathbb{E}_{x \sim p, y \sim q}[K(x, y)]$는 분포 $p$에서 뽑은 샘플 $x$와 분포 $q$에서 뽑은 샘플 $y$ 간의 커널 함수 값의 기대치
이 공식은 두 분포 $p$와 $q$에서 샘플링한 데이터 포인트들 간의 유사도를 커널 함수를 통해 측정하고, 이를 바탕으로 두 분포 사이의 거리(또는 차이)를 계산한다. 커널 함수 $K$는 보통 가우시안 커널(Gaussian kernel) 또는 다른 유사도 측정 함수를 사용할 수 있으며, 이 선택은 분석하고자 하는 데이터의 특성에 따라 달라질 수 있다.
이 방식을 사용하면 두 분포 사이의 차이를 더욱 세밀하게 측정할 수 있으며, 특히 비선형 관계를 포착하는 데 있어 유리하다. MMD는 기계학습, 특히 도메인 적응(domain adaptation)과 같은 분야에서 데이터 분포의 차이를 분석할 때 유용하게 사용된다.
2-1-4 : Precision and Recall
- 정밀도(Precision)
- 신뢰도와 관련이 있다.
- 실제 이미지와 생성된 이미지 간의 중첩을 살펴보고 Generator가 생성한 추가적인 부분(중첩 되지 않은 부분)에 대해서도 고려한다.
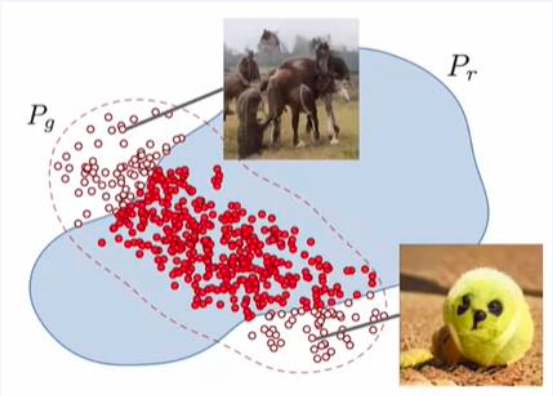
정밀도는 생성된 이미지가 실제 이미지와 얼마나 중첩되는지를 나타낸다. 이는 생성된 이미지가 실제 이미지와 얼마나 유사한지를 측정하는 데 사용될 수 있다. 정밀도가 높을수록 생성된 이미지가 실제 이미지와 더 유사하다고 볼 수 있다. 하지만 생성된 이미지가 충첩되지 않는 추가적인 부분을 생성하지 않는것도 중요하다. Generator가 중첩되지 않는 추가적인 부분을 생성하지 않고 실제 이미지와 유사한 이미지를 생성할 때 정밀도는 높아진다.
- Recall
- 다양성과 관련이 있다.
- 실제 이미지와 생성된 이미지의 중첩을 살펴보고 Generator가 모델링하지 못하는 모든 실제 이미지에 대해 고려한다.
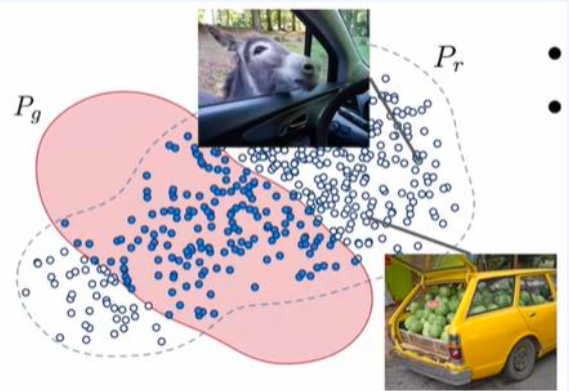
재현율은 생성된 이미지가 실제 이미지와 얼마나 많은 부분을 포함하는지를 나타낸다. 이는 생성된 이미지가 다양성을 갖고 있는지를 평가하는 데 사용될 수 있다. 재현율이 높을수록 생성된 이미지가 실제 이미지와 많은 부분을 포함하고 있음을 의미한다. 생성된 이미지와 실제 이미지 간의 교집합이 많아질수록 높아진다.
2-1-4. Evaluating sample quality - Best practices (샘플 품질 평가 - 모범 사례)
1
2
Are GANs Created Equal? A Large-Scale Study
GAN(Generative Adversarial Networks)은 생성 모델의 강력한 하위 클래스입니다. 많은 흥미로운 GAN 알고리즘을 이끌어낸 매우 풍부한 연구 활동에도 불구하고, 어떤 알고리즘이 다른 것보다 더 잘 수행되는지 평가하는 것은 여전히 매우 어렵습니다. 우리는 최신 모델 및 평가 지표에 대한 중립적이고 다면향적인 대규모 경험적 연구를 수행합니다. 대부분의 모델이 충분한 하이퍼파라미터 최적화와 무작위 재시작으로 유사한 점수를 얻을 수 있다는 사실을 발견했습니다. 이는 개선 사항이 근본적인 알고리즘 변경보다는 더 높은 계산 예산과 튜닝에서 나올 수 있다는 것을 시사합니다. 현재 지표의 일부 한계를 극복하기 위해 정밀도와 재현율을 계산할 수 있는 여러 데이터 세트를 제안합니다. 우리의 실험 결과는 미래의 GAN 연구가 보다 체계적이고 객관적인 평가 절차를 기반으로 이루어져야 한다는 것을 시사합니다.
- 기본 설정 조율에 시간을 할애하라.
- 아키텍쳐, 학습률, 최적화기 등의 기본 설정을 조정하는데 시간을 투자하면, 놀랍도록 좋은 성능을 발휘할 수 있다. 처음에 예상했던 것 보다 훨씬 좋은 결과를 얻을 수 있으므로, 성능이 기대에 못미친다고 해서 실망하기 보다는, 기본 설정을 잘 조율하면 얼마나 잘 작동하는지 놀랄것이다.
- 재현성을 위한 랜덤 시드 사용.
- 험의 재현성을 확보하기 위해서는 랜덤 시드를 사용하는 것이 중요하다. 랜덤 시드를 고정하면 동일한 실험을 반복할 때마다 동일한 결과를 얻을 수 있어, 연구 결과의 신뢰성을 높일 수 있다.
- 다양한 랜덤 시드에 대한 결과 평균과 신뢰 구간 보고
- 실험 결과는 랜덤 시드에 따라 달라질 수 있으므로, 여러 개의 랜덤 시드를 사용하여 실험을 반복하고, 그 결과를 평균내어 보고하는 것이 좋다. 또한, 결과의 변동성을 나타내기 위해 신뢰 구간을 함께 제공하는 것이 유용하다다. 이렇게 하면 연구 결과의 일반성과 신뢰도를 더욱 강화할 수 있다.
2-2. Known Ground Truth
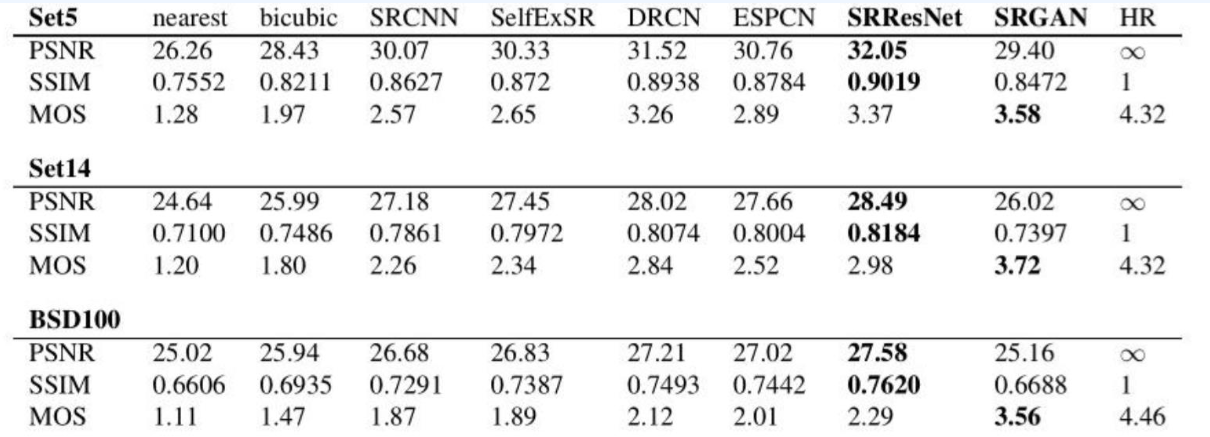
생성된 이미지의 기준 진리(Ground Truth)를 알고 있는 경우, 데이터는 짝을 이루며, 생성된 이미지를 기준 진리 이미지와 직접 비교할 수 있다. 이러한 상황에서 사용할 수 있는 메트릭은 MSE(평균 제곱 오차), PSNR(피크 신호 대 잡음비), SSIM(구조적 유사도) 등이다. 예를 들어, SRGAN(초해상도 생성적 적대 신경망)과 같은 모델에서 이러한 방식이 사용된다.
- MSE (Mean Squared Error, 평균 제곱 오차): 이 메트릭은 예측된 값과 실제 값 사이의 차이를 제곱한 후 평균을 낸 것이다. 낮은 MSE 값은 예측된 이미지가 기준 진리 이미지와 매우 유사함을 의미한다.
- PSNR (Peak Signal-to-Noise Ratio, 피크 신호 대 잡음비): PSNR은 신호가 가질 수 있는 최대 파워 대비 잡음의 파워 비율을 로그 스케일로 표현한 것이다. 이미지 처리에서 PSNR이 높을수록 원본 이미지와 생성된 이미지 사이의 차이가 작음을 의미한다.
- SSIM (Structural Similarity Index, 구조적 유사도 지수): SSIM은 두 이미지의 구조적 유사성을 측정하는 지표이다. 이는 밝기, 대비, 구조 등 세 가지 측면에서 두 이미지를 비교한다. SSIM 값이 1에 가까울수록 두 이미지가 유사하다는 것을 의미한다.
이러한 메트릭들은 생성된 이미지가 얼마나 잘 기준 진리 이미지를 재현하는지를 정량적으로 평가할 때 사용된다. 알려진 기준 진리를 가진 경우, 이러한 직접 비교를 통해 모델의 성능을 객관적으로 평가할 수 있다.
- SRGAN (Super-Resolution Generative Adversarial Network, 초해상도 생성적 적대 신경망): 사진처럼 사실적인 단일 이미지 초해상도를 생성적 적대 신경망을 사용하여 얻는 기술이다.
- 주어진 저해상도 입력 이미지로부터 고해상도 대응 이미지를 얻기 위함
- 생성적 적대 신경망(Generative Adversarial Networks, GANs)이 이를 실현할 수 있다.
- 해당 고해상도 대응 이미지를 생성한다.
SRGAN은 저해상도 이미지를 입력으로 받아, 이를 고해상도로 변환하는 모델로 이 과정에서 생성적 적대 신경망을 활용하여, 저해상도 이미지에 없는 디테일을 추론하고 추가함으로써, 최종적으로는 사진처럼 사실적인 고해상도 이미지를 생성한다. 이러한 기술은 이미지 복원, 의료 이미징, 위성 이미지 향상 등 다양한 분야에서 응용될 수 있다.
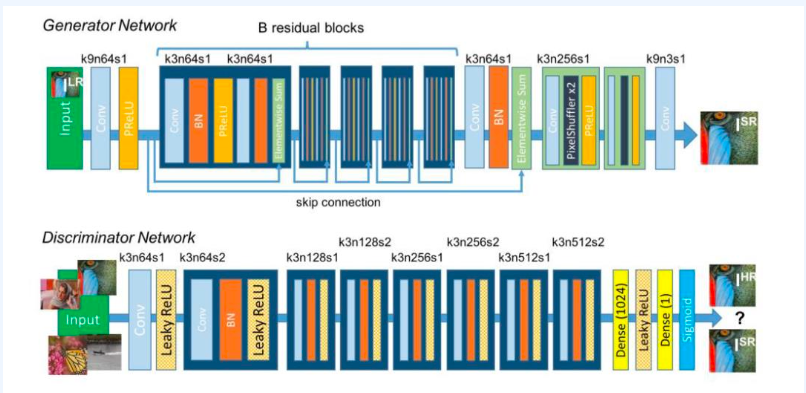

2-2-1. Mean Squared Error(MSE)
MSE는 다음과 같이 정의된다. \(\text{MSE} = \frac{1}{m} \sum_{i=1}^{m} (x_i - y_i)^2\) 여기서 $x_i$ , $y_i$는 이미지 쌍의 픽셀 값입니다.
- MSE는 이미지 쌍의 유사성을 평가할 수 있다.
- 범위는 $[0, \infty)$
- 숫자가 작을수록 두 이미지는 더 유사하며, 따라서 복원이 더 잘 된 것이다.
- 그러나 픽셀별 오차 측정에는 한계가 있다(논의 필요).
- 숫자가 작다 하더라도 인지적으로 좋지 않을 수 있다.
2-2-2. Peak Signal to Noise Ratio(PSNR)
1
피크 신호 대 잡음비 (PSNR)
PSNR은 다음과 같이 정의된다. \(\text{PSNR} = 10 \log_{10} \left( \frac{\text{데이터의 최대 가능 파워}}{\text{잡음의 파워}} \right)\) \(\text{PSNR} = 10 \log_{10} \left( \frac{R^2}{\text{MSE}(x, y)} \right)\)
- 데이터의 최대 가능 파워 대 잡음의 파워를 의미한다.
- uint8 데이터의 경우, 최대 가능 파워는 255이다.
- 부동 소수점(float) 데이터의 경우, 최대 가능 파워는 1이다.
- 숫자가 클수록 이미지의 품질이 더 좋다는 것을 의미한다.
2-2-3. Structure Similarity Index Measure (SSIM)
1
구조적 유사도 지수 측정
\(\text{SSIM} (x, y) = \left[ \text{Luminance} (x, y) \right]^\alpha \cdot \left[ \text{Contrast} (x, y) \right]^\beta \cdot \left[ \text{Structural} (x, y) \right]^\gamma\) $\text{Luminance} (x, y) = \frac{2\mu_x\mu_y + C_1}{\mu_x^2 + \mu_y^2 + C_1}$
$\text{Contrast} (x, y) = \frac{2\sigma_x\sigma_y + C_2}{\sigma_x^2 + \sigma_y^2 + C_2}$
$\text{Structural} (x, y) = \frac{\sigma_{xy} + C_3}{\sigma_x\sigma_y + C_3}$
- 상대적 밝기, 대비, 구조의 곱
- 범위는 $[0, 1]$
- 숫자가 클수록 이미지의 품질이 더 좋다는 것을 의미
2-2-4. Learned Perceptual Image Patch Similarity(LPIPS)
1
학습된 지각적 이미지 패치 유사도 (LPIPS)
- 딥 피처(deep features)는 이전의 모든 메트릭을 큰 차이로 능가
- 지각적 유사도는 깊은 시각적 표현들 간에 공유되는 등장하는 속성
- LPIPS가 높을수록 샘플 품질이 더 좋음을 의미
- 딥 네트워크의 지각적 메트릭으로서의 유효성을 반영
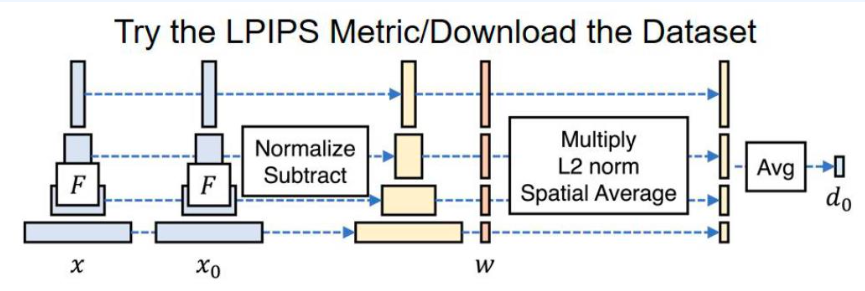
2-3. Human evaluation
- SRGAN에서 언급된 바와 같이, 위에서 설명된 기계 평가에는 한계가 있다.
- 지각적 품질을 정확하게 평가하기 위해서는 인간 평가가 더 나은 선택일수 있다.
- Ranking: 이미지 그룹에 대한 순위를 매기도록 인간에게 평가 시킨다.
- Contrast: 두 이미지 쌍 중 더 나은 것을 선택하도록 인간에게 평가 시킨다.
- Amazon Mechanical Turk
2-4. Sampling and Truncation (샘플링과 절단)
- 가짜 이미지 샘플링
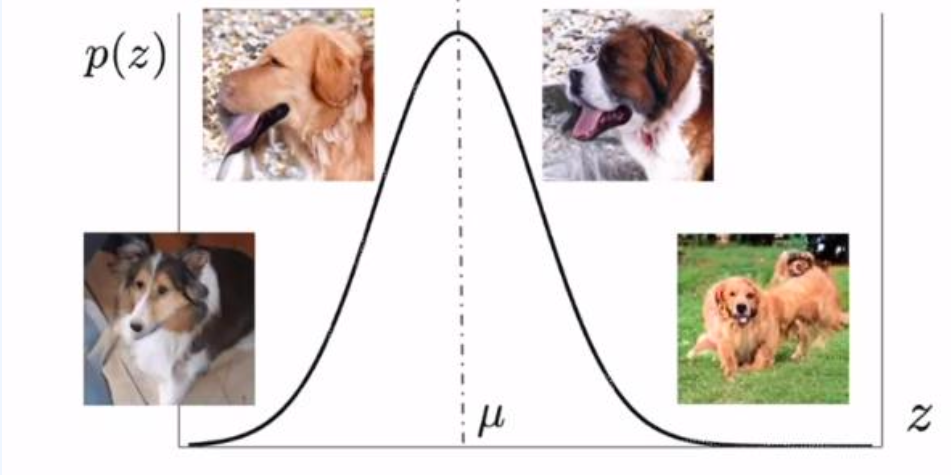
- 절단 트릭
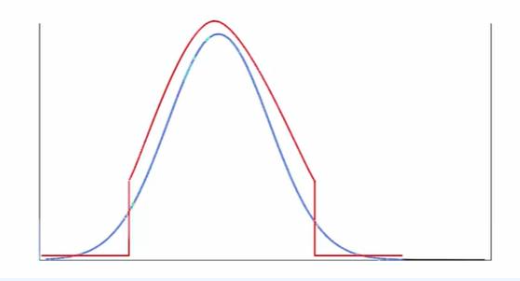
 그림 2: (a) 절단을 증가시키는 효과. 왼쪽에서 오른쪽으로, 임계값이 2, 1, 0.5, 0.04로 설정된다. (b) 조건이 좋지 않은 모델에 절단을 적용했을 때 발생하는 포화 아티팩트.
그림 2: (a) 절단을 증가시키는 효과. 왼쪽에서 오른쪽으로, 임계값이 2, 1, 0.5, 0.04로 설정된다. (b) 조건이 좋지 않은 모델에 절단을 적용했을 때 발생하는 포화 아티팩트.
3. Density estimation / Compression
1
밀도 추정 / 압축 - VAEs(변분 오토인코더)의 경우, 증거 하한(Evidence Lower Bounds, ELBO)을 로그 우도와 비교할 수 있다. 그렇다면 GANs(생성적 적대 신경망)는 어떨까? 샘플만 가지고 있을 때 모델의 우도를 어떻게 추정할 수 있을까? - 일반적으로, 샘플로부터 밀도 함수의 무편향 추정은 불가능하다. - 근사 방법이 필요한데 샘플만을 이용한 커널 밀도 추정을 사용할 수 있다.
4. Evaluation latent representations
1
잠재 표현 평가하기
- “좋은” 잠재 표현을 학습한다는 것은 무엇을 의미할까?
- 하류 작업(downstream task)에 대해서는, 해당 성능 메트릭(예: 준지도 학습의 정확도, 노이즈 제거의 복원 품질 등)을 기반으로 표현을 평가할 수 있다.
- 비지도 학습 과제의 경우, 모든 상황에 맞는 단일 해결책은 없다.
- 비지도 잠재 표현을 평가하기 위해 일반적으로 사용되는 세 가지 개념:
- 클러스터링
- 압축
- 분리(Disentanglement)
4-1. Clustering
- 어떤 의미론적 속성을 기반으로 점들을 그룹화할 수 있는 표현은 잠재적으로 유용할 수 있다(예: 준지도 분류).
- 클러스터는 생성 모델의 잠재 공간에서 k-평균 또는 다른 알고리즘을 적용하여 얻을 수 있다.
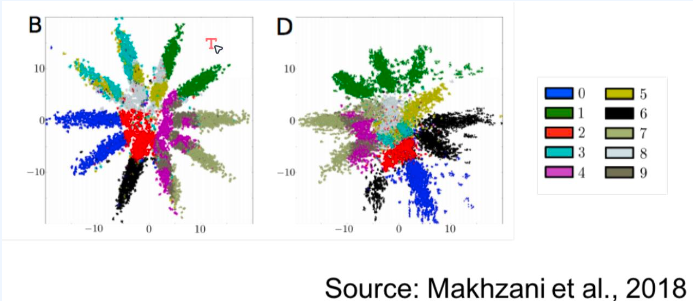
- MNIST 숫자에 대해 두 생성 모델이 학습한 2D 표현으로, 색상은 진짜 라벨을 나타낸다. 어느 것이 더 나을까? B or D?
4-2. Disentanglement (분리)
- 직관적으로, 우리는 관측된 데이터의 독립적이고 해석 가능한 속성을 분리할 수 있는 표현을 원한다.
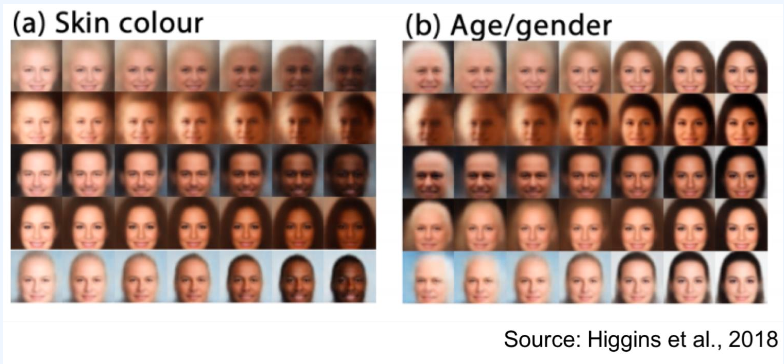
- 생성된 데이터의 속성에 대한 사용자 제어를 제공한다.
- $Z_1$이 고정되었을 때, 생성된 객체의 크기는 절대 변하지 않는다
- $Z_1$이 변경되었을 때, 변경은 생성된 객체의 크기에만 제한된다.
4-3. Disentanglement
- 많은 양적 평가 메트릭들이 있다.
- Beta-VAE 메트릭 (Higgins et al., 2017): 고정된 변화 요인을 예측하는 선형 분류기의 정확도
- 다른 많은 메트릭들 : Factor-VAE 메트릭, 상호 정보 간격(Mutual Information Gap), SAP 점수, DCI 분리, 모듈성(Modularity) 등.
- 이러한 메트릭들의 구현체는 분리 라이브러리(Disentanglement lib)에서 확인할 수 있다.
- 추가적인 가정 없이 생성 요인을 이론적으로 분리하는 것은 불가능하다.
5. Summary
생성 모델의 양적 평가는 도전적인 작업이다.
하류 응용 프로그램의 경우, 응용 프로그램 특정 메트릭에 의존할 수 있다. 비지도 평가의 경우, 메트릭은 최종 목표에 따라 크게 달라질 수 있다: 밀도 추정, 샘플링, 잠재 표현
구현
Evaluation GANs : Frechet Inception Distance(FID) and Inception Score(IS) Metrics
1
2
3
4
5
6
7
8
9
10
11
import torch
import torchvision
import ignite
print(*map(lambda m: ": ".join((m.__name__, m.__version__)), (torch, torchvision, ignite)), sep="\n")
"""
torch: 2.2.0+cu118
torchvision: 0.17.0+cu118
ignite: 0.4.13
"""
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import os
import logging
import matplotlib.pyplot as plt
import numpy as np
from torchsummary import summary
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as dset
import torchvision.utils as vutils
from ignite.engine import Engine, Events
import ignite.distributed as idist
Reproductibility and logging details
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# PyTorch Ignite의 유틸리티 함수 manual_seed를 사용하여 난수 생성기의 시드를 설정
# 이는 실험의 재현성을 보장하기 위해 사용되며, 모든 초기화된 난수 생성기가 동일한 시퀀스의 난수를 생성하도록 한다.
ignite.utils.manual_seed(999)
# PyTorch Ignite의 로거 설정 유틸리티 함수 setup_logger를 사용하여 특정 Ignite 모듈의 로깅 레벨을 설정
# 이 경우 'ignite.distributed.auto.auto_dataloader'라는 이름의 로거의 로깅 레벨을 WARNING으로 설정
# 로깅 레벨을 WARNING으로 설정함으로써, 이 로거는 WARNING, ERROR, CRITICAL 레벨의 로그 메시지만 출력하게된다.
# INFO 또는 DEBUG 레벨의 로그 메시지는 출력되지 않는다.
# 이는 로그의 양을 줄이고 중요한 경고나 에러 메시지에만 집중할 수 있도록 도와준다.
ignite.utils.setup_logger(name="ignite.distributed.auto.auto_dataloader", level=logging.WARNING)
# ignite.distributed.launcher.Parallel'라는 이름의 로거에 대해서도 로깅 레벨을 WARNING으로 설정
# 이 로거는 분산 학습을 실행할 때 사용되는 Parallel 유틸리티와 관련된 로그를 관리
ignite.utils.setup_logger(name="ignite.distributed.launcher.Parallel", level=logging.WARNING)
Dataset and transformation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
image_size = 64
data_transform = transforms.Compose(
[
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
)
train_dataset = dset.ImageFolder(root="data/celeba", transform=data_transform)
# `torch.utils.data.Subset`: 이 클래스는 주어진 인덱스에 해당하는 데이터만 포함하는 데이터셋의 부분집합을 생성한다.
# 첫 번째 인자로는 원본 데이터셋(`train_dataset`)이 들어가고, 두 번째 인자로는 부분집합을 구성하는 원소의 인덱스를 나열한 배열이 들어간다.
# `train_dataset`에서 처음 3000개의 샘플을 선택하는 데 사용된다.
test_dataset = torch.utils.data.Subset(train_dataset, torch.arange(3000))
DataLoading
분산 환경에서 작동하도록 데이터로더를 구성하는 방법 Ignite는 DDP 지원의 일부로 분산 데이터로딩을 지원한다. 이를 처리하기 위해 ‘idist’ 는 자동으로 데이터를 프로세스에 분산하는 도우미 ‘auto_dataloader’를 제공한다.
참고 : 분산 데이터 로딩은 Distributed Data Parallel(DDP) 튜토리얼 참고
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
batch_size = 128
train_dataloader = idist.auto_dataloader(
train_dataset,
batch_size=batch_size,
num_workers=8,
shuffle=True,
drop_last=True,
)
test_dataloader = idist.auto_dataloader(
test_dataset,
batch_size=batch_size,
num_workers=8,
shuffle=False,
drop_last=True,
)
1
2
3
4
5
6
7
real_batch = next(iter(train_dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0][:64], padding=2, normalize=True).cpu(),(1,2,0)))
plt.show()
Models for GAN
Generator
1
latent_dim = 150
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class Generator3x64x64(nn.Module):
def __init__(self, latent_dim):
super(Generator3x64x64, self).__init__()
self.model = nn.Sequential(
nn.ConvTranspose2d(in_channels=latent_dim, out_channels=512,
kernel_size=4, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
# state size. 512 x 4 x 4
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
# state size. 256 x 8 x 8
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
# state size. 128 x 16 x 16
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
# state size. 64 x 32 x 32
nn.ConvTranspose2d(64, 3, 4, 2, 1, bias=False),
nn.Tanh()
# final state size. 3 x 64 x 64
)
def forward(self, x):
x = self.model(x)
return x
분산 모델은 특정 설정이 필요하므로 ‘idist’ 는 이를 처리하기 위해 auto_model 함수를 제공
1
netG = idist.auto_model(Generator3x64x64(latent_dim))
모델은 idist 에 의해 자동으로 최적의 장치로 이동
1
2
3
4
5
idist.device()
"""
device(type='cuda')
"""
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
summary(netG, (latent_dim, 1, 1))
"""
분산 환경에서 데이터 병렬 처리를 수행하기 위해 각 프로세스가 독립적으로 모델의 복사본을 가지고 있어 각 프로세스는 전체 모델을 가지고 있게 되며,
이에 따라 모델 구조가 반복되어 나타남. 이것은 분산 환경에서의 데이터 병렬 처리에 필요한 구조
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
ConvTranspose2d-1 [-1, 512, 4, 4] 1,228,800
BatchNorm2d-2 [-1, 512, 4, 4] 1,024
ReLU-3 [-1, 512, 4, 4] 0
ConvTranspose2d-4 [-1, 512, 4, 4] 1,228,800
ConvTranspose2d-5 [-1, 256, 8, 8] 2,097,152
BatchNorm2d-6 [-1, 256, 8, 8] 512
ReLU-7 [-1, 256, 8, 8] 0
BatchNorm2d-8 [-1, 512, 4, 4] 1,024
ReLU-9 [-1, 512, 4, 4] 0
ConvTranspose2d-10 [-1, 128, 16, 16] 524,288
BatchNorm2d-11 [-1, 128, 16, 16] 256
ReLU-12 [-1, 128, 16, 16] 0
ConvTranspose2d-13 [-1, 256, 8, 8] 2,097,152
BatchNorm2d-14 [-1, 256, 8, 8] 512
ReLU-15 [-1, 256, 8, 8] 0
ConvTranspose2d-16 [-1, 64, 32, 32] 131,072
BatchNorm2d-17 [-1, 64, 32, 32] 128
ReLU-18 [-1, 64, 32, 32] 0
ConvTranspose2d-19 [-1, 3, 64, 64] 3,072
Tanh-20 [-1, 3, 64, 64] 0
Generator3x64x64-21 [-1, 3, 64, 64] 0
ConvTranspose2d-22 [-1, 128, 16, 16] 524,288
BatchNorm2d-23 [-1, 128, 16, 16] 256
ReLU-24 [-1, 128, 16, 16] 0
ConvTranspose2d-25 [-1, 64, 32, 32] 131,072
BatchNorm2d-26 [-1, 64, 32, 32] 128
ReLU-27 [-1, 64, 32, 32] 0
ConvTranspose2d-28 [-1, 3, 64, 64] 3,072
Tanh-29 [-1, 3, 64, 64] 0
Generator3x64x64-30 [-1, 3, 64, 64] 0
================================================================
Total params: 7,972,608
Trainable params: 7,972,608
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 6.19
Params size (MB): 30.41
Estimated Total Size (MB): 36.60
----------------------------------------------------------------
"""
Discriminator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class Discriminator3x64x64(nn.Module):
def __init__(self):
super(Discriminator3x64x64, self).__init__()
self.model = nn.Sequential(
# input is 3 x 64 x 64
nn.Conv2d(3, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. 64 x 32 x 32
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
# state size. 128 x 16 x 16
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
# state size. 256 x 8 x 8
nn.Conv2d(256, 512, 4, 2, 1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
# state size. 512 x 4 x 4
nn.Conv2d(512, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
x = self.model(x)
return x
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
netD = idist.auto_model(Discriminator3x64x64())
summary(netD, (3, 64, 64))
"""
2024-02-12 15:19:10,096 ignite.distributed.auto.auto_model INFO: Apply torch DataParallel on model
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 32, 32] 3,072
LeakyReLU-2 [-1, 64, 32, 32] 0
Conv2d-3 [-1, 64, 32, 32] 3,072
LeakyReLU-4 [-1, 64, 32, 32] 0
Conv2d-5 [-1, 128, 16, 16] 131,072
Conv2d-6 [-1, 128, 16, 16] 131,072
BatchNorm2d-7 [-1, 128, 16, 16] 256
LeakyReLU-8 [-1, 128, 16, 16] 0
BatchNorm2d-9 [-1, 128, 16, 16] 256
LeakyReLU-10 [-1, 128, 16, 16] 0
Conv2d-11 [-1, 256, 8, 8] 524,288
Conv2d-12 [-1, 256, 8, 8] 524,288
BatchNorm2d-13 [-1, 256, 8, 8] 512
BatchNorm2d-14 [-1, 256, 8, 8] 512
LeakyReLU-15 [-1, 256, 8, 8] 0
LeakyReLU-16 [-1, 256, 8, 8] 0
Conv2d-17 [-1, 512, 4, 4] 2,097,152
Conv2d-18 [-1, 512, 4, 4] 2,097,152
BatchNorm2d-19 [-1, 512, 4, 4] 1,024
BatchNorm2d-20 [-1, 512, 4, 4] 1,024
LeakyReLU-21 [-1, 512, 4, 4] 0
LeakyReLU-22 [-1, 512, 4, 4] 0
Conv2d-23 [-1, 1, 1, 1] 8,192
Conv2d-24 [-1, 1, 1, 1] 8,192
Sigmoid-25 [-1, 1, 1, 1] 0
Sigmoid-26 [-1, 1, 1, 1] 0
Discriminator3x64x64-27 [-1, 1, 1, 1] 0
Discriminator3x64x64-28 [-1, 1, 1, 1] 0
================================================================
Total params: 5,531,136
Trainable params: 5,531,136
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.05
Forward/backward pass size (MB): 4.63
Params size (MB): 21.10
Estimated Total Size (MB): 25.77
----------------------------------------------------------------
"""
Optimizers
Use Binary Cross Entropy Loss
1
criterion = nn.BCELoss()
1
2
3
4
5
# 고정된 잠재 벡터(fixed noise)배치를 생성한다.
# 이 벡터는 학습 과정에서 Generator의 진행 상황을 시각화 하기 위해 사용된다.
# 64 = 고정된 노이즈 벡터의 배치 크기(배치 사이즈와 무관)
# 학습에 사용되는것이 아닌 학습 과정에서 생성자(G)의 성능을 시각적으로 모니터링하는 데 사용 `64`는 한 번에 생성하고자 하는 이미지의 수를 의미
fixed_noise = torch.randn(64, latent_dim, 1, 1, device=idist.device())
‘idist’ 에서 제공하는 분산처리 메서드인 auto_optim 을 사용해 분산 환경에 맞게 optimizer를 조정
1
2
3
4
5
6
7
optimizerD = idist.auto_optim(
optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999))
)
optimizerG = idist.auto_optim(
optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999))
)
Ignite Training Concepts
Ignite에서의 훈련은 Engine, Events 및 Handlers라는 3가지 핵심 구성 요소를 기반으로 한다.
- Engine : Engine은 훈련 루프와 유사하게 생각할 수 있다. train_step을 인수로 받고 각 데이터 셋의 배치에 대해 실행하고 진행하는 동안 이벤트를 트리거한다.
- Events : Events는 Engine이 실행/훈련 중 특정 지점에 도달했을 때 발생하는 이벤트
- Handlers : Engine이 특정 이벤틀르 발생시킬 때 트리거될 수 있는 함수들. Ignite에는 체크포인트, 조기 중단, 로깅 및 내장된 메트릭과 같은 미리 정의된 다양한 핸들러가 있다.
Training Step Function
Training step function은 Engine에 의해 전체 데이터셋을 배치 단위로 실행된다. 이 함수에는 기본적인 훈련 단계가 포함되어 있다. 즉, 모델을 실행하고 손실을 역전파하고 옵티마이저 단계를 실행하는 것이다. Generator 모델에 의해 생성된 가짜 이미지와 실제 이미지 모두에 대해 Discriminator 모델을 실행한다. 이 함수는 Generator와 Discriminator의 손실 및 Generator와 Discriminator가 생성한 출력을 반환한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
real_label = 1
fake_label = 0
def training_step(engine, data):
# 모델을 훈련 모드로 설정
netG.train()
netD.train()
############################
# (1) D 네트워크 업데이트: log(D(x)) + log(1 - D(G(z)))를 최대화
###########################
## 실제 배치로 훈련
netD.zero_grad()
# 배치 포맷 설정
real = data[0].to(idist.device())
b_size = real.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=idist.device())
# D를 통해 실제 배치를 전달
output1 = netD(real).view(-1)
# 모든 실제 배치에 대한 손실을 계산
errD_real = criterion(output1, label)
# 역전파를 위해 D의 그래디언트를 계산
errD_real.backward()
## 가짜 배치로 훈련
# 잠재 벡터의 배치를 생성
noise = torch.randn(b_size, latent_dim, 1, 1, device=idist.device())
# G를 사용해 가짜 이미지 배치를 생성
fake = netG(noise)
label.fill_(fake_label)
# D를 사용하여 모든 가짜 배치를 분류
output2 = netD(fake.detach()).view(-1)
# 모든 가짜 배치에 대한 D의 손실을 계산
errD_fake = criterion(output2, label)
# 이 배치에 대한 그래디언트를 계산하고 이전 그래디언트와 누적하여 (합산하여) 저장
errD_fake.backward()
# D의 오차를 가짜와 실제 배치를 합산하여 계산
errD = errD_real + errD_fake
# Update D
optimizerD.step()
############################
# (2) G 네트워크 업데이트: log(D(G(z)))를 최대화
###########################
netG.zero_grad()
label.fill_(real_label) # 생성기 비용에 대한 가짜 레이블은 실제
# D를 다시 업데이트했으므로 모든 가짜 배치를 D를 통해 전달
output3 = netD(fake).view(-1)
# 이 출력을 기반으로 G의 손실을 계산
errG = criterion(output3, label)
# G의 그래디언트를 계산
errG.backward()
# Update G
optimizerG.step()
return {
"Loss_G" : errG.item(),
"Loss_D" : errD.item(),
"D_x": output1.mean().item(),
"D_G_z1": output2.mean().item(),
"D_G_z2": output3.mean().item(),
}
위의 training_step 함수를 사용해 PyTorch-Ignite Engine trainer정의
1
trainer = Engin(training_step)
Handlers
PyTorch-Ignite 핸들러는 손실 및 모델 예측과 같은 중요한 정보를 출력하고 저장하는 역할을 수행한다.
DCGAN논문과 마찬가지로, 모든 모델 가중치를 평균이 0이고 표준편차가 0.02인 정규 분포에서 무작위로 초기화한다. 훈련 시작 시 생성기 및 판별자 모델에 initialize_fn 함수를 적용
1
2
3
4
5
6
7
def initialize_fn(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
init_weight Handler는 Engine실행 시 딱 한번만 트리거되며 Generator netG 및 Discriminator netD 에 대해 initialize_fn 함수를 적용하여 가중치를 무작위로 생성하는 역할을 담당한다.
1
2
3
4
@trainer.on(Events.STARTED)
def init_weights():
netD.apply(initialize_fn)
netG.apply(initialize_fn)
store_losses Handler는 각 매 스텝이 종료될 때 마다 Generator와 Discriminator 손실을 각각 G_losses와 D_losses에 저장하는 역할 수행
1
2
3
4
5
6
7
8
G_losses = []
D_losses = []
@trainer.on(Events.ITERATION_COMPLETED)
def store_losses(engine):
o = engine.state.output
G_losses.append(o["Loss_G"])
D_losses.append(o["Loss_D"])
store_images Handler는 훈련 중 Generator모델에 의해 생성된 이미지를 저장하는 역할을 수행. 이를 통해 훈련의 시각적 진행 상황을 제공한다. 이 핸들러는 매 500번째 배치 처리가 끝날 때마다 트리거 된다.
1
2
3
4
5
6
7
img_list = []
@trainer.on(Events.ITERATION_COMPLETED(every=500))
def store_images(engine):
with torch.no_grad():
fake = netG(fixed_noise).cpu()
img_list.append(fake)
Evaluation Metrics
Frechet Inception Distance (FID)와 Inception Score (IS)라는 두 가지 GAN 기반 지표를 사용
Inception Score (IS)는 생성된 이미지의 품질을 평가하는 객관적인 지표로, 특히 생성적 적대 신경망 모델에 의해 생성된 합성 이미지를 대상으로 한다. IS는 사전 훈련된 Inceptionv3 모델에서 제공하는 분류 확률을 사용하여 GAN의 성능을 측정한다.
Frechet Inception Distance (FID)는 실제 이미지와 생성된 이미지의 특징 벡터 사이의 거리를 계산하는 지표이다. IS와 마찬가지로 사전 훈련된 Inceptionv3 모델을 사용하며, 실제 이미지와 생성된 이미지의 특징 벡터 사이의 평균 및 공분산을 사용하여 GAN의 성능을 측정한다.
이러한 지표는 ignite.metrics 하위 모듈에서 제공되며, 모델의 전체 출력 이력을 저장할 필요 없이 온라인 방식으로 다양한 관심 지표를 계산할 수 있도록 한다.
매 에폭마다 FID 및 IS 지표가 계산되므로, 특정 핸들러 log_training_results가 매 에폭마다 트리거 돼야 한다. 지표는 전체 데이터셋에서 실행되기 때문에 별도의 엔진 train_evaluator가 정의되었으며, 이 엔진은 log_training_results 핸들러에 의해 실행된다.
1
from ignite.metrics import FID, InceptionScore
FID및 InceptionScore 메트릭은 다음과 같이 생성된다. 여기서는 gpu를 사용하기 위해 idist.device()로 설정한다.
1
fid_metric = FID(device=idist.device())
output_transform 인자는 엔진이 반환한 값에 대해 실행된다. InceptionScore는 입력으로 단일 이미지만 가져야 하지만 엔진에서 2개의 값이 반환되므로 output_transform 함수가 사용된다. 이름에서 알 수 있듯이 output_transform함수는 메트릭 평가를 위해 제공되기 전의 엔진의 출력에 적용된다. 따라서 lambda x: x[0] 을 사용하면 InceptionScore 메트릭이 평가를 위해 첫번째 값만 받도록 할 수 있다.
1
is_metric = InceptionScore(device=idist.device(), output_transform=lambda x: x[0])
Evaluators
evaluation engine 인 evaluation_step함수를 정의. dataset은 64 x 64 x 3 크기의 이미지를 제공하지만 IS 및 FID 메트릭은 평가를 위해 Inceptionv3 모델을 사용하며 최소 크기인 299 x 299 x 3 크기의 이미지가 필요하다. 따라서 데이터셋에서 가져온 이미지와 생성된 이미지는 보간 되어야 한다.
PyTorch에는 보간 함수가 내장되어 있지만, 안티엘리어싱이 좋지 않아 이미지 크기 조정이 제대로 이루어지지 않기 때문에 PIL보간이 대신 사용된다. 구현간의 이러한 불일치는 평가 지표와 최종 결과에 큰 영향을 미칠 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import PIL.Image as Image
def interpolate(batch):
# 크기가 조정된 이미지를 저장할 리스트를 초기화
arr = []
# 배치 내의 각 이미지에 대하여 반복
for img in batch:
# 현재 이미지를 PIL 이미지로 변환
pil_img = transforms.ToPILImage()(img)
# PIL 이미지의 크기를 (299, 299)로 조정. 양선형 보간법을 사용
resized_img = pil_img.resize((299,299), Image.BILINEAR)
# 조정된 이미지를 다시 텐서로 변환하여 리스트에 추가
arr.append(transforms.ToTensor()(resized_img))
# 리스트의 모든 이미지 텐서를 하나의 배치 텐서로 합쳐 반환
return torch.stack(arr)
def evaluation_step(engine, batch):
# 기울기 계산을 비활성화하여 메모리 사용을 줄이고 계산 속도를 높힌다.
with torch.no_grad():
# 생성 모델에 입력될 노이즈 벡터를 생성
noise = torch.randn(batch_size, latent_dim, 1, 1, device=idist.device())
# 생성 모델을 평가 모드로 설정
netG.eval()
# 노이즈 벡터 z를 사용하여 가짜 이미지 배치를 생성
fake_batch = netG(noise)
# 생성된 가짜 이미지의 크기를 조정
fake = interpolate(fake_batch)
# 실제 이미지 배치의 크기를 조정
real = interpolate(batch[0])
# 조정된 가짜 및 실제 이미지 배치를 반환
return fake, real
‘train_evaluator’ 엔진은 매 에포크마다 전체 데이터세트에 대한 측정항목을 실행하고 여기에 ‘IS’ 및 ‘FID’ 측정항목을 연결한다. PyTorch Ignite를 사용하여 평가 엔진을 설정하고, FID(Fréchet Inception Distance) 및 IS(Inception Score) 메트릭을 해당 엔진에 첨부
1
2
3
4
5
6
7
8
9
10
11
# 'evaluation_step' 함수를 사용하여 평가를 위한 Ignite 엔진을 생성
# 이 엔진은 평가 시에 'evaluation_step' 함수를 호출하여 각 배치에 대한 평가를 수행
evaluator = Engine(evaluation_step)
# FID 메트릭을 평가 엔진에 첨부. 'fid'라는 이름으로 저장
# 이 메트릭은 생성된 이미지와 실제 이미지 간의 거리를 측정하여 모델의 성능을 평가
fid_metric.attach(evaluator, "fid")
# IS 메트릭을 평가 엔진에 첨부. 'is'라는 이름으로 저장
# 이 메트릭은 생성된 이미지의 다양성과 품질을 평가하여 모델의 성능을 평가
is_metric.attach(evaluator, "is")
Engine은 PyTorch Ignite의 핵심 구성 요소 중 하나로, 주어진 처리 함수(evaluation_step)를 기반으로 작업(여기서는 평가)을 수행하는 엔진을 생성. evaluation_step 함수는 위에서 정의한 대로, 모델의 평가 단계에서 실행될 로직을 포함한다. fid_metric과 is_metric은 각각 FID 점수와 IS 점수를 계산하기 위한 메트릭으로, attach 메소드를 통해 평가 엔진에 첨부. 이렇게 첨부된 메트릭은 평가 엔진이 실행될 때 자동으로 계산되며, 지정된 이름("fid", "is")으로 결과를 저장
매 에폭마다 트리거되는 ‘trainer’ 엔진에 연결된 다음 핸들러는 ‘train_evaluator’엔진을 실행하여 ‘IS’ 및 ‘FID’ 측정항목을 평가한다. 결과는 최종적으로 에폭별로 저장된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# FID 점수를 저장할 리스트를 초기화
fid_values = []
# IS 점수를 저장할 리스트를 초기화
is_values = []
# 'trainer' 엔진의 각 에폭 완료 시 이벤트에 핸들러를 연결.
@trainer.on(Events.EPOCH_COMPLETED)
def log_training_results(engine):
# 평가 엔진을 실행하여 'test_dataloader'를 사용한 테스트 데이터셋에 대해 평가를 수행
# 'max_epochs=1'로 설정하여 평가 데이터셋을 한 번만 통과하도록한다.
evaluator.run(test_dataloader, max_epochs=1)
# 평가 엔진에서 계산된 메트릭을 가져온다.
metrics = evaluator.state.metrics
# 'fid' 메트릭 값을 가져온다.
fid_score = metrics['fid']
# 'is' 메트릭 값을 가져온다.
is_score = metrics['is']
# FID 점수를 'fid_values' 리스트에 추가
fid_values.append(fid_score)
# IS 점수를 'is_values' 리스트에 추가
is_values.append(is_score)
# 현재 에폭과 메트릭 점수를 출력
print(f"Epoch [{engine.state.epoch}/30] Metric Scores")
print(f"* FID : {fid_score:.4f}")
print(f"* IS : {is_score:.4f}")
Loss metrics
‘RunningAverage’ 측정항목은 생성기와 판별기 손실을 추적하는 데 사용. 이름에서 알 수 있듯이 ‘RunningAverage’는 제공된 모든 값의 평균을 추적한다.
1
2
3
4
5
6
7
from ignite.metrics import RunningAverage # Ignite에서 제공하는 RunningAverage 메트릭
# 생성자(generator)의 손실에 대한 RunningAverage를 계산하고, 이를 'trainer' 엔진에 'Loss_G'라는 이름으로 첨부
RunningAverage(output_transform=lambda x: x["Loss_G"]).attach(trainer, 'Loss_G')
# 판별자(discriminator)의 손실에 대한 RunningAverage를 계산하고, 이를 'trainer' 엔진에 'Loss_D'라는 이름으로 첨부
RunningAverage(output_transform=lambda x: x["Loss_D"]).attach(trainer, 'Loss_D')
Progress bars
학습 프로세스에는 많은 시간이 걸리고 많은 반복과 에폭이 있을 수 있으므로 모든 학습 데이터가 화면을 채우는 것을 방지하기 위해 진행률을 표시하는 ‘ProgressBar’ 핸들러 추가
1
2
3
4
5
6
7
from ignite.contrib.handlers import ProgressBar # Ignite의 프로그레스 바
# 'trainer' 엔진에 손실 값의 진행 상태를 나타내는 프로그레스 바를 첨부. 'Loss_G'와 'Loss_D' 메트릭을 표시
ProgressBar().attach(trainer, metric_names=['Loss_G','Loss_D'])
# 'evaluator' 엔진에도 진행 상태를 나타내는 프로그레스 바를 첨부. 이 경우, 특정 메트릭을 지정하지 않았으므로, 모든 메트릭을 표시
ProgressBar().attach(evaluator)
Training
‘trainer’ 엔진이 여기서 실행된다. idist 의 메서드 Parallel 은 trainer 엔진을 실행하기 위한 분산 구성을 설정하는데 도움을 준다. ‘nccl’, ‘gloo’ 및 ‘mpi’ 기본 PyTorch Backend ‘TPU’의 ‘XLA’ 및 ‘Horovod’ 분산 프레임워크를 지원한다.
1
2
3
4
5
6
7
def training(*args): # 'trainer' 엔진을 사용하여 'train_dataloader'를 통해 모델을 훈련. 최대 에폭 수는 30
trainer.run(train_dataloader, max_epochs=30)
# Ignite의 분산 처리 기능을 활용하여 훈련 함수를 병렬로 실행. 여기서 'nccl' 백엔드를 사용
with idist.Parallel(backend='nccl') as parallel:
parallel.run(training)
아래 코드는 PyTorch Ignite를 사용하여 딥러닝 모델의 훈련 과정을 설정하고 실행하는 과정을 보여줍니다. 코드에는 훈련 과정에서 손실값의 평균을 계산하고, 진행 상태를 시각적으로 표시하는 기능이 포함되어 있습니다. 또한, Ignite의 분산 처리 기능을 활용하여 모델 훈련을 병렬로 실행하는 방법도 포함되어 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from ignite.metrics import RunningAverage # Ignite에서 제공하는 RunningAverage 메트릭을 불러옵니다.
# 생성자(generator)의 손실에 대한 RunningAverage를 계산하고, 이를 'trainer' 엔진에 'Loss_G'라는 이름으로 첨부합니다.
RunningAverage(output_transform=lambda x: x["Loss_G"]).attach(trainer, 'Loss_G')
# 판별자(discriminator)의 손실에 대한 RunningAverage를 계산하고, 이를 'trainer' 엔진에 'Loss_D'라는 이름으로 첨부합니다.
RunningAverage(output_transform=lambda x: x["Loss_D"]).attach(trainer, 'Loss_D')
from ignite.contrib.handlers import ProgressBar # Ignite의 프로그레스 바를 불러옵니다.
# 'trainer' 엔진에 손실 값의 진행 상태를 나타내는 프로그레스 바를 첨부합니다. 'Loss_G'와 'Loss_D' 메트릭을 표시합니다.
ProgressBar().attach(trainer, metric_names=['Loss_G','Loss_D'])
# 'evaluator' 엔진에도 진행 상태를 나타내는 프로그레스 바를 첨부합니다. 이 경우, 특정 메트릭을 지정하지 않았으므로, 모든 메트릭을 표시합니다.
ProgressBar().attach(evaluator)
def training(*args):
# 'trainer' 엔진을 사용하여 'train_dataloader'를 통해 모델을 훈련시킵니다. 최대 에폭 수는 30으로 설정합니다.
trainer.run(train_dataloader, max_epochs=30)
# Ignite의 분산 처리 기능을 활용하여 훈련 함수를 병렬로 실행합니다. 여기서 'nccl' 백엔드를 사용합니다.
with idist.Parallel(backend='nccl') as parallel:
parallel.run(training)
RunningAverage: 이 메트릭은 지정된 출력값에 대한 이동 평균을 계산한다. 본 코드에서는 생성자와 판별자의 손실값(
Loss_G와Loss_D)에 대한 이동 평균을 각각 계산하고 있다. 이는 훈련 과정에서 손실값의 변화를 더 부드럽게 표현하기 위해 사용된다.- ProgressBar: 훈련의 진행 상태를 시각적으로 표시하는 데 사용된다.
ProgressBar().attach(trainer, metric_names=['Loss_G','Loss_D'])는 훈련 과정에서Loss_G와Loss_D의 값을 프로그레스 바와 함께 표시하도록 설정한다.ProgressBar().attach(evaluator)는 평가 과정에서의 진행 상태를 표시한다.메트릭 이름을 명시적으로 지정하지 않았기 때문에, 평가 엔진에 첨부된 모든 메트릭의 진행 상태가 표시된다.
- idist.Parallel: Ignite의 분산 처리 모듈.
idist.Parallel을 사용하면, 지정된 백엔드('nccl','gloo', 등)를 통해 작업을 병렬로 실행할 수 있다. 이는 특히 대규모 데이터셋을 사용하거나, 복잡한 모델을 훈련할 때 계산 시간을 줄이는 데 유용하다.'nccl'백엔드는 NVIDIA GPU를 사용하는 분산 환경에 최적화되어 있다.
Inference (추론)
1
2
3
4
5
6
7
8
9
%matplotlib inline
plt.figure(figsize=(10,5))
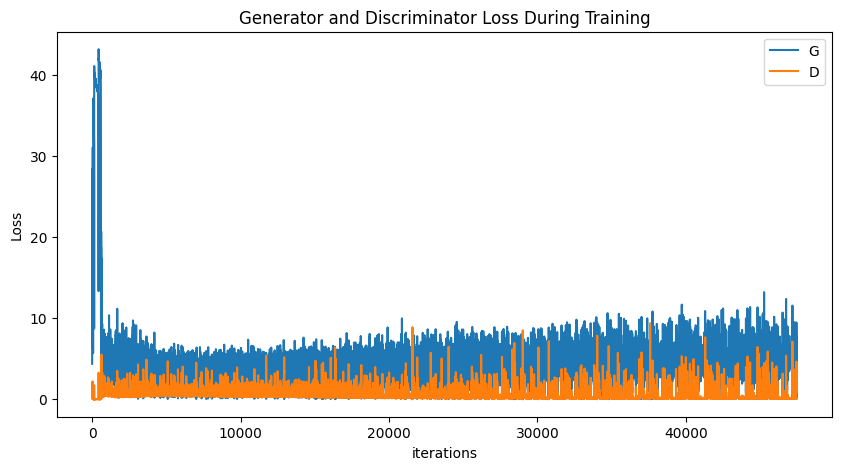
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
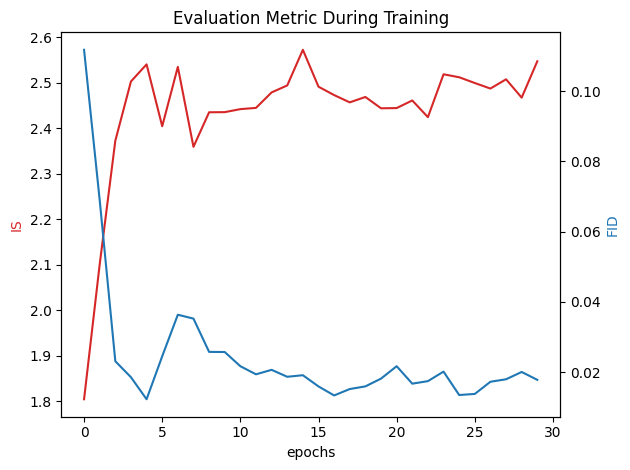
IS는 초반에 Generator가 얼굴을 빠르게 학습하고 있음을 나타냄 IS와 달리 FID는 급격히 감소(낮은 FID 값은 더 좋은 결과를 의미. / 높은 IS 값은 더 좋은 결과를 의미.)
1
2
3
4
5
6
7
8
9
10
11
12
13
fig, ax1 = plt.subplots()
plt.title("Evaluation Metric During Training")
color = 'tab:red'
ax1.set_xlabel('epochs')
ax1.set_ylabel('IS', color=color)
ax1.plot(is_values, color=color)
ax2 = ax1.twinx()
color = 'tab:blue'
ax2.set_ylabel('FID', color=color)
ax2.plot(fid_values, color=color)
fig.tight_layout()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
%matplotlib inline
# Grab a batch of real images from the dataloader
real_batch = next(iter(train_dataloader))
# Plot the real images
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0][:64], padding=5, normalize=True).cpu(),(1,2,0)))
# Plot the fake images from the last epoch
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(vutils.make_grid(img_list[-1], padding=2, normalize=True).cpu(),(1,2,0)))
