3. Compiling and Running Accelerated CUDA Code.
Accelerating Applications with CUDA C/C++
GPU-accelerated VS. CPU-only Applications
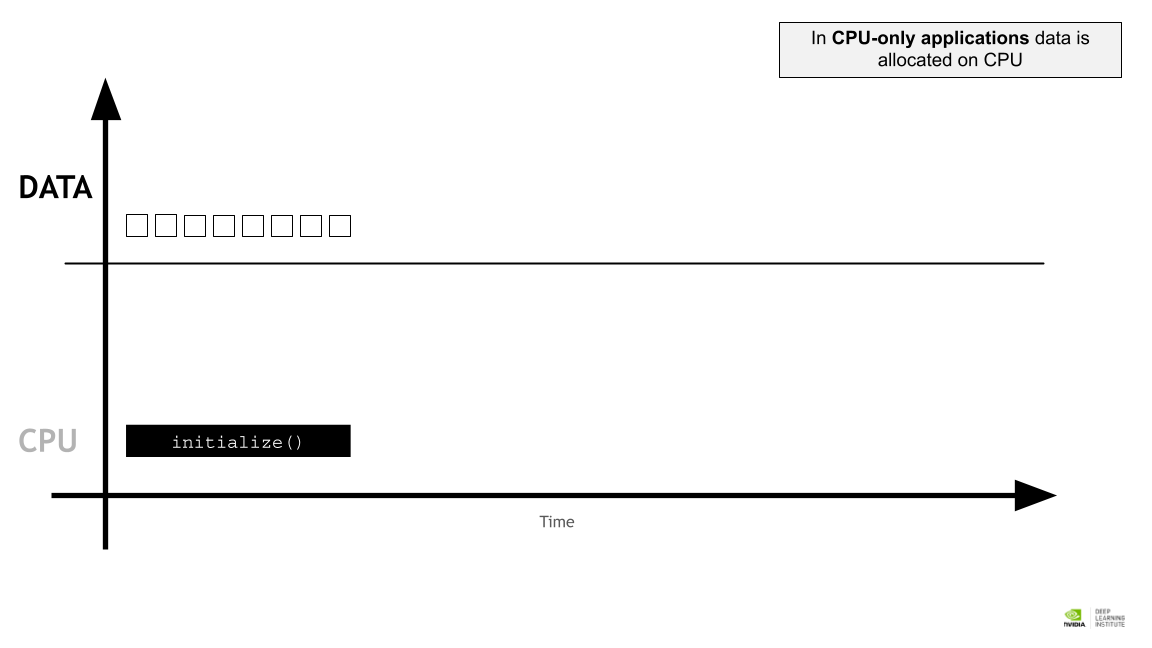 CPU전용 애플리케이션에서 데이터는 CPU 에 할당된다.
CPU전용 애플리케이션에서 데이터는 CPU 에 할당된다.
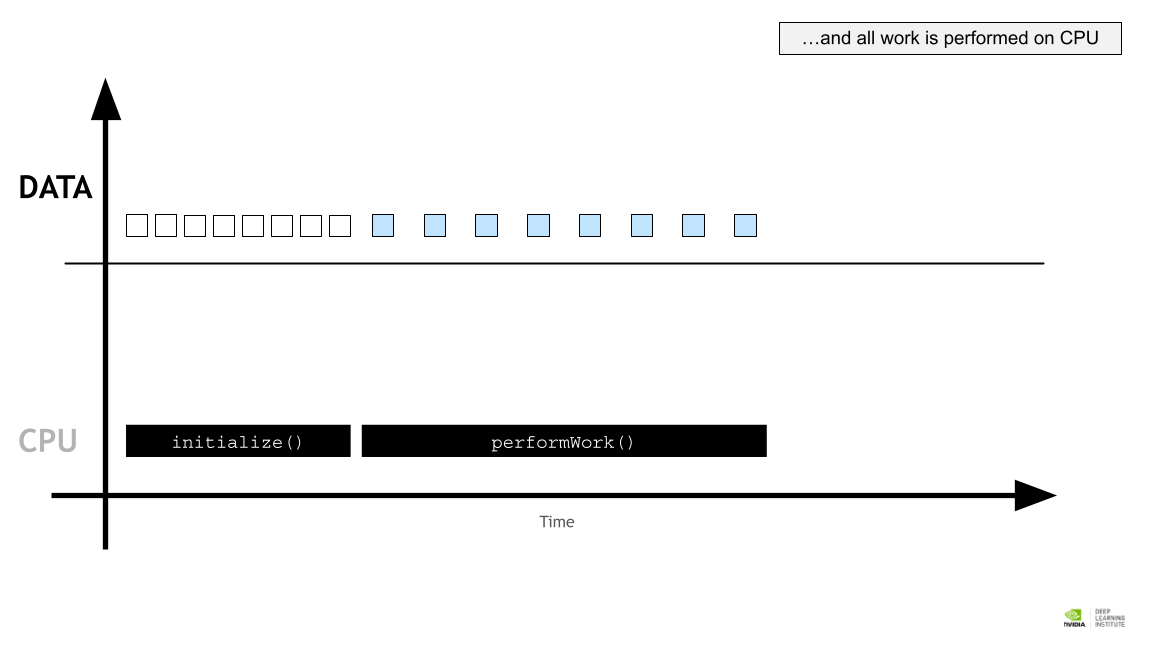
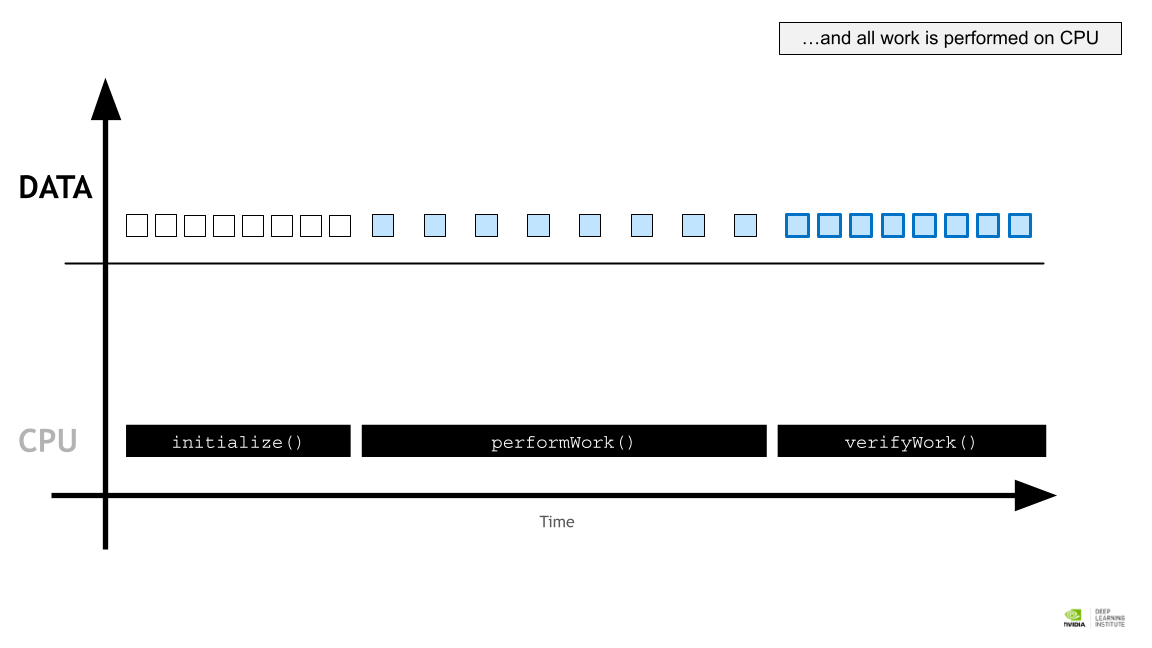 모든 작업은 CPU 에서 수행된다.
모든 작업은 CPU 에서 수행된다.
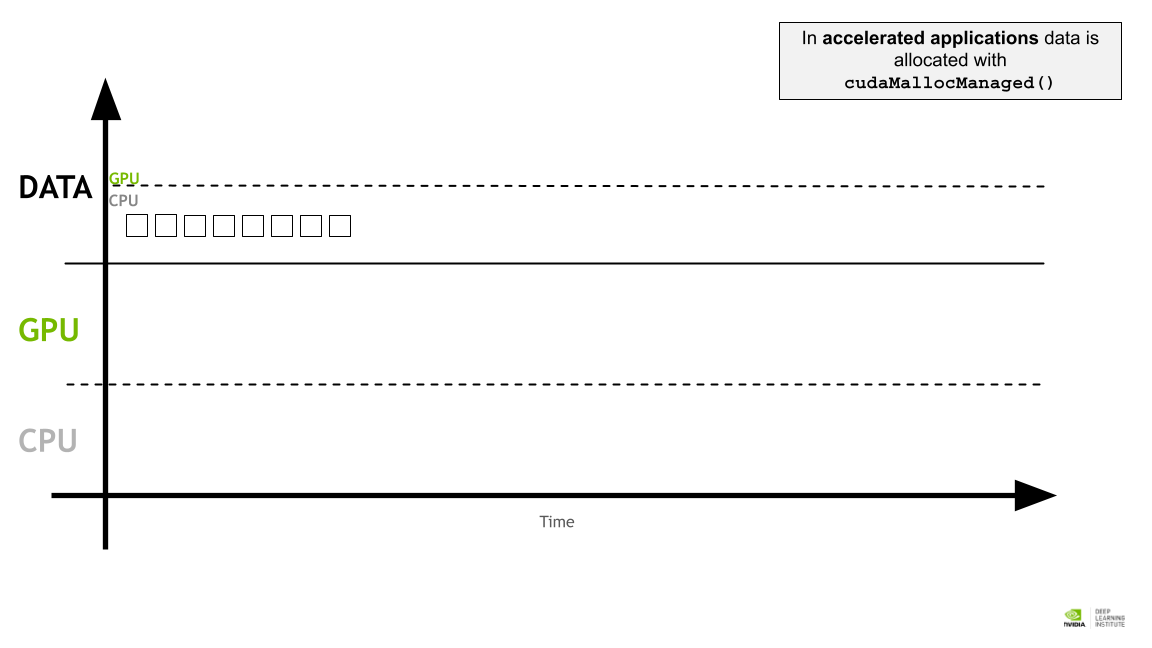 가속화된 애플리케이션에서는 cudaMallocManaged() 를 사용해 데이터가 할당된다.
가속화된 애플리케이션에서는 cudaMallocManaged() 를 사용해 데이터가 할당된다.
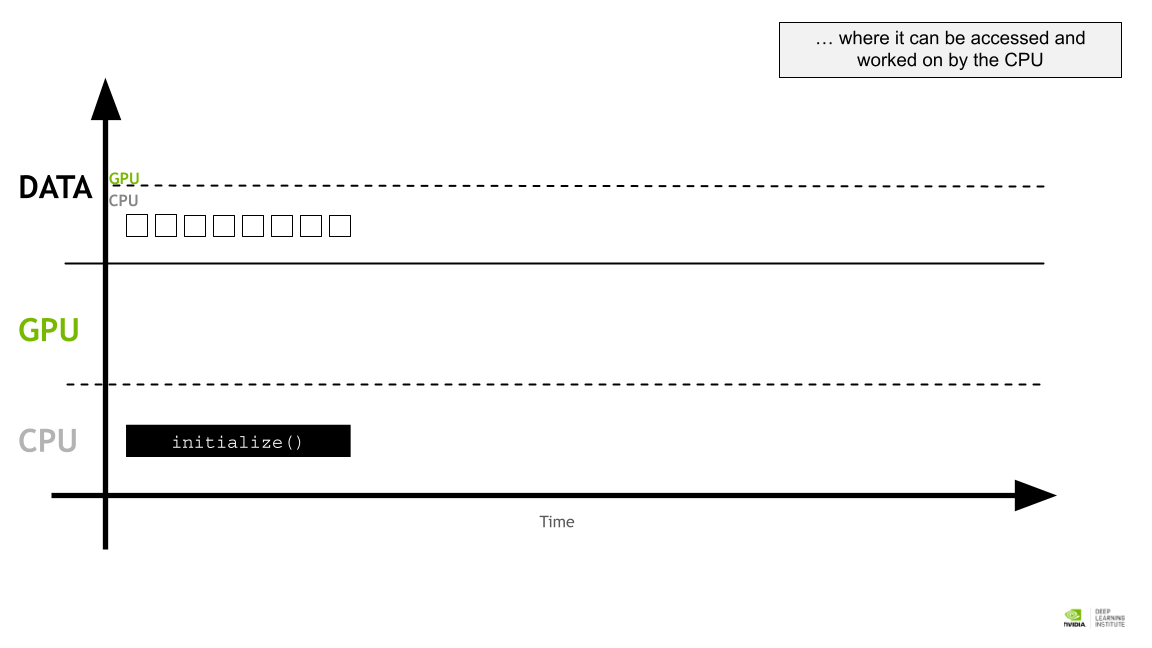 CPU가 엑세스하고 작업할 수 있는 곳.
CPU가 엑세스하고 작업할 수 있는 곳.
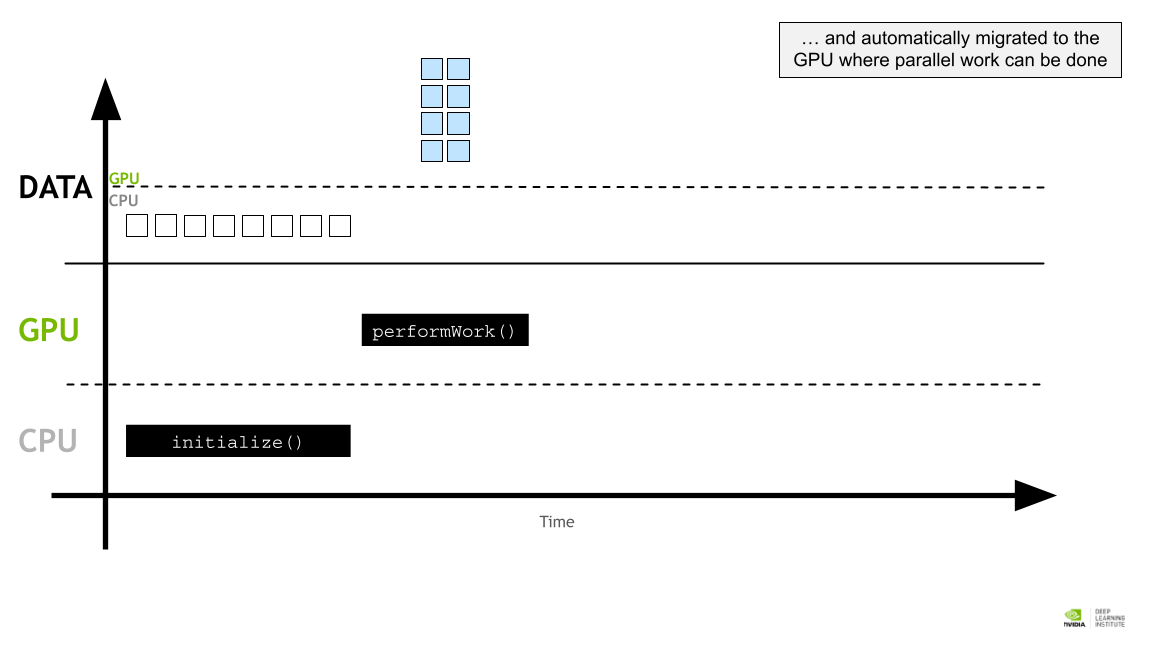 병렬작업을 수행할 수 있는 GPU로 자동 마이그레이션
병렬작업을 수행할 수 있는 GPU로 자동 마이그레이션
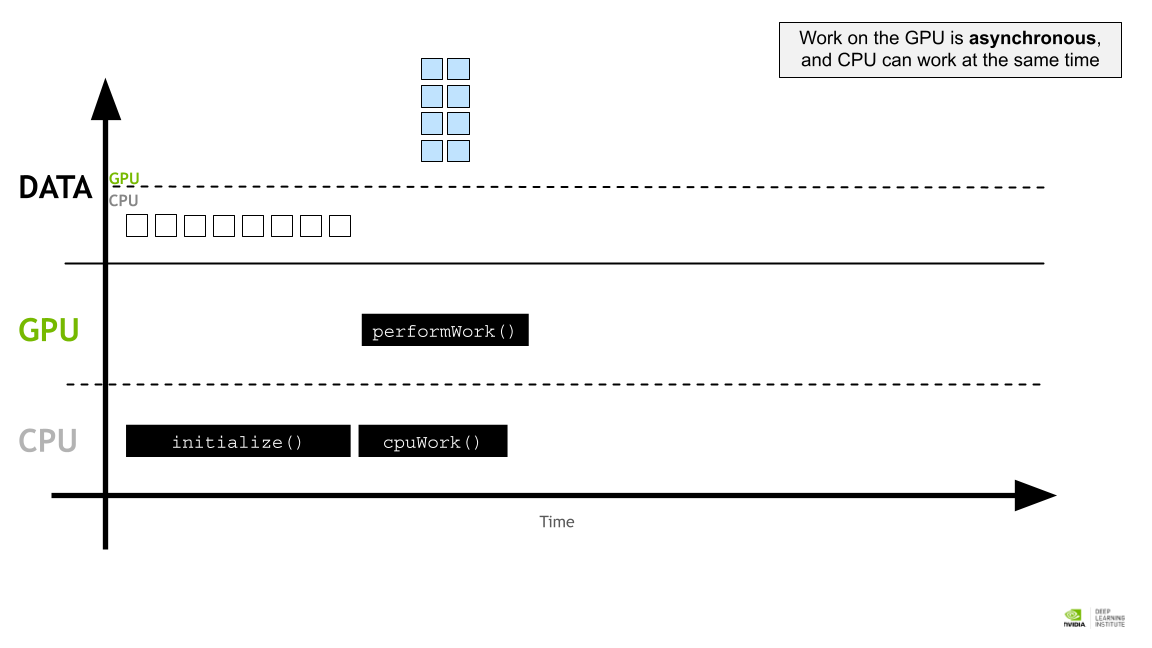 GPU 작업은 비동기식이며 CPU도 동시에 작업할 수 있다.
GPU 작업은 비동기식이며 CPU도 동시에 작업할 수 있다.
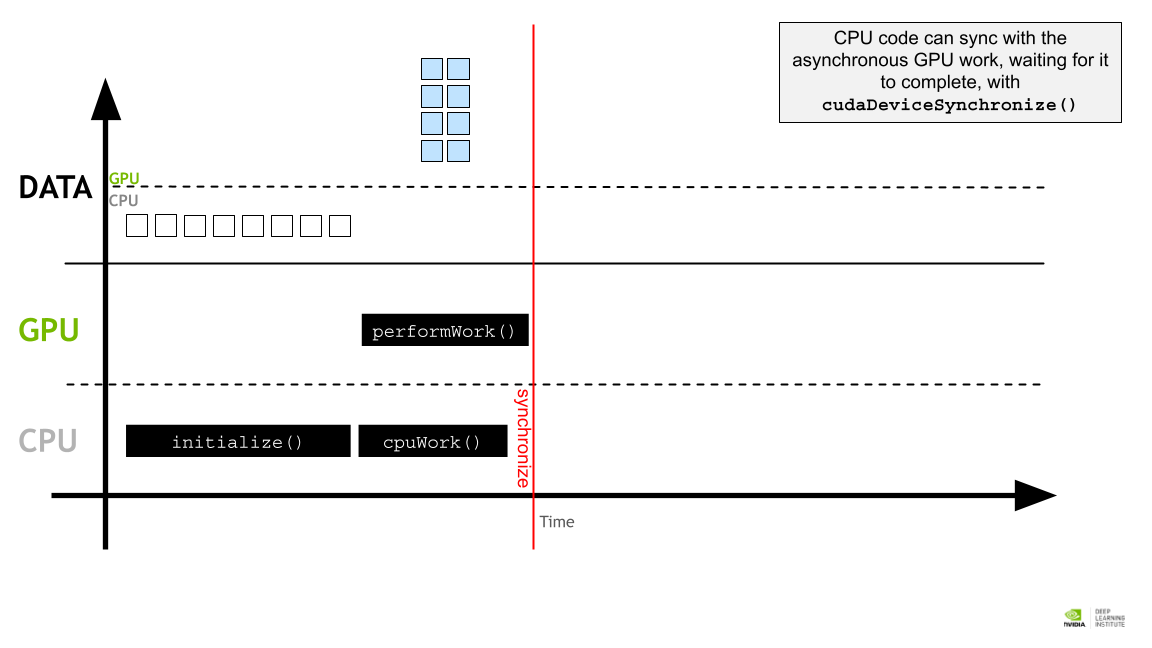 CPU 코드는 cudaDeviceSynchronize()를 사용하여 비동기 GPU 작업과 동기화 하여 작업이 완료될 때까지 기다린다.
CPU 코드는 cudaDeviceSynchronize()를 사용하여 비동기 GPU 작업과 동기화 하여 작업이 완료될 때까지 기다린다.
Writing Application Code for the GPU
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
void CPUFunction(){
printf("This function is defined to run on the CPU.\n");
}
__global__ void GPUFunction(){
printf("This function is defined to run on the GPU.\n");
}
int main(){
CPUFunction();
GPUFunction<<<1, 1>>>();
cudaDeviceSynchronize();
}
- ___global__ void GPUFunction()
- ___global__ 이라는 키워드가 GPU에서 돌아간다는 사실을 명시해준다.
- GPUFunction«<1, 1»>();
- GPU에서 작동하는 이러한 함수를 kernel이라 부르며, thread hierarchy를 명시해준다고 한다.
- 인자 중 앞의 1은 실행될 쓰레드 그룹의 개수를 명시하며, block 이라 부른다.
- 인자 중 뒤의 1은 각 block 내에 몇개의 쓰레드가 실행될 것인지를 명시한다.
- cudaDeviceSynchronize();
- 이후 계산된 값을 CPU와 synchronize하여 작동하게 하기 위해서는, 이 함수를 사용해야 한다.
Compiling and Running Accelerated CUDA Code
.c 파일을 gcc로 컴파일하는것 처럼, .cu 파일은 nvcc 라는 NVIDIA CUDA Compiler 로 컴파일한다. 다음과 같이 쓸 수 있다.
1
nvcc -arch=sm_86 -o out some-CUDA.cu -run
옵션 - arch: 컴파일 되는 환경의 GPU아키텍쳐를 명시해준다. sm_70의 경우 Volta 아키텍쳐를 명시해준다. - Virtual Architecture Feature List - 현재 사용하는 GPU는 RTX3090[Ampere]이므로 CUDA Compute Capability 8.6 이다. 따라서 sm_86을 사용 - o : 아웃풋 파일의 이름을 명시해준다. - run: 편의를 위한 옵션. 이 옵션을 쓰면 컴파일한 바이너리 파일을 실행해준다.
This post is licensed under CC BY 4.0 by the author.