Saliency Map 논문 리뷰
| 태그 | #ComputerVision #ExplainableAi |
|---|---|
| 한줄요약 | Saliency Map |
| Journal/Conference | #NIPS |
| Link | Saliency Map |
| Year(출판년도) | 2014 |
| 저자 | K. Simonyan, A. Vedaldi, A. Zisserman |
| 원문 링크 | Saliency Map |
쉬운 설명
핵심 요약
- 2014년에 소개된 이 논문은 이미지 분류 모델이 어떻게 ‘생각’하는지 시각화하는 방법을 제안한다.
- 이 방법은 딥러닝 모델을 분석하는 도구로 사용될 수 있으며, 약한 지도 학습(weakly supervised learning) 방식의 물체 분할(segmentation)에도 응용할 수 있다.
왜 이런 연구가 필요한가?
딥러닝 모델, 특히 이미지를 다루는 모델들은 놀라운 성능을 보이고 있다. 하지만 이 모델들이 어떻게 작동하는지, 무엇을 ‘보고’ 결정을 내리는지는 여전히 블랙박스와 같았다. 이 연구는 그 블랙박스를 조금이나마 열어보려는 시도라고 할 수 있다.
- 모델의 결정 과정 이해: 모델이 어떤 부분을 중요하게 여기는지 알면, 모델의 결정을 더 잘 이해하고 신뢰할 수 있다.
- 모델 개선: 모델의 ‘생각’ 과정을 알면, 더 나은 모델을 만들 수 있다.
- 새로운 응용: 모델의 ‘주목’ 방식을 이용해 다른 문제를 해결할 수 있다.
주요 아이디어
이 논문은 두 가지 주요 방법을 제안한다:
- 클래스 모델 시각화 (Class Model Visualization)
- 이미지별 클래스 현저성 시각화 (Image-specific Class Saliency Visualization)
1. 클래스 모델 시각화
이 방법은 “모델이 생각하는 이상적인 이미지는 어떤 모습일까?” 라는 질문에 답하려고 한다.
- 작동 방식: 빈 이미지에서 시작해, 모델이 특정 클래스로 강하게 분류할 때까지 이미지를 조금씩 변형한다.
- 비유: 화가가 머릿속 이미지를 그리는 것과 비슷하다. 모델이 ‘화가’가 되어 자신이 아는 ‘고양이’나 ‘자동차’를 그리는 것이다.
- 결과: 이렇게 만들어진 이미지들은 실제 물체와 꽤 비슷한 모습을 보인다.

2. 이미지별 클래스 현저성 시각화 (Saliency Map)
이 방법은 “모델이 이미지의 어느 부분을 보고 결정을 내리는가?” 라는 질문에 답하려고 한다.
- 작동 방식: 모델의 출력이 입력 이미지의 각 픽셀 변화에 얼마나 민감한지 계산한다.
- 비유: 사람이 그림을 볼 때 어디를 주목하는지 추적하는 것과 비슷하다.
- 결과: 이미지에서 모델이 중요하게 여기는 부분을 하이라이트로 표시한 ‘현저성 지도(Saliency Map)’를 얻는다.

실제 적용 예시
- 모델 이해하기:
- Saliency Map을 통해 모델이 이미지의 어떤 부분을 중요하게 보는지 알 수 있다.
- 예를 들어, 개를 분류할 때 모델이 정말 개의 특징을 보고 있는지, 아니면 배경을 보고 있는지 확인할 수 있다.
- 약한 지도 학습 기반 물체 분할:
- Saliency Map을 이용해 별도의 세밀한 라벨링 없이도 이미지에서 물체의 위치를 대략적으로 찾아낼 수 있다.
- 이는 데이터 라벨링에 들어가는 시간과 비용을 크게 줄일 수 있는 방법이다.

결론
이 연구는 딥러닝 모델, 특히 이미지 분류 모델의 내부 작동을 이해하는 데 큰 도움을 준다:
- 모델의 ‘상상력’ 엿보기: 클래스 모델 시각화를 통해 모델이 각 클래스에 대해 어떤 특징을 학습했는지 볼 수 있다.
- 모델의 ‘주목점’ 파악하기: Saliency Map을 통해 모델이 예측을 할 때 이미지의 어떤 부분에 집중하는지 알 수 있다.
- 새로운 가능성 열기: 이 기술을 응용해 물체 분할과 같은 다른 작업도 수행할 수 있다.
이 연구는 “설명 가능한 AI(XAI)”라는 중요한 연구 분야의 시작점이 되었다. 이를 통해 우리는 딥러닝 모델을 더 잘 이해하고, 신뢰하고, 개선할 수 있게 되었다.
원본
핵심요약
- 이미지 분류 모델이 학습한 것을 가시화 하는 방법론.
- 딥러닝 모델을 분석하는 툴로써 사용할 수 있으며, weakly supervised object segmentation에 적용 가능함.
Introduction
딥러닝 모델은 많은 발전을 통해서 높은 성능을 계속 갱신해가고 있지만, 내부의 operation이 어떤 작용을 하고 있는 지에 대한 분석은 부족한 것이 사실이다. 본 연구는 이미지 분류 모델에 대한 분석을 진행할 수 있는 Saliency map이라는 방법을 제안하며, 이를 통해서 모델의 분석을 넘어 Weakly supervised object segmentation task에도 적용이 가능한 것을 실험을 통해서 보인다.
Class Model Visualization
이미지 데이터셋에 대해서 학습이 진행된 모델은 어떤 class에 대해서 이미 어느정도의 지식을 가지고 있다. 인간을 예로 들면, 실제 모습을 보지 않더라도 강이지의 모습을 떠올리는 것이 가능하다. 딥러닝 모델에 이러한 아이디어를 접목시킨 것이 Class Model Visualization 방법이다.
이 방식은 Image를 생성하는 작업인데, 딥러닝 모델의 파라미터는 고정을 하고, 입력 이미지의 각 픽셀의 값들을 업데이트하며 아래의 수식을 최대화 하는 방향으로 학습이 진행된다.
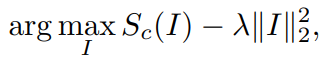
$S_c(I)$ 는 Image I에 대해서 network가 prediction을 한 class c에 대한 score이다. 따라서 이미지를 업데이트를 진행하는데, target class c라고 모델이 분류하도록 업데이트를 하는 것으로 볼 수 있다. 뒤에 있는 term은 regularization term이다.
위 이미지는 Class Model Visualization을 통해서 생성한 이미지이다. 예시로 덤벨에 대한 이미지를 보면, 입력 이미지를 전혀 넣지 않았지만, 덤벨의 형상이 보이는 이미지가 생성된것을 볼 수가 있다. 이러한 이미지들이 학습된 네트워크가 타켓 클래스에 대해서 어떤 이미지를 상상하는가에 대한 답변으로 볼 수 있다.
Image-specific Class Saliency Visualization
모델을 아주 간단히 경량화하여 생각해보면, output score S_c(I)는 입력 이미지와 weight와 bias가 더해진 형태로 생각할 수 있다.
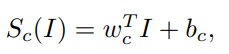
이때, weight는 아래의 식으로 표현할 수 있고,
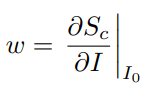
w는 이미지의 각 픽셀이 출력에 미치는 영향으로 볼 수 있다. 따라서 본 연구에서는 w를 saliency map이라고 부르며, 이 saliency map은 입력 이미지의 어떤 부분이 class prediction에 많은 영향을 미쳤는 지를 표현하는 explanation map으로 볼 수 있다.

위 figure는 입력 이미지에 대한 saliency map의 예시이다. 많이 노이지하지만 object 부분에서 더 높은 값을 가지는 것을 확인할 수 있다. 이러한 saliency map은 weakly supervised segmentation에도 적용할 수 있다.
GraphCut colour segmentation saliency map을 masking하면 맨 오른쪽이 결과를 얻게 된다. Saliency map을 통해서 충분히 이용가능한 segmentation map을 얻을 수 있음을 여러 이미지에 대한 실험을 통해서 확인할 수 있다.
Conclusion
본 논문은 CNN 모델을 분석하기 위한 XAI의 시초가 되는 논문으로, 2개의 saliency map을 제시한다.
한 방법은 이미 학습이 된 모델을 이용하여 target class에 대해 학습한 이미지를 생성하여 모델이 각 클래스에 대해서 어떤 특징들을 학습한 것이지에 대한 분석을 할 수 있고, 다른 방법은 모델의 출력에 대한 입력이미지의 미분맵을 saliency map으로 이용하여, 모델이 prediction을 함에 있어서 어떤 영역에 집중하였는지 를 분석할 수 있으며, 이를 이용하여 weakly supervised segmentation에 적용하여 매우 좋은 성능을 보이는 것을 확인할 수 있다.