5. Coordinating Parallel Threads.
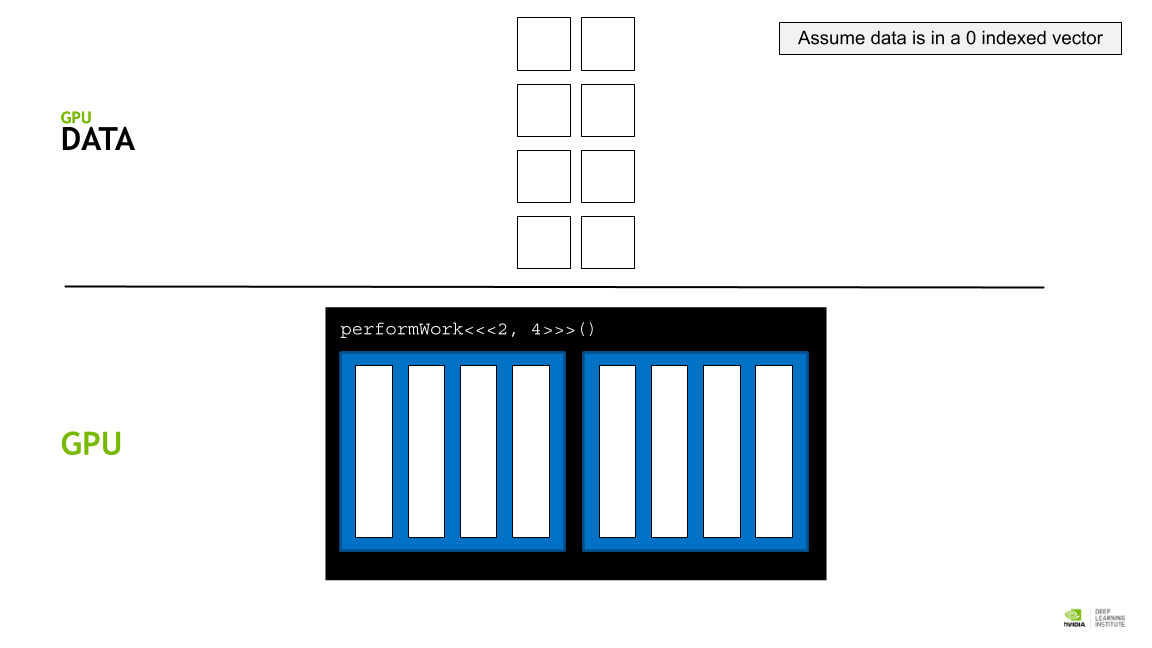
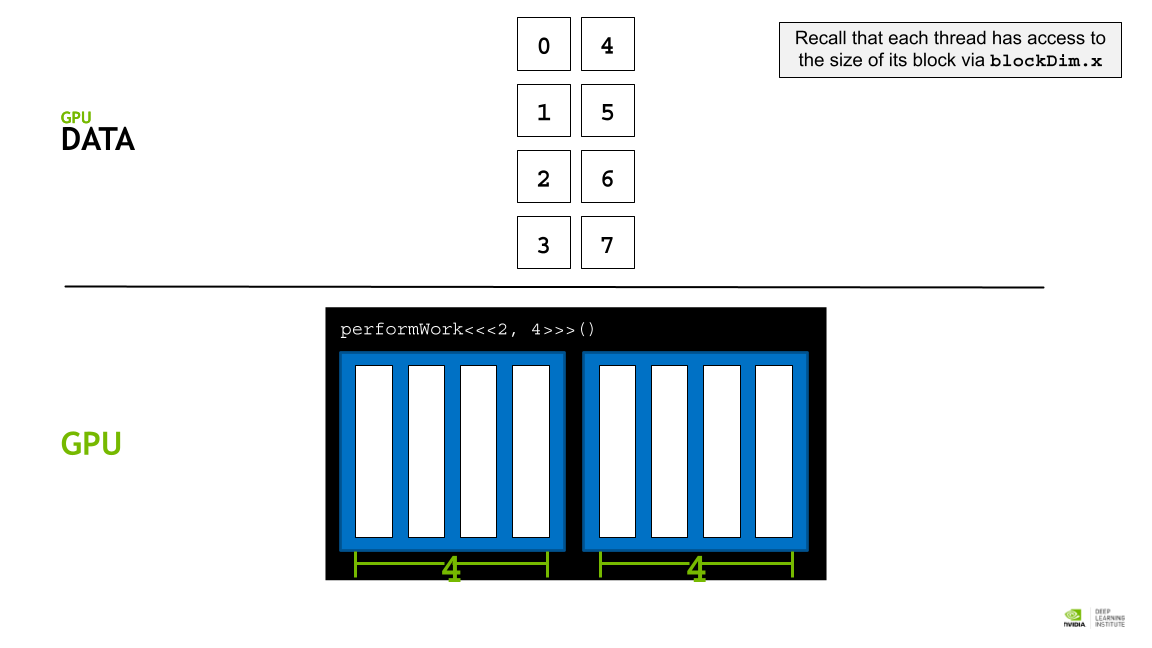
각 block에 존재할 수 있는 thread의 개수는 최대 1024개로 한계가 있다. 따라서 병렬처리의 효과를 더 크게 누리기 위해서는 여러 block들 간의 coordinate를 잘 해야 한다.
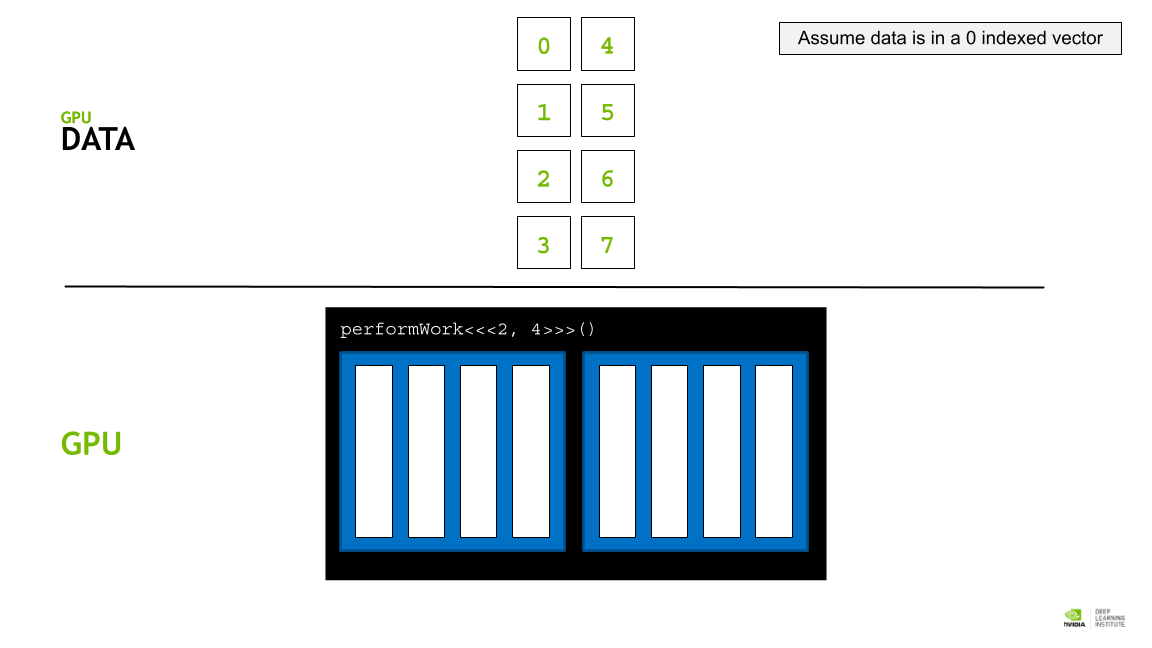
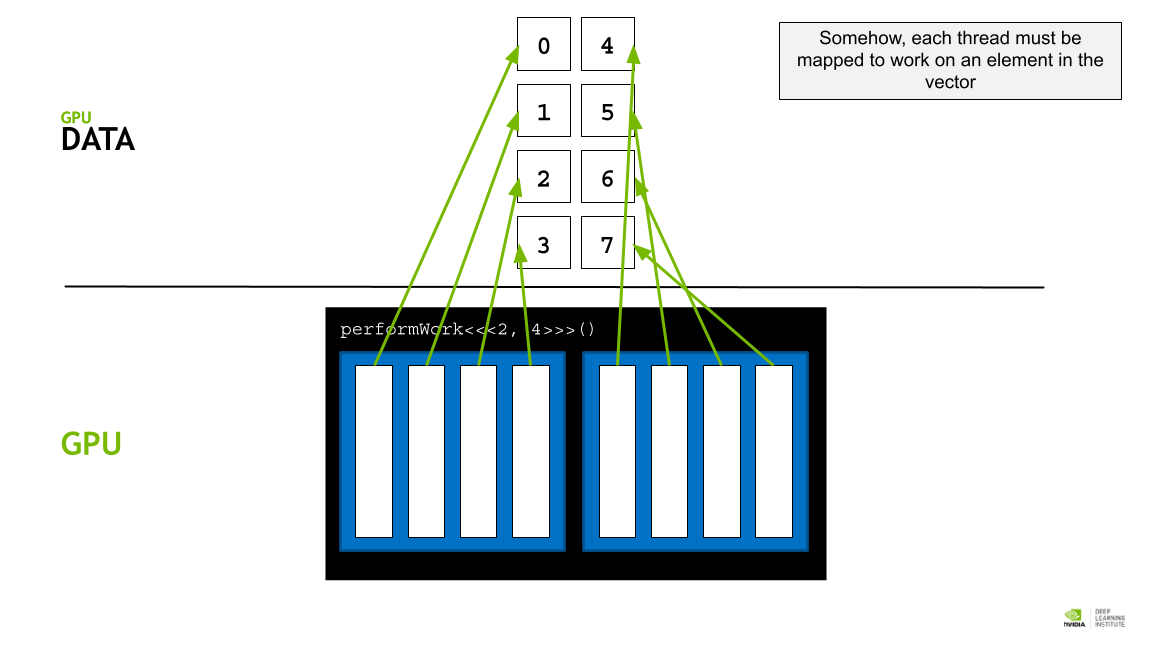
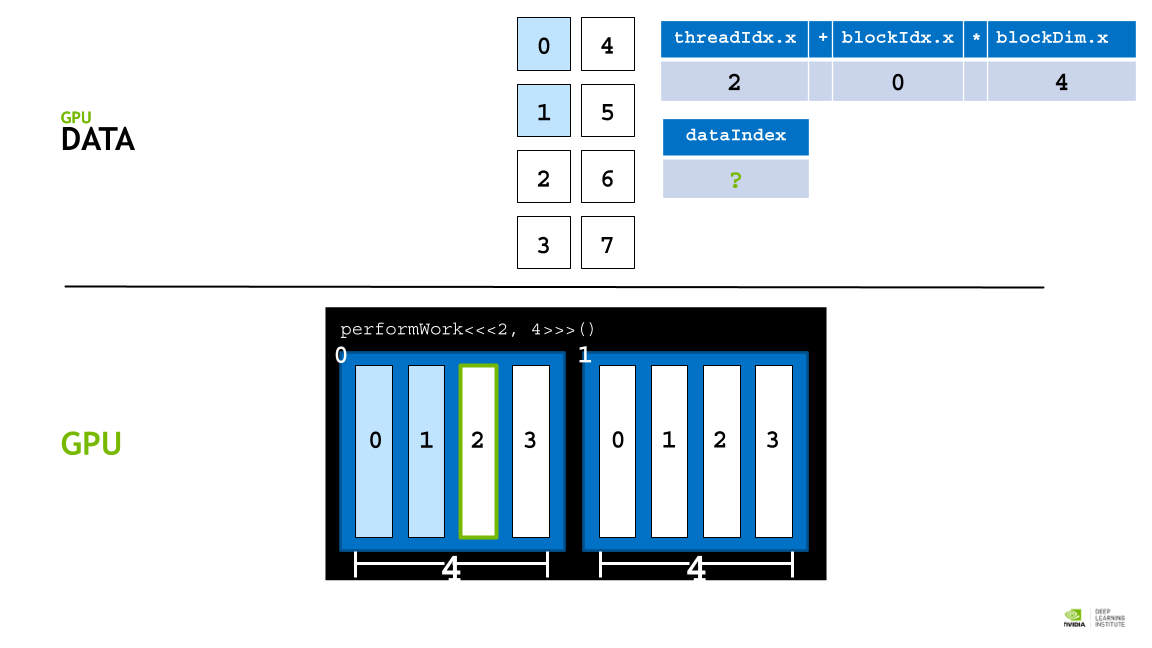
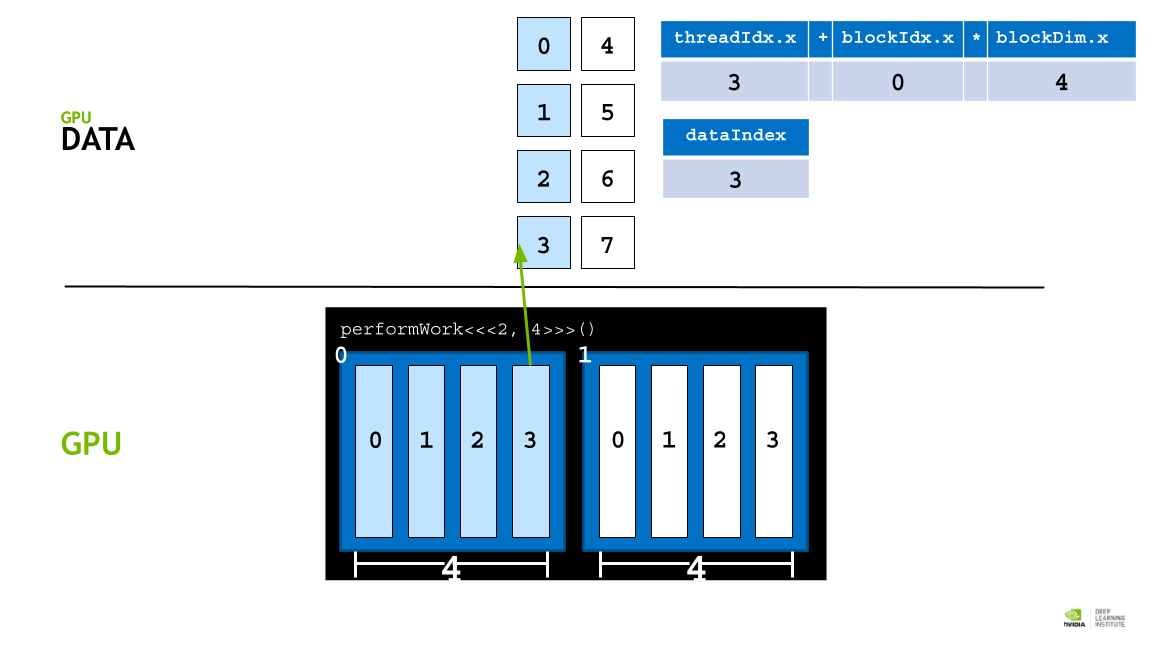
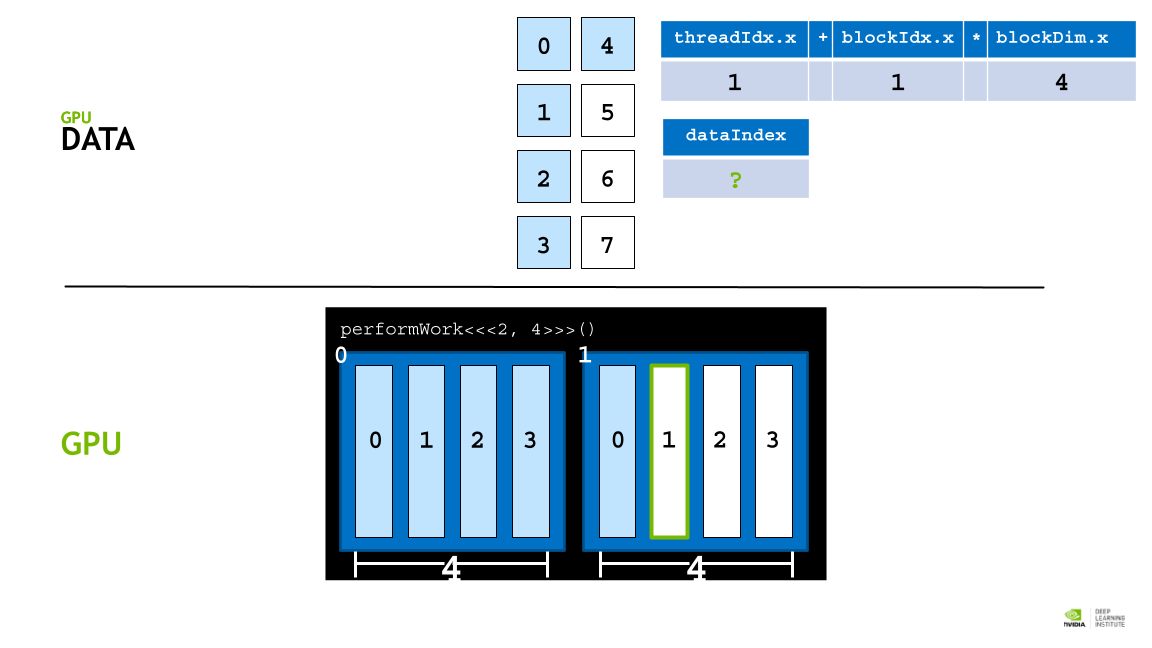
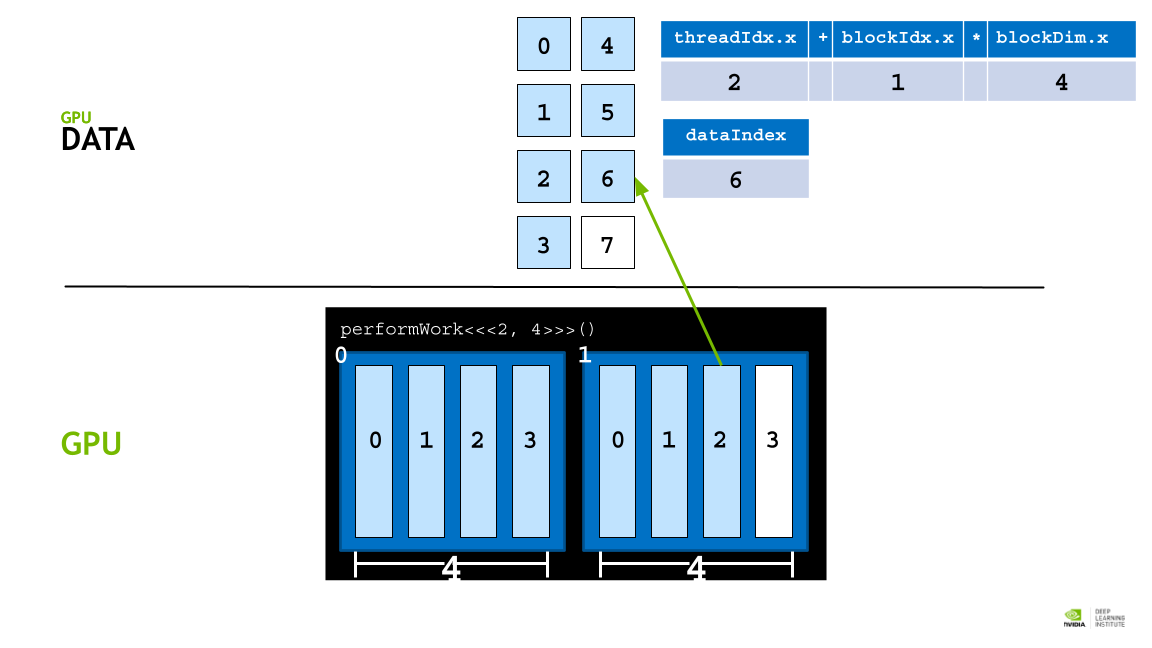
GPU thread 에 data 를 할당하기 위해 각, thread의 인덱스를 활용한 데이터 분배 접근 전략을 활용한다.
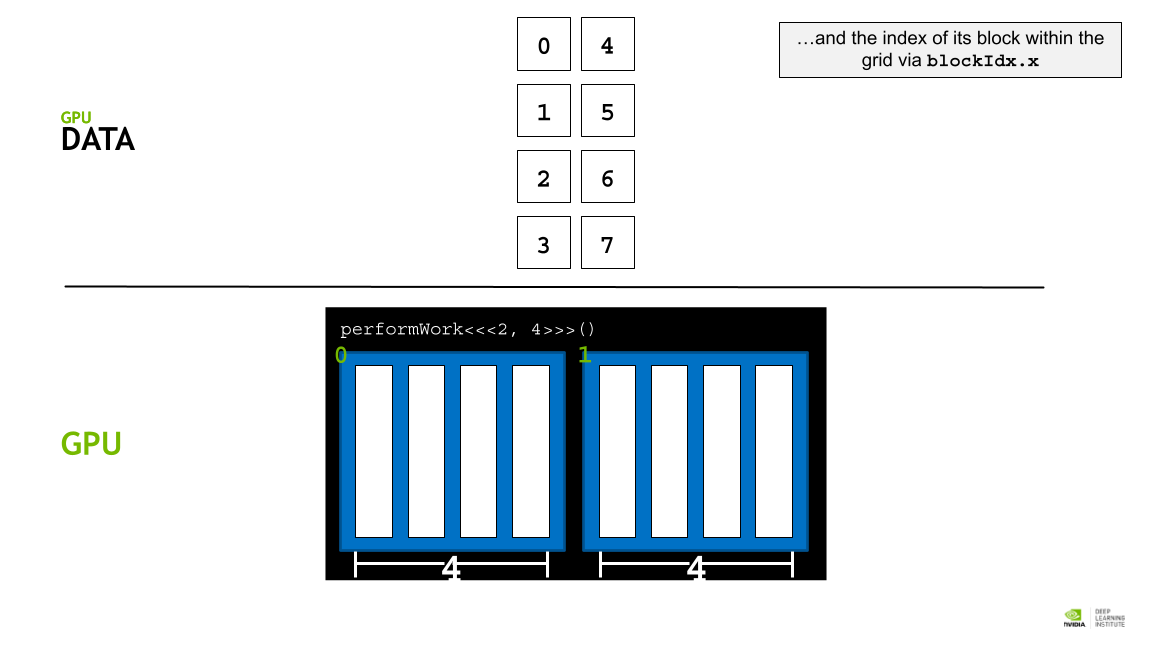
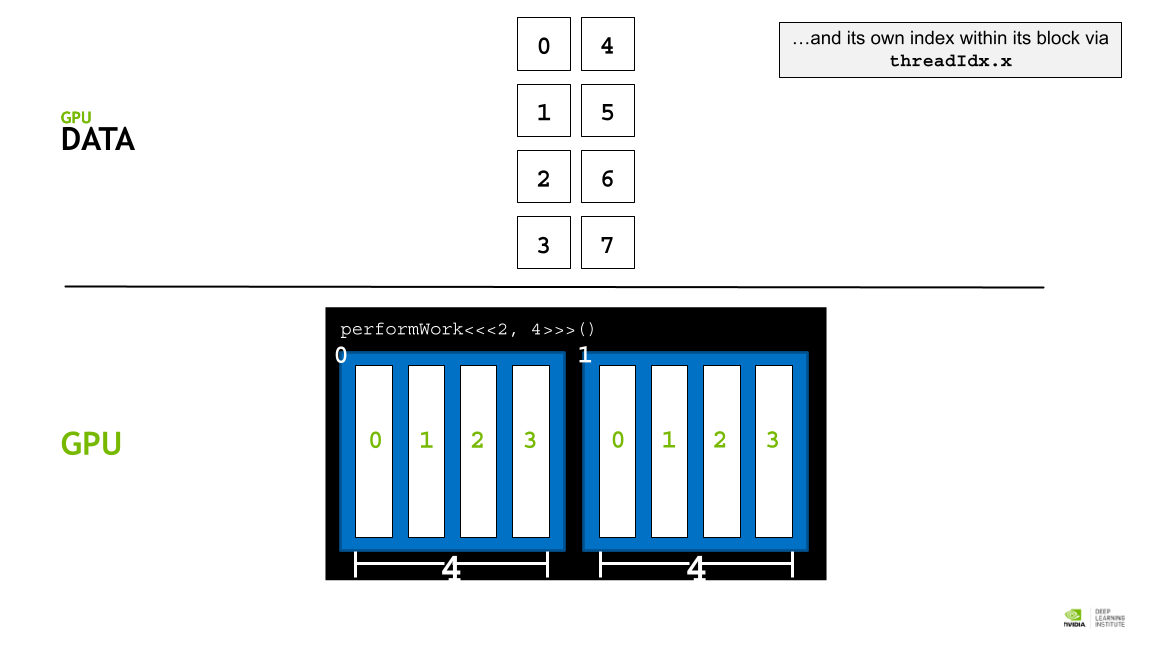
각 block의 사이즈는 blockDim.x 로 알 수 있고, 인덱스는 blockId.x로 접근할 수 있다. 또 각 thread의 인덱스는 theradIdx.x 로 접근할 수 있다.
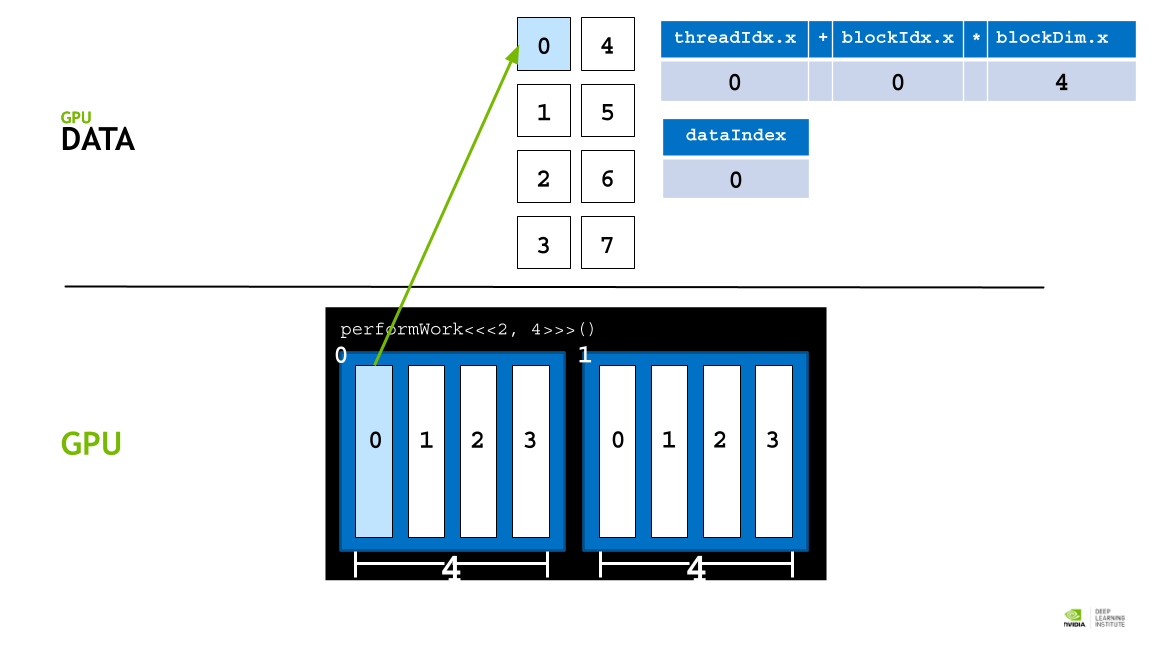
따라서 threadIdx.x + blockIdx.x * blockDim.x 라는 공식을 활용해 데이터를 thread에 매핑할 수 있다. (스레드 인덱스 + 블록 인덱스 * 쓰레드 갯수)
Exercise: Accelerating a For Loop with Multiple Blocks of Threads
이전에 병렬화 한 반복문을, 최소 2개 이상의 block을 활용해 병렬화 시키면
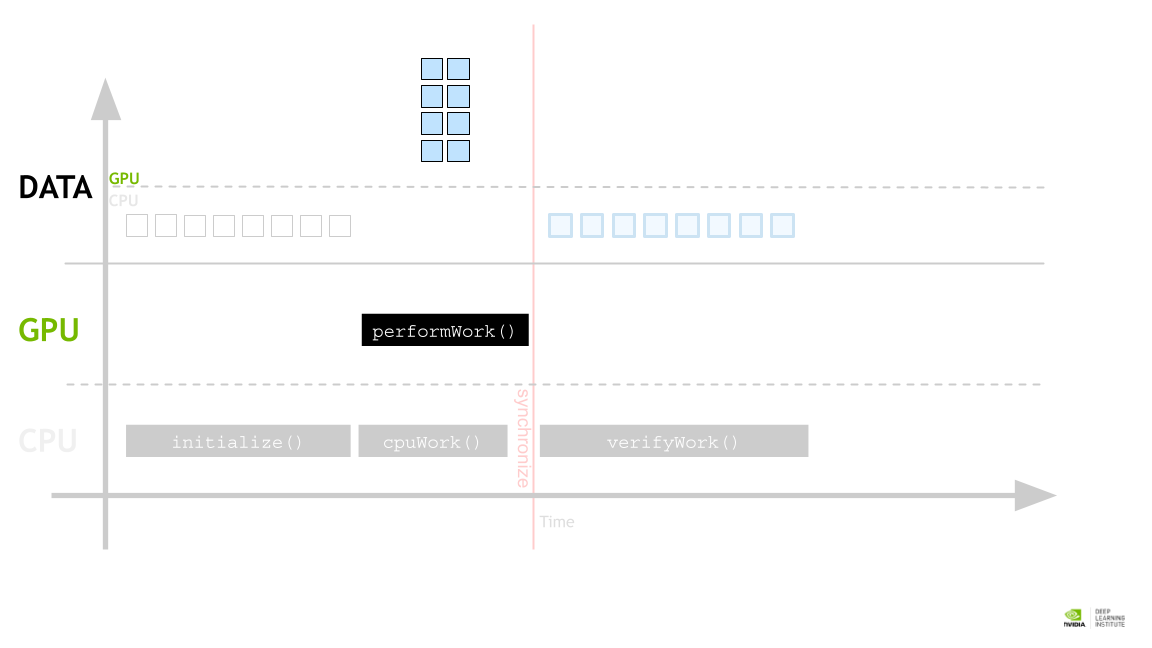
Allocating Memory to be accessed on the GPU and the CPU
CPU-only application에서는 C가 malloc과 free를 사용해 메모리를 할당하고 해제하지만, GPU 가속을 할 때는 cudaMallocManaged 와 cudaFree를 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
// cpu-only
// N을 2의 21승(2^21 = 2,097,152)으로 정의합니다.
// 이는 배열의 원소 수를 지정하는 데 자주 사용됩니다.
int N = 2<<20;
// 배열의 전체 크기를 바이트 단위로 계산합니다. int가 일반적으로 4바이트를
// 필요로 하므로 크기는 N과 int의 크기를 곱한 것입니다.
size_t size = N * sizeof(int);
// 할당할 메모리를 가리킬 int형 포인터를 선언합니다.
int *a;
// 힙에 N개의 정수 배열을 위한 메모리를 할당합니다. malloc 함수는
// 할당된 메모리 블록의 시작 부분을 가리키는 포인터를 반환합니다.
a = (int *)malloc(size);
// CPU 전용 프로그램에서 'a'를 사용하여 N개의 정수를 저장하고 조작할 수 있습니다.
// malloc에 의해 할당된 메모리를 해제하여 메모리 누수를 방지합니다.
// 사용 후 할당된 메모리를 해제하는 것은 자원을 해제하는 데 중요합니다.
free(a);
// 새로운 메모리 할당 예제를 위해 동일한 값으로 N을 다시 초기화합니다.
int N = 2<<20;
// 배열의 전체 크기를 바이트 단위로 다시 계산합니다.
size_t size = N * sizeof(int);
// CUDA 관리 메모리 사용을 위한 포인터를 선언합니다.
int *a;
// CPU와 가속 시스템의 GPU 모두에서 접근 가능한 메모리를 할당합니다.
// cudaMallocManaged는 CPU와 GPU 간의 명시적 복사 없이 데이터 공유를
// 쉽게 해주는 통합 메모리 관리를 수행합니다.
// 참고: cudaMallocManaged는 첫 번째 인수로 포인터 변수의 주소('&a')를,
// 두 번째 인수로 할당할 메모리의 크기를 필요로 합니다.
cudaMallocManaged(&a, size);
// 관리 메모리 'a'는 이제 CPU와 GPU에서 프로그램의 작업에 사용될 수 있습니다.
// 이 통합 메모리는 코딩을 간단하게 하지만 적절한 동기화가 필요합니다.
// cudaMallocManaged에 의해 할당된 메모리를 해제하여 메모리 누수를 방지하고
// 사용 후 자원이 제대로 해제되도록 합니다.
cudaFree(a);
Exercise: Array Manipulation on both the Host and Device
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
#include <stdio.h>
/*
* Initialize array values on the host.
*/
void init(int *a, int N)
{
int i;
for (i = 0; i < N; ++i)
{
a[i] = i;
}
}
/*
* Double elements in parallel on the GPU.
*/
__global__
void doubleElements(int *a, int N)
{
int i;
i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N)
{
a[i] *= 2;
}
}
/*
* Check all elements have been doubled on the host.
*/
bool checkElementsAreDoubled(int *a, int N)
{
int i;
for (i = 0; i < N; ++i)
{
if (a[i] != i*2) return false;
}
return true;
}
int main()
{
int N = 100;
int *a;
size_t size = N * sizeof(int);
/*
* Refactor this memory allocation to provide a pointer
* `a` that can be used on both the host and the device.
*/
a = (int *)malloc(size);
init(a, N);
size_t threads_per_block = 10;
size_t number_of_blocks = 10;
/*
* This launch will not work until the pointer `a` is also
* available to the device.
*/
doubleElements<<<number_of_blocks, threads_per_block>>>(a, N);
cudaDeviceSynchronize();
bool areDoubled = checkElementsAreDoubled(a, N);
printf("All elements were doubled? %s\n", areDoubled ? "TRUE" : "FALSE");
/*
* Refactor to free memory that has been allocated to be
* accessed by both the host and the device.
*/
free(a);
}
// All elements were doubled? FALSE
위 코드를 배열 포인터 a가 CPU와 GPU 코드에서 모두 쓰일 수 있게, 또 a를 정확히 메모리 해제해야 한다는 점에 유의해서 수정하면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
// 전위연산자
int i = 5;
int j = ++i; // i를 1 증가시킨 후, j에 그 값을 할당.
// 결과: i는 6, j도 6
// 후위연산자
int i = 5;
int j = i++; // i의 현재 값을 j에 할당한 후, i를 1 증가.
// 결과: i는 6, j는 5
// 사용 시 고려 사항
/*
- 전위 연산자: 일반적으로 전위 연산자는 후위 연산자보다 빠르다.
왜냐하면 전위 연산자는 변수 값을 직접 증가시키고 그 값을 반환하기 때문에, 추가적인 임시 변수가 필요 없기 때문이다.
- 후위 연산자: 후위 연산자는 현재 값을 저장하기 위해 임시 변수가 필요하므로, 특히 객체와 같이 크기가 큰 데이터 타입에서 성능에 영향을 줄 수 있다.
*/
#include <stdio.h>
// 배열의 각 원소를 초기화하는 함수입니다.
// 배열에 인덱스와 같은 값으로 초기화합니다.
void init(int *a, int N)
{
int i;
for (i = 0; i < N; ++i)
{
a[i] = i;
}
}
// GPU에서 실행될 CUDA 커널 함수입니다.
// 배열의 각 원소를 두 배로 증가시킵니다.
__global__ void doubleElements(int *a, int N)
{
int i;
// 각 스레드의 고유 인덱스를 계산합니다.
i = blockIdx.x * blockDim.x + threadIdx.x;
// 계산된 인덱스가 배열 크기 내에 있을 때만 연산을 수행합니다.
if (i < N)
{
a[i] *= 2;
}
/*
예를 들어, `N`이 10이고, `threads_per_block`이 6 이며, `number_of_blocks`가 2 이라고 가정해보면,
이 설정으로 총 12 개의 쓰레드가 생성되지만 실제로는 10 개의 데이터만 처리해야 한다.
따라서 인덱스 10 이상인 쓰레드는 `a[i] *= 2;` 연산을 수행해서는 안 된다.
이를 위해 `if (i < N)` 조건을 사용하여 인덱스가 10 이상인 쓰레드가 배열에 접근하는 것을 방지한다.
이러한 조건을 포함함으로써, 모든 쓰레드가 안전하게 배열 내의 유효한 범위 내에서만 작업을 수행하도록 보장할 수 있다. 이것이 CUDA 프로그래밍에서 배열 경계를 체크하는 이유이며, 많은 병렬 컴퓨팅 시나리오에서 중요한 안전 조치이다.
*/
}
// 배열의 모든 원소가 올바르게 두 배로 증가되었는지 검사하는 함수입니다.
bool checkElementsAreDoubled(int *a, int N)
{
int i;
for (i = 0; i < N; ++i)
{
// 원소 값이 인덱스의 두 배와 다르면 false 반환
if (a[i] != i*2) return false;
}
// 모든 검사를 통과하면 true 반환
return true;
}
// 메인 함수
int main()
{
int N = 100; // 처리할 원소의 수
int *a;
size_t size = N * sizeof(int); // 필요한 메모리 크기 계산
// CUDA 관리 메모리 할당
// 이 메모리는 CPU와 GPU가 공유할 수 있습니다.
cudaMallocManaged(&a, size);
// 배열 초기화
init(a, N);
// 커널 실행을 위한 설정
size_t threads_per_block = 10; // 블록 당 스레드 수
size_t number_of_blocks = 10; // 블록 수
// 커널 함수 실행
// 배열 원소를 두 배로 증가시키는 작업을 GPU에서 수행
doubleElements<<<number_of_blocks, threads_per_block>>>(a, N);
// GPU 작업이 완료될 때까지 CPU가 대기
cudaDeviceSynchronize();
// 모든 원소가 올바르게 두 배로 처리되었는지 확인
bool areDoubled = checkElementsAreDoubled(a, N);
printf("All elements were doubled? %s\n", areDoubled ? "TRUE" : "FALSE");
// 사용이 끝난 메모리 해제
cudaFree(a);
}
// All elements were doubled? TRUE
후위연산자의 경우 현재 값을 리턴한 후에, 값을 증가 해야 하기 때문에 내부에 복사 생성을 하게되고 클래스의 크기가 커지면 커질수록 복사생성의 오버헤드가 커질것이다.
Grid Size Work Amount Mismatch
우리가 사용하려는 데이터가 grid 사이즈에 딱 맞으면 상관 없지만, 만약 그것보다 부족한 경우 사이즈가 맞지 않는다는 문제가 발생한다. 예를들어 grid 내에 thread 갯수가 8개인데 사용할 데이터는 5개 밖에 없으면 threadIdx.x + blockIdx.x * blockDim.x 공식으로 할당할 때 5, 6, 7번은 문제가 생긴다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// GPU에서 실행될 CUDA 커널 함수 정의입니다.
// 이 함수는 배열 또는 데이터 구조의 원소에 대해 병렬 연산을 수행할 수 있도록 설계되었습니다.
__global__ some_kernel(int N)
{
// 각 스레드의 고유 인덱스를 계산합니다.
int idx = threadIdx.x + blockIdx.x * blockDim.x;
// 인덱스가 주어진 N 범위 내에 있는지 확인합니다.
// 이 조건을 통해 배열 범위 밖의 메모리 접근을 방지합니다.
if (idx < N)
{
// 실제 작업이 이루어지는 부분입니다.
// 예를 들어, 배열의 원소를 수정하거나 계산을 수행할 수 있습니다.
}
}
// N은 처리해야 할 전체 원소의 수를 나타냅니다.
// 여기서는 N이 100,000으로 가정합니다.
int N = 100000;
// 블록 당 스레드 수를 256으로 설정합니다.
// 이 값은 GPU의 성능을 최적화하기 위한 선택이 될 수 있습니다.
size_t threads_per_block = 256;
// 전체 그리드에서 필요한 블록의 수를 계산합니다.
// 이 계산은 N을 threads_per_block로 나눈 후,
// 나머지가 있다면 블록 하나를 추가로 포함시키도록 합니다.
// 이를 통해 N개의 원소 모두가 처리될 수 있도록 합니다.
size_t number_of_blocks = (N + threads_per_block - 1) / threads_per_block;
// 커널을 실행합니다. 계산된 블록 수와 블록 당 스레드 수를 사용하여,
// GPU에 작업을 분배합니다. 이렇게 함으로써 GPU의 병렬 처리 능력을 활용할 수 있습니다.
some_kernel<<<number_of_blocks, threads_per_block>>>(N);
그래서 위와 같이 some_kernel 함수의 if 문 처럼 인덱스가 데이터의 크기보다 작을 때만 특정 기능을 실행하도록 설정해 준다.
Exercise: Accelerating a For Loop with a Mismatched Execution Configuration
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
#include <stdio.h>
/*
* Currently, `initializeElementsTo`, if executed in a thread whose
* `i` is calculated to be greater than `N`, will try to access a value
* outside the range of `a`.
*
* Refactor the kernel defintition to prevent our of range accesses.
*/
__global__ void initializeElementsTo(int initialValue, int *a, int N)
{
int i = threadIdx.x + blockIdx.x * blockDim.x;
a[i] = initialValue;
}
int main()
{
/*
* Do not modify `N`.
*/
int N = 1000;
int *a;
size_t size = N * sizeof(int);
cudaMallocManaged(&a, size);
/*
* Assume we have reason to want the number of threads
* fixed at `256`: do not modify `threads_per_block`.
*/
size_t threads_per_block = 256;
/*
* Assign a value to `number_of_blocks` that will
* allow for a working execution configuration given
* the fixed values for `N` and `threads_per_block`.
*/
size_t number_of_blocks = 0;
int initialValue = 6;
initializeElementsTo<<<number_of_blocks, threads_per_block>>>(initialValue, a, N);
cudaDeviceSynchronize();
/*
* Check to make sure all values in `a`, were initialized.
*/
for (int i = 0; i < N; ++i)
{
if(a[i] != initialValue)
{
printf("FAILURE: target value: %d\t a[%d]: %d\n", initialValue, i, a[i]);
exit(1);
}
}
printf("SUCCESS!\n");
cudaFree(a);
}
// FAILURE: target value: 6 a[0]: 0
위 코드는 1000개의 integer를 cudaMallocManaged를 통해 메모리를 할당하고 있고, thread_per_blocks라는 이름의 변수로 block당 최대 thread 갯수를 정의하고 있다. 이에 따라 number_of_blocks 변수에 필요한 block의 갯수를 구해 할당해주고, initializeElementsTo 함수에 데이터 수보다 인덱스가 넘치는 경우 예외를 처리해주는 내용을 코드를 추가해주면 아래와 같은 코드로 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
#include <stdio.h>
/*
* 현재 `initializeElementsTo` 커널 함수는 스레드에서 계산된 `i`가 `N`보다 클 경우,
* 배열 `a`의 범위를 벗어난 값을 접근하려고 시도합니다.
* 범위를 벗어나는 접근을 방지하기 위해 커널 정의를 개선합니다.
*/
__global__ void initializeElementsTo(int initialValue, int *a, int N)
{
// 각 스레드의 고유 인덱스를 계산합니다.
int i = threadIdx.x + blockIdx.x * blockDim.x;
// 계산된 인덱스가 배열 크기 N 이하일 경우만 배열에 접근하여 초기화를 수행합니다.
if(i < N){
a[i] = initialValue;
}
}
int main()
{
/*
* `N`을 수정하지 마세요.
*/
int N = 1000;
int *a;
size_t size = N * sizeof(int);
// CUDA 통합 메모리를 사용하여 CPU와 GPU가 공유할 메모리를 할당합니다.
cudaMallocManaged(&a, size);
/*
* 스레드 수를 `256`으로 고정하고자 하는 경우가 있으므로 이를 변경하지 않습니다.
*/
size_t threads_per_block = 256;
/*
* 고정된 `N` 및 `threads_per_block` 값을 고려하여,
* 실행 구성이 작동할 수 있도록 `number_of_blocks` 값을 할당합니다.
*/
size_t number_of_blocks = (N + threads_per_block - 1) / threads_per_block; // 이거 내림함, 4.9 면 4로 나옴
// number_of_blocks: 4
// number_of_acc: 1024
int initialValue = 6;
// CUDA 커널을 실행하여 모든 원소를 주어진 초기값으로 설정합니다.
initializeElementsTo<<<number_of_blocks, threads_per_block>>>(initialValue, a, N);
// CUDA 작업의 완료를 기다립니다.
cudaDeviceSynchronize();
/*
* 배열 `a`의 모든 값이 올바르게 초기화되었는지 검사합니다.
*/
for (int i = 0; i < N; ++i)
{
// 초기화된 값이 예상과 다를 경우 실패 메시지를 출력하고 프로그램을 종료합니다.
if(a[i] != initialValue)
{
printf("FAILURE: target value: %d\t a[%d]: %d\n", initialValue, i, a[i]);
exit(1);
}
}
// 모든 값이 정상적으로 초기화되었을 경우 성공 메시지를 출력합니다.
printf("SUCCESS!\n");
// 할당된 메모리를 해제합니다.
cudaFree(a);
}
// SUCCESS!