word2vec 논문 리뷰
| 태그 | #NLP |
|---|---|
| 한줄요약 | word2vec |
| Journal/Conference | #Arxiv |
| Link | word2vec |
| Year(출판년도) | 2013 |
| 저자 | Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean |
| 원문 링크 | word2vec |
핵심요약
- 대규모의 데이터셋을 학습하여 좋은 dense representation을 제공하는 2개의 architecture를 제안했다.
- 기존의 다른 뉴럴넷 기반 모델들과 비교해서 더 적은 계산량으로 더 좋은 정확도를 보이는 것을 확인했다.
Introduction
기존의 N-gram 기반 심플한 통계 모델들은 적은 데이터로도 많은 데이터를 학습시킨 복잡한 모델들보다 성능이 좋았다. 하지만, 이러한 심플 모델들은 좋은 퀄리티의 데이터들로 학습이 되어야만 적용이 가능해서 한계가 있었다. 이러한 좋은 퀄리티의 데이터는 많지 않았기에 학습할 수 있는 단어 수가 적었다. 그래서 최근에 제안된 뉴럴넷을 기반으로 한 모델들은 훨씬 더 많은 단어들을 학습하여 좋은 품질의 word vector를 만들 수 있게 되었다. 따라서, 저자들은 수백만개의 단어를 학습하여 이러한 좋은 word vector를 50 ~ 100차원으로 표현 가능한 새로운 구조를 제안하였다. 이렇게 만들어진 word vector들은 다양한 측면에서 유사성을 잘 판단할 수 있었다. 신기하게도 word vector가 표현된 공간에서 벡터 연산을 하면, 단어의 의미적 유사성을 판단할 수 있게 되었다.
예를 들어, vector(”king”) - vector(”Man”) + vector(”Woman”) 의 계산 결과인 벡터는 vector(”Queen”) 과 가장 가까웠다. 그래서 저자들은 이렇게 word vector들의 연산 결과의 정확도가 최대가 되는 새로운 구조를 제안하였다
Model Architecture
저자들이 제안한 모델 구조의 성능을 비교하기 위해서, training complexity $O$ 를 다음과 같이 정의한다. \(O = E \times T \times Q\)
($E$ 는 number of epochs, $T$ 는 training dataset의 단어 개수, $Q$ 는 training example마다 필요한 계산량.모델마다 정의가 다름.)
모든 모델들은 Stochastic gradient descent와 backpropagation을 이용하여 학습을 진행한다.
Feedforward Neural Net Language Model(NNLM)
input, projection, hidden, output layers로 구성된 feedforward Neural Net(이하 FFNN)을 이용한 Language Model(이하 LM)을 먼저 소개한다. 설명을 위해 정의하는 notation은 다음과 같다.
N = N-gram의 N과 비슷한 의미로, input layer에 들어가는 단어 수
V = 학습하는 데이터셋의 전체 단어 수
P = N x D
D = 단어가 표현되는 공간의 차원
H = hidden layer의 노드 수
NNLM은 input → projection → hidden → output layer 순서대로 정의되는데, 이 때 projection layer에서 hidden layer로 변환하는데 많은 계산량이 필요하다. 보통 N = 10_으로 하고, P는 500 ~ 2000정도, H는 500 ~ 1000_정도로 사용한다. 그리고 hidden layer는 모든 단어 V개의 조건부 확률을 계산하기 위해서 사용되므로, $Q$ 는 다음과 같다.
\[Q = N \\times D + N \\times D \\times H + H \\times V\]이 때, $H \times V$의 계산량이 매우 크기 때문에 이를 줄이기 위해서 각 단어를 Huffman binary tree로 표현한hierarchical softmax 방식을 사용한다. 이를 사용하면 $V$ 가 $log_2V$ 로 줄어들게 된다. 그래서 우리가 제안하는 모델은 hierarchical softmax를 사용한다.
Recurrent Neural Net Language Model(RNNLM)
RNNLM은 FFNN을 사용한 방식보다 좀 더 언어 모델의 패턴을 효율적으로 계산할 수 있다. RNN 모델은 projection layer가 필요없고, input, hidden, output layer만 있으면 된다. 따라서, RNNLM의 $Q$ 는 다음과 같다.
\[Q = H \\times H + H \\times V\]이며 D_는 H_와 같다. 이 방식 또한 hierarchical softmax를 사용하면 $V$를 $log_2V$ 로 줄일 수 있다.
New Log-linear Models (제안하는 방식)
저자들은 이전 모델들에서 non-linear hidden layer가 높은 complexity를 요구한다는 사실을 발견하고 이를 줄이는 방식을 제안한다. 먼저 심플한 모델로 continuous word vector를 만든 다음, N-gram NNLM으로 앞에서 만들어진 continuous word vector들을 다시 학습한다. 이렇게 제안된 모델은 이전 모델들보다 훨씬 심플하기 때문에 계산 효율성이 좋다.
제안하는 모델 2가지의 대략적인 구조는 다음과 같다.
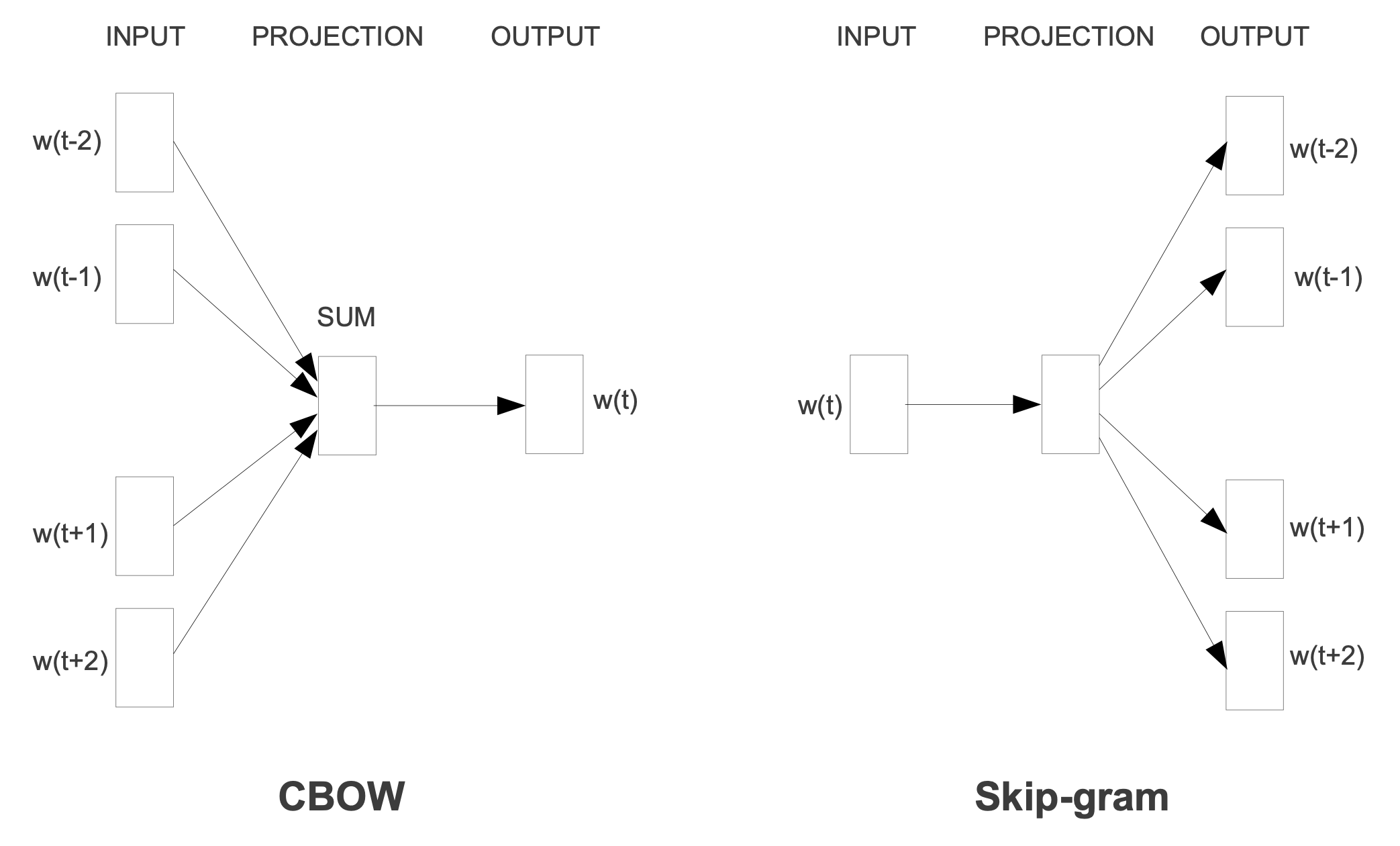
- CBOW(Continuous Bag-of-Words Model)
CBOW 모델은 FFNN에서 hidden layer를 제거하고 projection layer를 모든 단어가 공유하고 만든 구조이다. 그렇기 때문에 모든 단어들은 같은 위치로 projection된다. (즉, 같은 위치에 있는 단어들끼리는 평균으로 계산됨) 그리고 이렇게 학습된 단어들은 뒤에 설명한 log-linear classifier와 함께 N개의 단어를 예측하기 위해 사용된다. training criterion은 현재 classifier가 보고 있는 middle word를 예측하는 것으로 한다. 이 때 $Q$ 는 다음과 같다.
$Q = N \times D + D \times log_2V$
- Continuous Skip-gram Model
Skip-gram 모델은 CBOW 모델과 유사하지만, classifier가 보고 있는 middle word를 예측하는 것 대신에, 같은 문장에 포함된 다른 단어를 분류하는 문제의 성능을 최대로 하는 것을 목표로 한다. 다시 말하면, 각 middle word(current word)를 log-linear classifier의 입력으로 간주하고 current word 앞뒤에 몇개 있는 단어들을 예측하는 문제를 푸는 것을 목표로 한다는 의미이다. 이 때 앞뒤로 살펴보는 단어의 범위를 늘리면 word vector의 퀄리티가 좋아진다. 단, 계산량은 늘어나게 된다. 이 때 $Q$ 는 다음과 같다.
$Q = C \times (D + D \times log_2V)$
($C$ 는 단어들로부터 떨어진 최대 거리)
예를 들어 C = 5 로 하면, [1, C]의 범위에서 랜덤으로 고른 정수 R을 선택한 뒤 순서대로 R개의 단어를 고르고, 현재 단어를 기준으로 미래의 R개의 단어를 예측 label로 정한다. 이것은 현재 단어를 input으로 하고 R + R 단어를 output으로 하는 분류 문제를 푸는 것과 같으며, R \times 2의 단어 분류 문제를 푸는 것과 같다. 이후의 실험에서는 C = 10으로 사용한다.
Results
Task Description
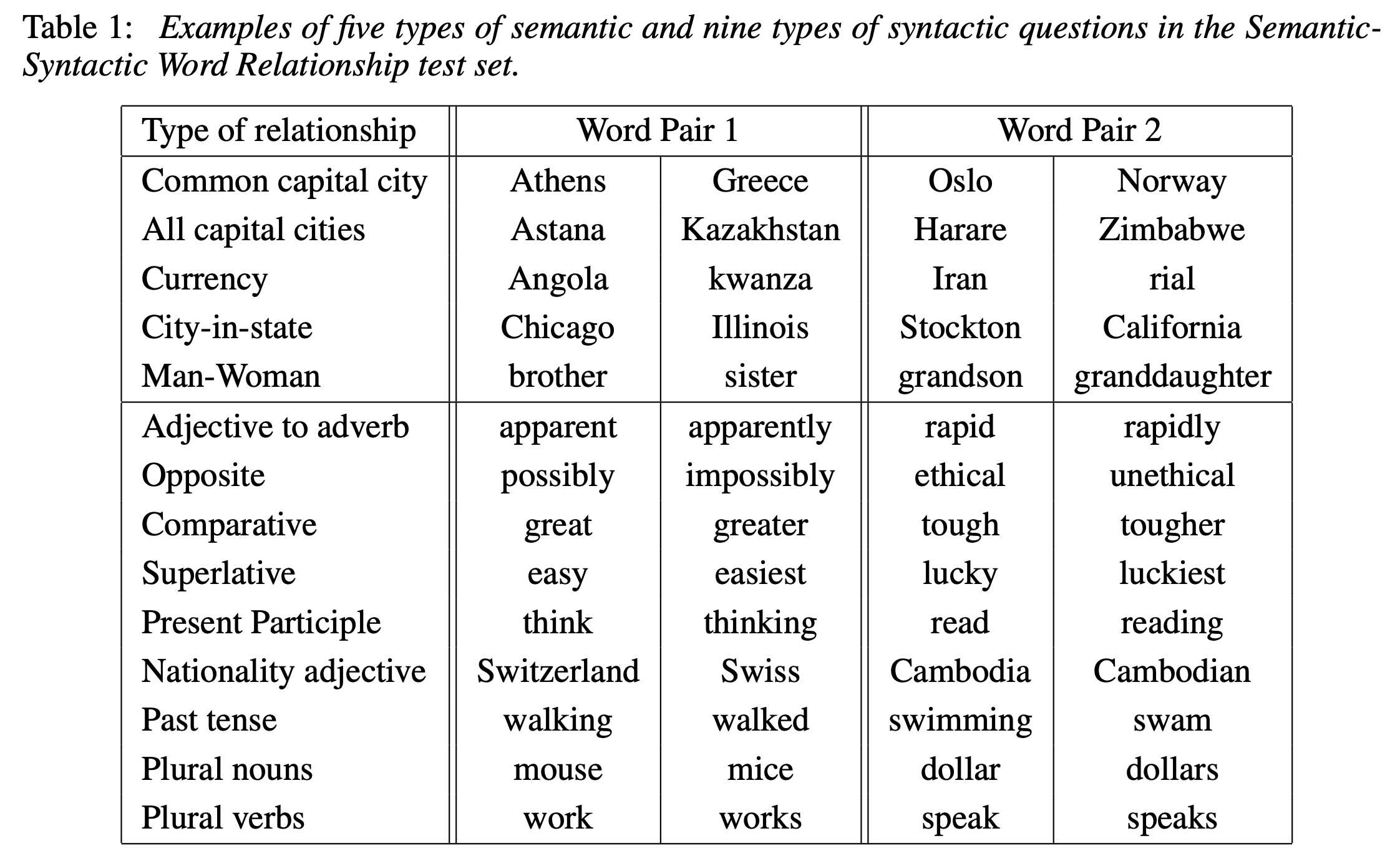
저자들은 제안한 구조로 학습한 word vector가 유사성을 잘 판단한다는 기준을 제시하기 위해서, 5가지의 semantic, 9가지의 syntatctic questions들을 준비하였다. 총 8869개의 semantic, 10675개의 syntactic question들이 있다. 이 데이터셋들은 처음 수작업으로 유사 단어들을 매칭한 뒤, 나머지는 랜덤하게 섞어서 word pair를 만드는 것이다. 하나를 예로 보면 68개의 American cities와 각 도시가 포함된 states들을 매칭 시킨 뒤(정답 셋), 2.5K의 questions은 랜덤하게 섞은 Pair로 만들었다. 이렇게 만든 데이터셋으로 테스트할 때, 정답과 완전하게 동일한 word를 예측한 경우에만 정답으로 처리하였다. (accuracy의 판단 기준) 수작업으로 매칭한 단어가 pair이기 때문에, 실제 정답과 유사한 단어나 동의어를 예측하더라도 정답으로 처리가 되지 않는다. 그래서 사실상 100%의 성능을 내긴 어려운 task이다.
해당 task에 대한 성능 평가 방식은 맨 처음에 논문에서 언급했던 벡터 연산을 통한 유사성 판단을 기준으로 한다.
예를 들어,
X = vector(”biggest”) - vector(”big”) + vector(”small”) 라고 하면,
_X_와 가장 가까운 벡터는 vector(”smallest”) 가 되고 이게 정답 pair와 일치하는지를 판단한다.
Maximization of Accuracy
저자들은 Google News 데이터를 학습 코퍼스로 사용하였다. 대략 6B tokens(60억개 단어)를 포함하고 있다. 학습을 위해 가장 많이 등장한 순으로 1M tokens(100만개 단어)를 추려서 사용하였다. 저자들은 더 많은 단어와 더 높은 차원으로 단어를 표현하면 성능이 올라가는 것이 당연하다고 여겼기 때문에, 모델들의 성능 비교 위한 실험의 빠른 결과를 확인하기 위해서 가장 많이 등장한 30K tokens(30000개 단어)만을 사용하였다. 실험 세팅과 결과는 다음과 같다.
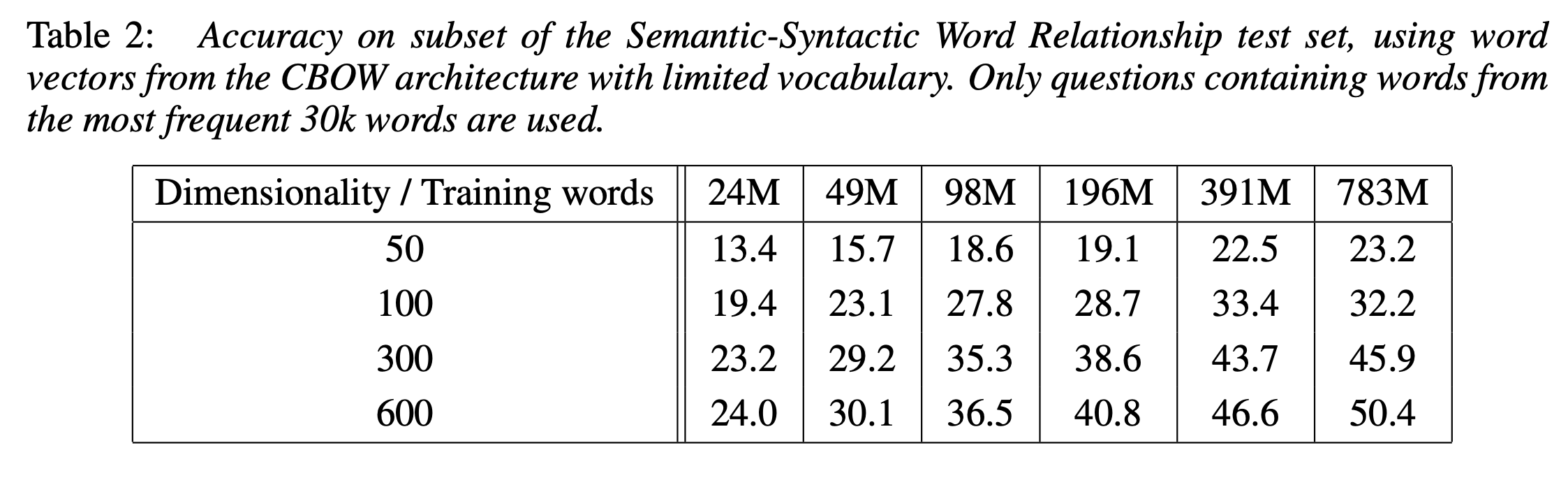 Table 2 를 통해 알 수 있는 결과는, dimensionality과 # of training words가 함께 커져야 성능이 향상된다는 사실을 알 수 있다.
Table 2 를 통해 알 수 있는 결과는, dimensionality과 # of training words가 함께 커져야 성능이 향상된다는 사실을 알 수 있다.
Comparison of Model Architectures
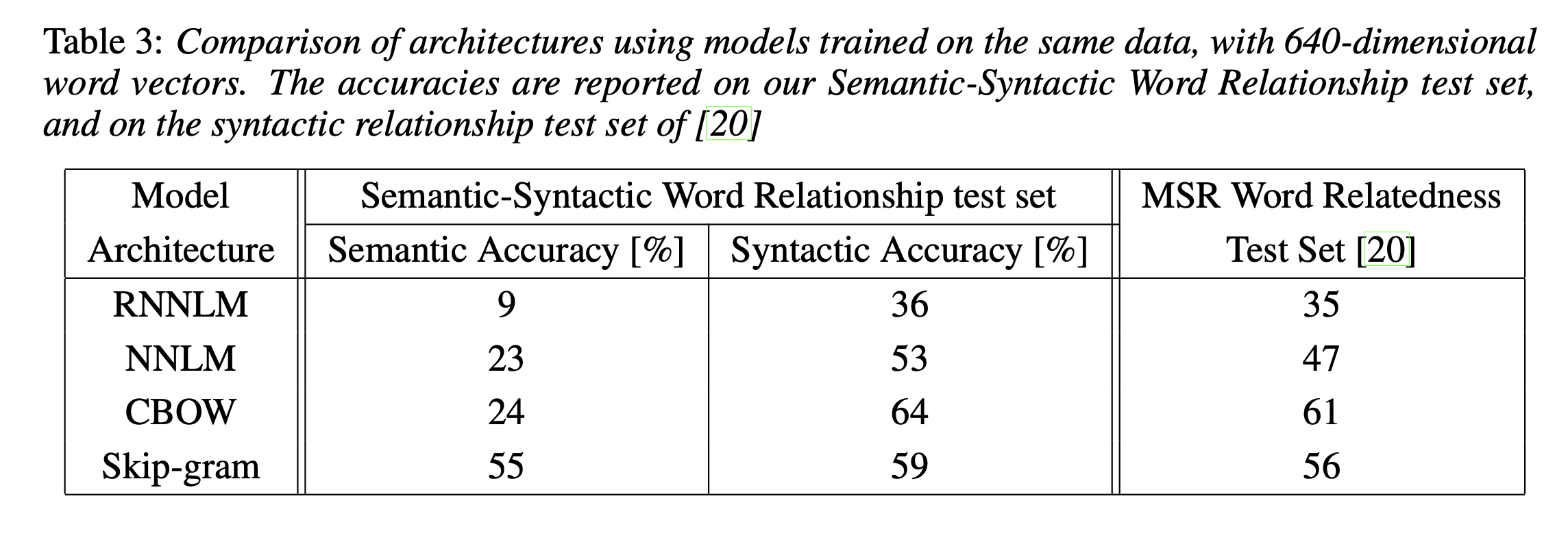
아래 Table 3를 보면 같은 데이터와 차원을 주고 각 LM마다의 성능 차이를 볼 수 있다. MSR Word Relatedness Test Set도 새로운 공개 데이터셋인데 같은 세팅으로 30K의 단어만 가지고 비교에 사용하였다. 결과를 보면 RNNLM의 성능이 가장 낮고, 제안한 2개의 방식이 다른 방법들에 비해 성능이 압도적으로 높은 것을 확인할 수 있다.
아래 Table 4는 이미 공개되어 있는 word vector들과 비교한 실험이다. 여러 모델들중에서 CBOW와 Skip-gram이 훨씬 높은 성능을 보여주는 것을 확인할 수 있다.
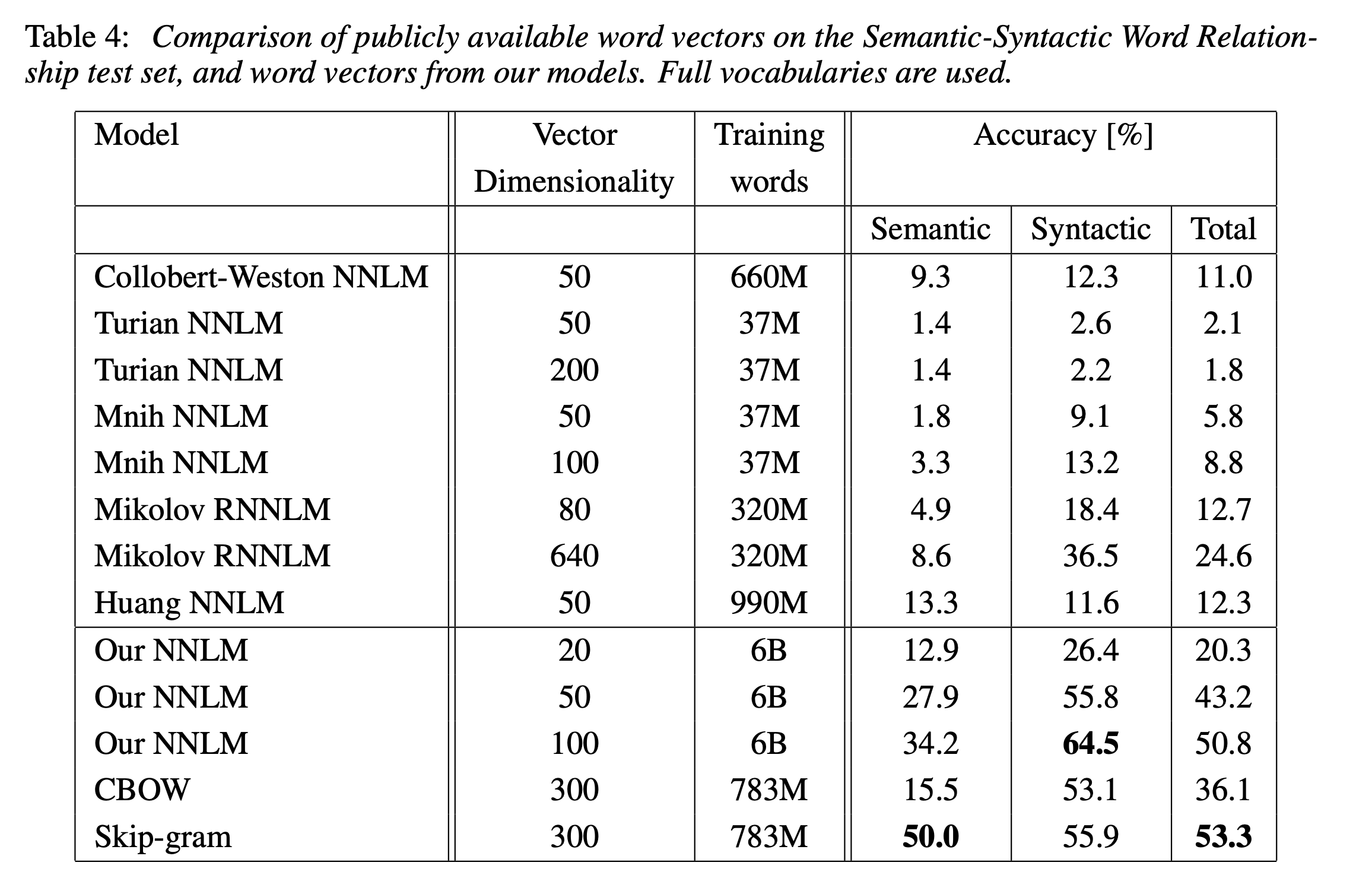
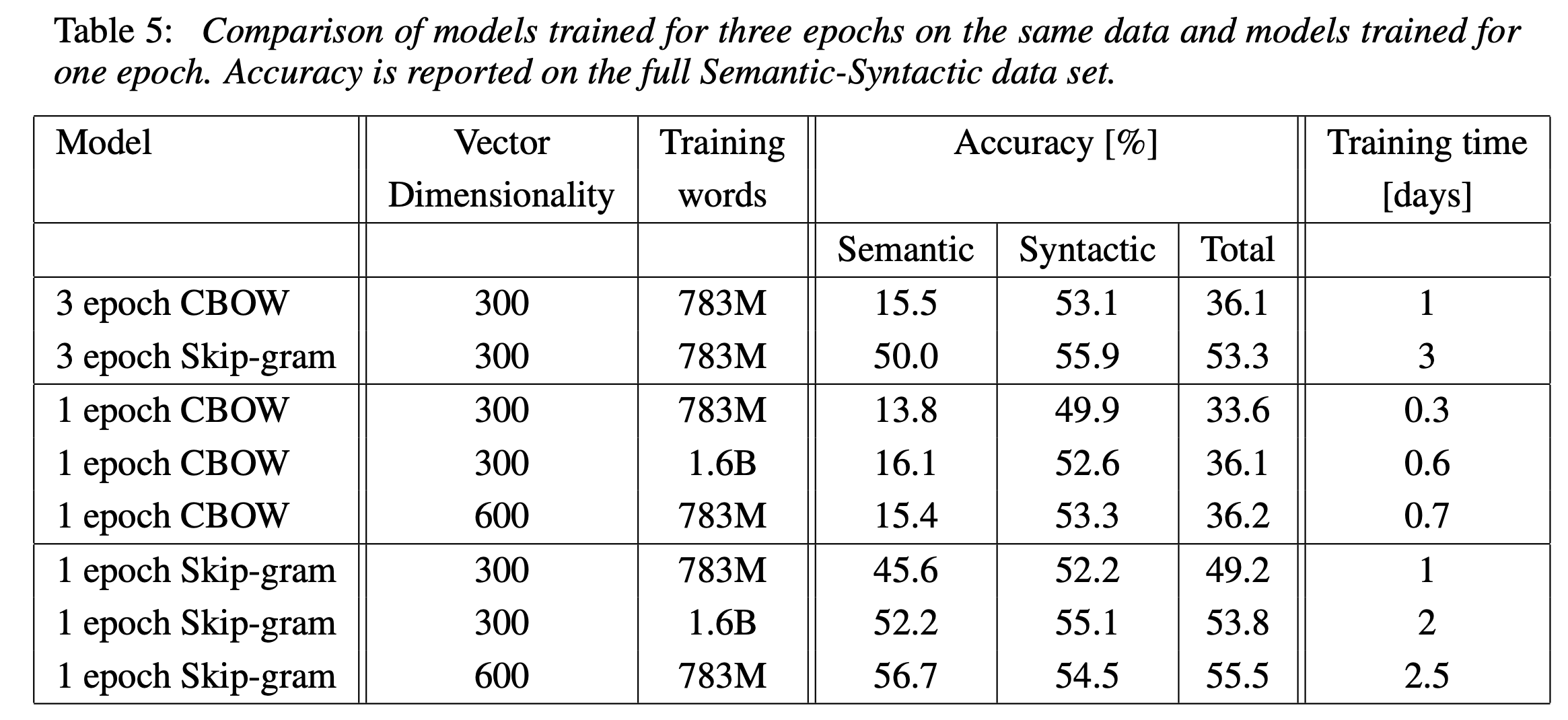
아래 Table 5는 학습 방식 차이에 따른 성능 비교를 보여준다. CBOW가 Skip-gram보다 학습 시간은 더 짧지만, 전반적인 성능은 Skip-gram이 훨씬 높은 것을 확인할 수 있다. 전체 데이터셋이 커서 학습 시간이 오래걸렸지만 3 epoch 학습시킨 모델이 더 높은 성능을 보여주는 것을 확인할 수 있다.
Examples of the Learned Relationships
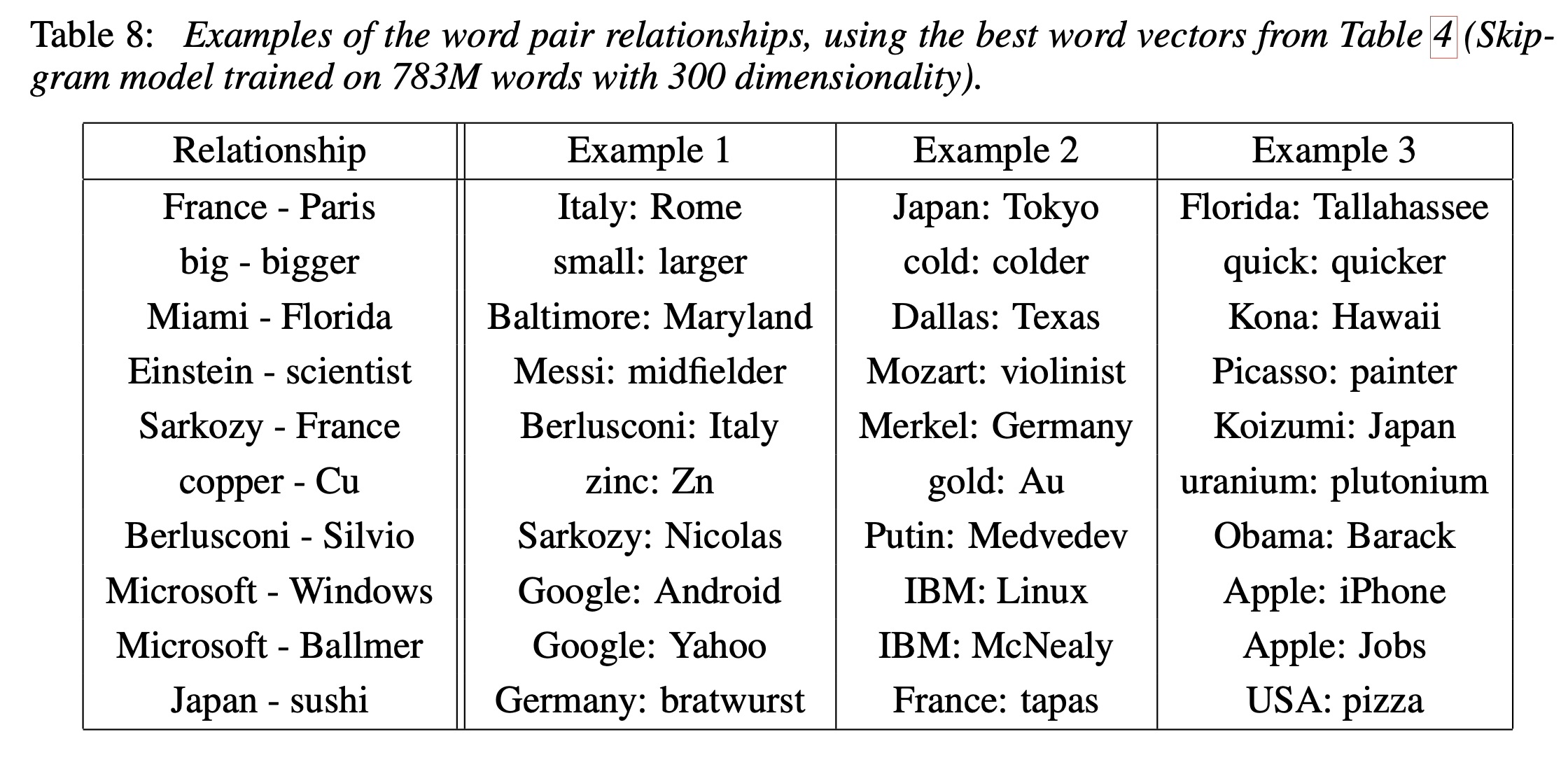
위에서 정의했었던 벡터 연산으로 체크하는 task에 대한 결과는 _Table 8_에 나와있다. 저자들은 task에 대한 성능은 60%밖에 안되지만, 더 많은 단어로 더 높은 차원으로 학습시킨 word vector는 성능이 좋았을거라고 말한다.
이 테이블이 시사하는 좋은 점이라면 해당 벡터 연산을 통해서 다른 task에 활용할 수 있다는 점이다. 예를 들면 서로 연관이 없는 단어들 리스트를 찾는 것들에 활용할 수 있다.
Conclusion
저자들은 CBOW와 Skip-gram이라는 간단한 모델로 최신 성능을 넘기면서 훨씬 더 적은 계산량을 제공하는 모델을 새롭게 제시했다. 이 모델들 덕분에 6B 사이즈의 데이터셋도 현실적으로 학습 가능한 시간내에 가능하게 되었다. 심지어는 SemEval-2012 Task 2인 최신 task에 나왔던 RNN word vector보다도 훨씬 좋은 성능을 보였다. 이렇게 만들어진 word vector는 sentiment analysis나 paraphrase detection 같은 다른 task에도 활용가능하다.
++ 이 내용에다가 더 추가된 내용으로 다음 논문인 Distributed Representations of Words and Phrases and their Compositionality가 나온다. 이 논문은 NIPS 2013에 게재가 되며 NLP의 역사를 바꾸는 논문이 된다.