Knowledge Distillation 논문 리뷰
| 태그 | #ModelCompression #TransferLearning |
|---|---|
| 한줄요약 | Knowledge Distillation |
| Journal/Conference | #NIPS |
| Link | Knowledge Distillation |
| Year(출판년도) | 2014 |
| 저자 | Geoffrey Hinton, Oriol Vinyals, Jeff Dean |
| 원문 링크 | Knowledge Distillation |
쉬운 설명
핵심 요약
- 2014년에 소개된 이 논문은 크고 복잡한 AI 모델의 ‘지식’을 작고 효율적인 모델로 전달하는 방법을 제안한다.
- 이 방법을 통해 큰 모델의 성능을 거의 유지하면서도 더 빠르고 경제적인 AI를 만들 수 있다.
- 또한, 여러 전문가 모델을 조합해 더 강력한 AI를 만드는 방법도 제시한다.
왜 이런 연구가 필요한가?
최근 AI 모델들은 점점 더 크고 복잡해지고 있다. 이런 모델들은 뛰어난 성능을 보이지만, 몇 가지 문제가 있다:
- 속도가 느림: 큰 모델은 결과를 내는 데 시간이 오래 걸린다.
- 많은 자원을 필요로 함: 스마트폰과 같은 작은 기기에서 사용하기 어렵다.
- 비용이 많이 듬: 큰 모델을 운영하려면 많은 전기와 컴퓨터 자원이 필요하다.
이 연구는 이런 문제들을 해결하면서도 큰 모델의 성능을 최대한 유지하는 방법을 찾고자 했다.
주요 아이디어: Knowledge Distillation
Knowledge Distillation의 핵심 아이디어는 “선생님(큰 모델)의 지식을 학생(작은 모델)에게 효과적으로 전달하는 것”이다.
1. 소프트 타겟(Soft Target) 사용
- 일반적인 방법 (하드 타겟): AI에게 “이 사진은 고양이다” 또는 “이 사진은 고양이가 아니다”라고 명확하게 알려준다.
- 소프트 타겟: “이 사진은 70% 고양이 같고, 20% 강아지 같고, 10% 토끼 같다”와 같이 확률적으로 알려준다.
- 장점: 소프트 타겟은 데이터 간의 관계와 모델의 불확실성을 포함하고 있어, 더 풍부한 정보를 전달할 수 있다.
2. 온도 조절 (Temperature)
- 아이디어: 소프트 타겟의 확률 분포를 더 부드럽게 만들어 정보 전달을 조절한다.
- 비유: 뜨거운 차를 식히는 것처럼, 높은 ‘온도’는 확률 분포를 더 균등하게 만든다.
- 효과: 적절한 온도 설정으로 지식 전달의 효율을 높일 수 있다.
실제 적용 예시
- MNIST 손글씨 인식:
- 큰 모델의 지식을 작은 모델에 전달했을 때, 작은 모델의 성능이 크게 향상되었다.
- 모델 크기에 따라 적절한 ‘온도’를 설정하는 것이 중요함을 발견했다.
- 음성 인식:
- 여러 모델을 합친(앙상블) 큰 모델의 지식을 하나의 작은 모델로 전달했다.
- 결과적으로 작은 모델이 10개의 모델을 합친 것과 비슷한 성능을 냈다.
- 대규모 이미지 분류:
- 구글의 거대한 비공개 데이터셋(JFT)을 사용해 실험했다.
- 모든 것을 아는 ‘제너럴리스트’ 모델과 특정 분야만 잘 아는 ‘스페셜리스트’ 모델들을 조합했다.
- 이 방법으로 전체 모델을 다 사용하는 것보다 더 효율적으로 좋은 성능을 얻었다.
추가 발견
소프트 타겟을 사용해 학습한 모델들은 과적합(overfitting) 문제가 덜 발생했다. 이는 소프트 타겟이 모델이 너무 데이터에 맞춰지는 것을 방지하는 일종의 ‘규제’ 역할을 한다는 것을 의미한다.
결론
- 효율성: 작고 빠른 모델로 큰 모델의 성능을 거의 따라갈 수 있다.
- 실용성: 스마트폰 같은 작은 기기에서도 고성능 AI를 구현할 수 있게 된다.
- 경제성: AI 운영에 필요한 자원과 비용을 크게 줄일 수 있다.
- 새로운 가능성: 여러 전문가 모델을 효과적으로 조합해 더 강력한 AI를 만들 수 있다.
이 연구는 AI를 더 작고, 빠르고, 스마트하게 만드는 중요한 발걸음이 되었다.
원본
핵심 요약
- Ensemble 등 거대한 Model 의 성능을 유지하며 연산 효율을 높일 수 있는 Knowledge Distillation 방법을 제시한다.
- Soft-target 을 통한 Knowledge Distillation 이 모델의 일반화 성능을 전이할 수 있음을 제시한다.
- Full ensemble 이 어려운 거대한 모델을 specialist model 의 ensemble을 사용해 성능을 개선할 수 있음을 제시한다.
Introduction
대규모 머신러닝 과제에서 실제 훈련에 사용한 거대 모델을 그대로 배포하는 경우, 각종 latency 와 연산 자원 소모 문제가 발생할 수 있다. 이는 특히 ensemble 모델과 같은 거대한 모델에서 빈번하게 발생한다.
논문은 이를 해결할 수 있는 Distillation 방법과 이를 효과적으로 수행하기 위한 분석 결과를 제시한다.
Distillation 은 거대한 모델의 knowledge 를 작은 모델에 전이하는 방법이다.
이 때, One-Hot Encoding 으로 Hard-label 된 데이터를 학습한 거대한 모델이 있다면, 현실의 데이터를 넣었을 때 완벽하게 분류를 수행하기보다는 애매한 확률값을 출력할 것이다.
논문은 데이터의 구조에 대한 정보를 함께 담고 있는 큰 모델의 출력 확률값을 Soft-target 이라고 부르며, 이를 통해 학습한 모델은 현실적인 objective 를 해결하는데 적합하다는 결과를 보인다.
또한, soft-target 의 분포를 더욱 균등하게 만들어 주는 temperature 개념을 제시한다.
Distillation
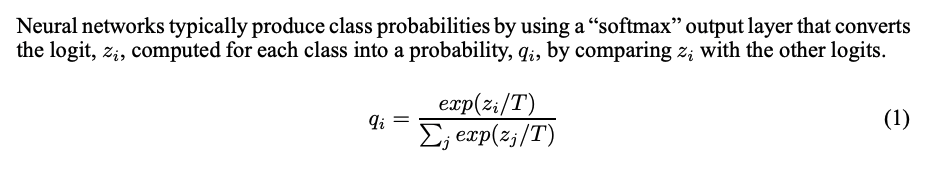
일반적인 softmax 식에 Temperature 개념을 도입한다. T=1 인 경우 일반 softmax 와 동일하며, T 가 커질수록 smooth 한 확률 분포가 생성된다.
softmax 를 target 으로 한 distillation 의 목적 함수는 아래 두가지의 가중합으로 표현된다.
- Soft target 의 Cross entropy
- high T 로 구한 거대 모델의 soft target 과 distilled 모델의 soft prediction 을 사용
- Hard target 의 Cross entropy
- T =1 일 때 hard label 과 distilled model의 prediction 을 사용
Hard target 의 Cross entropy 의 가중치를 작게 했을 때 좋은 성능을 보였다고 한다. 또한, Soft target entropy 의 gradient 가 $1/T^2$ 로 scaling 됨을 근거로, 목적함수에 $T^2$ 를 곱하는 것이 중요함을 언급한다.
2.1 Matching logits is a special case of distillation

Softmax Cross entropy 을 미분해가며 분석한다.
이를 통해, high temperature limit 에서 soft target 을 이용해 distillation model 을 학습하는 것이, hard target 으로 logit 을 일치시키는 문제와 동일함을 보인다.
이외에도 낮은 temperature 로 학습을 수행할 시 거대 모델의 logit 이 noisy 해질 수 있음을 설명한다.
또한, distilled 모델 크기가 작아 knowledge 가 작은 경우, 중간 정도의 temperature 가 좋은 성능을 보였을 제시한다.
Preliminary experiments on MNIST

MNIST 데이터셋으로 실험을 수행하기 위해 사용한 모델을 설명하고, smaller model 에 distillation을 적용했을 때 성능이 상승했음을 제시한다. 따라서, soft target 을 이용해 distilled model 에 지식이 성공적으로 전달될 수 있음을 보여준다고 한다.
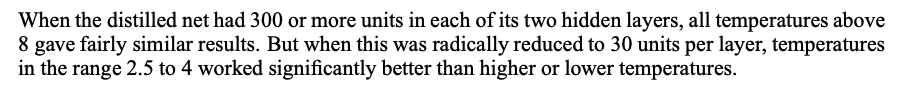
Model 의 크기와 T 를 조절해가면서, model 의 크기가 작을수록 T 또한 작아져야 한다는 실험결과를 제시한다.
Experiments on speech recognition
Ensemble 모델을 증류했을 때, 동일한 크기의 모델을 동일한 데이터셋으로 학습한 것보다 더 좋은 성능을 보일 수 있음을 검증한다. 아래는 모델 구조에 대한 설명이다.

Results
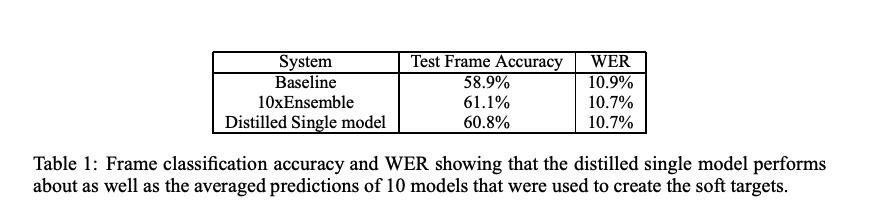
Distilled 모델이 10번 Ensemble 한 모델과 비슷한 성능을 보임을 확인할 수 있다. 또한, 동일한 구조에 동일한 데이터셋을 사용해 훈련한 단일 모델 보다 더 높은 성능을 보였음을 제시한다.
Training ensembles of specialists on very big datasets
크기가 큰 모델과 많은 데이터셋을 사용해 ensemble 을 수행해야하는 경우, 병렬화를 수행했을 때도 감당하기 어려운 막대한 computation 을 요구한다.
논문은 전체 데이터셋 Class 의 subset 만을 사용해 학습한 specialist 모델을 사용하여 generalist 모델이 ensemble 을 수행하기 위해 필요한 연산을 줄일 수 있음을 보인다.
The JFT dataset
구글의 비공개 데이터셋인 JFT(100M images with 15k labels)를 사용한다.

이 데이터셋을 처리하기 위해서 사용한 baseline 모델은 mini-batch 를 병렬화하고 모델 구조를 병렬화하는 것만으로도 수많은 연산량을 요구한다.
Specialist Models
논문은 분류해야하는 class 가 매우 많은 거대한 모델을 ensemble 할 수 있는 방법을 제시한다. 모든 데이터를 학습한 generalist 모델과, 일부 class 의 데이터를 사용해 훈련한 specialist 를 혼합하여 ensemble 함으로서, 모델 전체를 ensemble 하는 것보다 더욱 가벼워질 수 있다. 그러나 specialist 모델은 적은 데이터셋으로 인해 과적합이 발생하기 쉬운 구조를 가지고 있다.
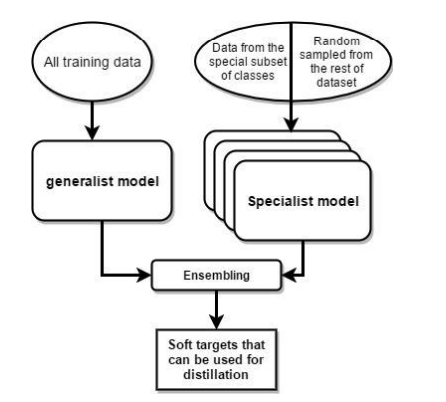
이를 해결하기 위해, 논문은 generalist 모델의 weight 로 specialist 모델을 초기화 하는 방법을 제시한다.
Assigning classes to specialists
specialist 모델을 위한 적절한 class 를 고르는 방법을 제시한다.

Performing inference with ensembles of specialists
specialist 모델 ensemble 의 성능을 확인할 수 있는 방법을 제시한다.


Results
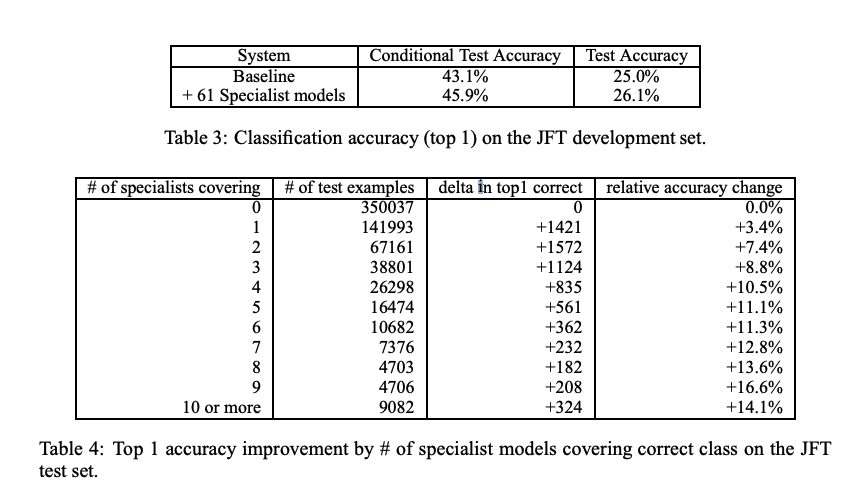
specialist 모델을 이용한 ensemble이 baseline 보다 더 높은 성능을 보이며, 거대한 모델을 distillation 해 더 빠르게 학습을 수행할 수 있음을 보인다. 이는 specialist model 의 수가 늘어날 수록 성능 상승효과가 커지는 결과를 제시한다.
Soft Targets as Regularizers
hard target 이 아닌 soft target 을 통한 학습이 regularization 효과를 제공하여 과적합을 방지할 수 있음을 제시한다.
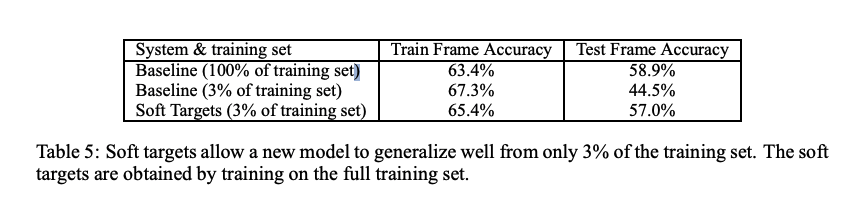
Hard target 을 사용한 경우, early stopping 을 사용한 경우에도 과적합이 발생했으나, soft target 으로 학습한 경우에는 early stopping 을 사용하지 않고도 accuracy 가 수렴했음을 언급한다.
Using soft targets to prevent specialists from overfitting
Specialist 모델 또한 soft target 을 사용하여 overfitting 을 방지할 수 있었음을 언급한다.
Discussion
ensemble 혹은 매우 큰 regularized 모델을 보다 작은 모델로 증류(distillation)하여 knowledge를 전이할 수 있음을 보였다. full ensemble 를 학습하기 어려운 경우, small specialist 모델을 ensemble함으로써 성능 향상을 얻을 수 있음을 제시한다.