12. CNN을 이용한 Image Localization 구현
데이터셋 경로 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
"""
이미지 데터와 bounding box 데이터 갯수 확인
"""
cur_dir = os.getcwd()
data_dir = os.path.join(cur_dir, 'datasets/oxford_pet')
image_dir = os.path.join(data_dir, 'images')
# 모든 운영체제에 맞추려면 따로 쓰는게 좋다
bbox_dir = os.path.join(image_dir, 'annotations', 'xmls')
# 리스트 컴프리헨션
image_files = [fname for fname in os.listdir(image_dir)
if os.path.splitext(fname)[-1] == 'jpg']
"""
- os.getcwd() 함수는 현재 작업중인 디렉토리의 경로를 반환
- os.listdir(path) 함수는 지정된 경로의 디렉토리 내 모든 파일과 디렉토리 목록을 반환
- os.path.splitext() 함수는 파일 이름을 이름과 확장자로 분리 [0]은 파일 이름, [-1]은 확장자
"""
bbox_file = [fname for fname in os.listdir(bbox_dir)
if os.path.splitext(fname)[-1] == 'xml']
n_bboxes = len(bbox_file)
데이터 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# n_bboxes는 길이니까 -1 (8 = 0 ~ 7)
rnd_idx = random.randint(0, n_bboxes - 1)
bbox_name = bbox_files[rnd_idx]
bbox_path = os.path.join(bbox_dir, bbox_name)
"""
xml.etree.ElementTree 모듈의 축약형
XML파일 구조를 읽고 그 구조를 트리 형태의 데이터 구조로 변환
"""
tree = et.parse(bbox_path)
# .text속성은 해당 요소의 텍스트 내용을 나타냄(ex) <xmin>100</xmin> => 문자열 100 반환
xmin = float(tree.find('./object/bndbox/xmin').text)
ymin = float(tree.find('./object/bndbox/ymin').text)
xmax = float(tree.find('./object/bndbox/xmax').text)
ymax = float(tree.find('./object/bndbox/ymax').text)
rect_x = xmin
rect_y = ymin
rect_w = xmax - xmin
rect_h = ymax - ymin
fname = os.path.splitext(bbox_name)[0] + '.jpg'
fpath = os.path.join(image_dir, fname)
image = Image.open(fpath)
image = np.array(image)
"""
Rectangle((x, y), width, height ,angle, fill, color, ...)
- xy: (필수) 사각형의 왼쪽 하단 모서리 좌표를 나타내며 튜플 형태로 `(x, y)`를 입력
- width: (필수) 사각형의 너비
- height: (필수) 사각형의 높이
- angle: 사각형의 회전 각도. 기본값은 0
- fill: 사각형 내부를 채울지 여부를 결정. `True` 또는 `False`로 설정할 수 있으며,
기본값은 `True`
- color: 사각형의 테두리 및 내부 색상을 지정. 색상은 이름, 헥사코드, RGB 튜플 등
다양한 방식으로 지정할 수 있다.
plt.axis() : 현재 활성화된 축 객체를 반환하거나 새로운 축 객체를 생성
여기서는 새로운 축 객체를 생성하고 이를 반환
.add_patch(rect) : axes 객체에 패치(여기서는 Rectangle 객체인 rect)를 추가
이를 통해 rect로 정의된 사각형이 해당 축에 그려진다.
"""
rect = Rectangle((rect_x, rect_y), rect_w, rect_h, fill = False, color = 'red')
plt.axes().add_patch(rect)
plt.imshow(image)
plt.show()
"""
재미있는 점
- TensorFlow에서의 이미지 처리 시 xmin, ymin은 왼쪽 상단
- Matplotlib에서의 Rectangle 처리시 xmin, ymin은 왼쪽 하단
"""
RGB 외의 data 삭제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
for image_file in image_files:
image_path = os.path.join(image_dir, image_file)
bbox_file = os.path.splitext(image_file)[0] + '.xml'
bbox_path = os.path.join(bbox_dir, bbox_file)
"""
PIL Image객체를 반환 받은 image의 mode 속성은 해당 이미지 객체의 색상모드를 나타낸다.
- RGB : 표준 RGB 색상 모드
- RGBA : 알파 채널(투명도)이 추가된 모드
- L : 흑백 이미지를 나타내는 단일 채널 모드 L은 빛의 발기를 나타냄
- CMYK : 시안 마젠타, 노랑, 검정 채널을 가진 인쇄용 색상 모드
- P : 팔레트 모드로, 픽셀 값이 색상 팔레트의 인덱스를 참조
PIL/Pillow Image 객체의 주요 method 및 속성
- show()
- 이미지를 기본 뷰어에서 보여준다.
- save(filename, format=None, **params)
- format은 이미지 포맷 지정
- resize((width, height), resample-0)
- rotate(angle, resample=0, expand=0)
- crop(box=None)
- 이미지의 일부를 잘라내 새 이미지 생성 box 는 (left, upper, right, lower) 튜플
- convert(mode=None, **params)
- 이미지 색상 모드 변경
- filter(filter)
- 블러 컨투어 등 다양한 필터 적용
- getpixel((x, y))
- 지정된 좌표에 있는 픽셀의 색상값 반환
- size
- 이미지의 크기를 (너비, 높이) 형태의 튜플로 반환
- format
- 이미지가 로드된 파일의 포멧(JPEG, PNG)를 나타냄
"""
image = Image.open(image_path)
image_mode = image.mode
if image_mode != 'RGB':
# np.asarray 함수는 주어진 객체를 numpy 배열로 변환
image = np.asarray(image)
print(image.shape)
# 지정된 경로의 파일을 삭제
os.remove(image_path)
try:
os.remove(bbox_path)
except FileNotFoundError:
pass
tfrecord 파일 만들기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
IMG_SIZE = 224
N_DATA = 3685
N_TRAIN = 3000
N_VAL = 685
# train/validation data 나누기
shuffle_list = list(range(N_DATA))
random.shuffle(shuffle_list)
train_idx_list = shuffle_list[:N_TRAIN]
val_idx_list = shuffle_list[N_TRAIN:]
# tfrecord writer 생성
tfr_dir = os.path.join(data_dir, 'tfrecord')
# 해당 경로에 디렉토리가 이미 존재하면 패스
os.makedir(tfr_dir, exist_ok = True)
tfr_train_dir = os.path.join(tfr_dir, 'loc_train.tfr')
tfr_val_dir = os.path.join(tfr_dir, 'loc_val.tfr')
"""
tf.io.TFRecordWriter 함수는 지정된 경로에 TFRecord파일을 생성하고 작성하기 위한 TFRecordWriter객체를 생성한다.
TFRecord는 TensorFlow에서 사용되는 바이너리 파일 형식으로, 효율적인 데이터 읽기/쓰기를 위해 설계되었으며, 이 형식은 대규모 데이터셋, 특히 이미지나 텍스트 데이터셋을 저장하고 효율적으로 읽기 위해 자주 사용된다.
writer_train/val 객체는 TFRecord파일에 데이터를 쓰기 위한 인테페이스를 제공한다.
이 객체를 사용하여 데이터를 TFRecord형식으로 직렬화하고 파일에 쓸 수 있다.
주로 writer_train/val.write(example) 메서드를 사용해 직룔화된 데이터를 파일에 쓰게된다.
"""
writer_train = tf.io.TFRecordWriter(tfr_train_dir)
writer_val = tf.io.TFRecordWriter(tfr_val_dir)
tfrecord 파일 작성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
def _bytes_feature(value):
"""
value가 Tensorflow의 EagerTensor인지 확인
EagerTensor인 경우 .numpy()를 사용하여 numpy배열로 변환
이는 BytesList가 EagerTensor에서 직접 문자열을 언패킹 하지 않기 때문
isinstance(1, int) = True
isinstance(1.2, int) = False
"""
if isinstance(value, type(tf.constant(0))):
value = value.numpy()
return tf.train.Feature(bytes_list = tf.train.BytesList(value=[value]))
"""
tf.train.Feature를 사용해 바이너리 데이터(예: 이미지 데이터)를 TFRecord파일에 저장하기
위해 변환하는 과정
- tf.train.BytesList(value=[value])
BytesList 타입의 프로토콜 버퍼를 생성.
프로토콜 버퍼는 구글이 개발한 데이터 직렬화 도구로, 복잡한 데이터 구조를 효율적으로 저장하고
전송할 수 있게 해준다.
ByteList 는 바이너리 데이터(예: 문자열, 이미지 등)를 나타내는데 사용된다.
여기서 value는 바이트 문자열이나 이미지 바이트 등을 나타낸다
value = [value] 는 value를 리스트 형태로 감짜준다.BytesList는 하나 이상의 값을
포함할 수 있으므로, 심지어 단일값일 경우에도 리스트 형태로 제공된다.
- tf.train.Feature
Feature는 Tensorflow에서 사용하는 또 다른 프로토콜 버퍼 타입.
Feature는 다양한 데이터 타입(BytesList, FloatList, Int64List 등)을 저장할수 있는
일반적인 컨테이너
여기서 tf.train.Feature(bytes_list = tf.train.BytesList(value=[value]))는
바이너리 데이터를 저장하기 위한 BytesList를 Feature로 감싸는 과정을 나타낸다.
"""
def _float_feature(value):
return tf.train.Feature(float_list = tf.train.FloatList(value=[value]))
def _int64_feature(value):
return tf.train.Feature(int64_list = tf.train.Int64List(value=[value]))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
for idx in val_idx_list:
bbox_file = bbox_files[idx]
bbox_path = os.path.join(bbox_dir, bbox_file)
tree = tf.parse(bbox_path)
width = float(tree.find('./size/width').text)
height = float(tree.find('./size/height').text)
xmin = float(tree.find('./object/bndbox/xmin').text)
ymin = float(tree.find('./object/bndbox/ymin').text)
xmax = float(tree.find('./object/bndbox/xmax').text)
ymax = float(tree.find('./object/bndbox/ymax').text)
xc = (xmin + xmax) / 2
yc = (ymin + ymax) / 2
x = xc / width # 이미지 크기에 비례하도록 정규화
y = yc / height
w = (xmax - xmin) / width # 이미지 크기에 비례하도록 너비 정규화
h = (ymax - ymin) / height
"""
간단한 예시
- 가정: 이미지의 크기가 100x100픽셀이고, 어떤 사각형(바운딩 박스)의 좌표가
`(xmin=30, ymin=40, xmax=60, ymax=80)`라고 합시다.
- 이 사각형의 중심점은 `(45, 60)`이 됩니다. (`(30+60)/2 = 45`, `(40+80)/2 = 60`)
- 이 중심점을 이미지 크기에 맞게 정규화하면 `(0.45, 0.60)`이 됩니다.
(`45/100 = 0.45`, `60/100 = 0.60`)
- 사각형의 너비와 높이는 각각 30픽셀(`60-30`)과 40픽셀(`80-40`)입니다.
- 이를 정규화하면 `(0.30, 0.40)`이 됩니다. (`30/100 = 0.30`, `40/100 = 0.40`)
즉 바운딩 박스를 정규화 한다는 것은 좌표를 확률로 만들어서 1000px든 100px든
상단 40% 하단 20% 같이 확률적으로 나타내기 위해 사용
"""
file_name = os.path.splitext(bbox_file)[0]
image_file = file_name + '.jpg'
image_path = os.path.join(image_dir, image_file)
image = Image.open(image_path)
image = image.resize((IMG_SIZE, IMG_SIZE))
bimage = image.tobytes()
"""
tobytes 메서드는 이미지를 바이트 형식(이진화)으로 변환한다.
즉 이미지 데이터를 연속된 바이트 시퀀스로 변환
바이트 형식 데이터는 파일로 저장하거나 네트워크를 통해 전송하기 적합한 형태
이미지는 원래 픽셀의 배열이나 행렬 구조로 되어 있지만 바이트 변환 후에는 이러한 구조 없이 단순한
바이트 스트림으로 존재
ex)
- 비주얼 예시: 파일을 열어보면, `01010100 01101000 01101001 01110011`와 같은 2진수 형태가
아닌, `54 68 69 73`와 같은 16진수 형태로 보임
- 실제 데이터: 예를 들어, RGB 이미지에서 한 픽셀이 빨간색(`R=255, G=0, B=0`)인 경우,
이 픽셀은 `FF 00 00`의 3바이트로 표현
"""
if file_name[0].islower():
cls_num = 0 # 개
else:
cls_num = 1 # 고양이
example = tf.train.Example(features = tf.train.Features(feature = {
'image': _bytes_feature(bimage),
'cls_num': _int64_feature(cls_num),
'x': _float_feature(x),
'y': _float_feature(y),
'w': _float_feature(w),
'h': _float_feature(h)
}))
"""
- tf.train.Example 은 Tensroflow에서 제공하는 데이터 타입으로, 훈련 데이터를 표현하기 위한
일반적인 포멧. Example은 key-value 쌍의 딕셔너리 형태로 데이터를 저장
- features = tf.train.Features(feature = {...})
tf.train.Features는 하나 이상의 key-value 쌍('feature')를 포함
각 키는 문자열이고 값은 tf.train.Feature 객체
_bytes_feature, _int64_feature, _float_feature 함수들은 앞서 정의된 헬퍼 함수들로
각각 바이트 데이터, 정수 데이터, 부동소수점 데이터를 tf.train.Feature형식으로 변환
"""
writer_train.write(example.SerializeToString())
"""
- example.SerializeToString():
SerializeToString 메서드는 Example 객체를 문자열 형태의 직렬화된 데이터로 변환
"""
writer_train.close()
Image Localization 모델 작성 및 학습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
N_EPOCHS = 40
N_BATCH = 40
N_VAL_BATCH = 127
learning_rate = 0.0001
def _parse_function(tfrecord_serialized):
features = {'image':tf.io.FixedLenFeature([], tf.string),
'cls_num': tf.io.FixedLenFeature([], tf.int64),
'x': tf.io.FixedLenFeature([], tf.float32),
'y': tf.io.FixedLenFeature([], tf.float32),
'w': tf.io.FixedLenFeature([], tf.float32),
'h': tf.io.FixedLenFeature([], tf.float32),
}
parsed_features = tf.io.parse_single_example(tfrecord_serialized, features)
image = tf.io.decode_raw(parsed_features['image'], tf.uint8
"""
`parsed_features['image']`에 저장된 바이트 형식의 데이터를 `uint8` 형식으로 디코딩
여기서 `parsed_features['image']`는 TFRecord에서 추출된 이미지 데이터를 바이트 형식으로
포함하고 있으며, 이를 실제 이미지 데이터로 변환하기 위해 `tf.io.decode_raw` 함수를 사용
"""
image = tf.reshape(image, [IMG_SIZE, IMG_SIZE, 3])
"""
디코딩된 이미지 데이터를 원하는 형태로 재구성
여기서 `[IMG_SIZE, IMG_SIZE, 3]`은 이미지의 높이, 너비,
그리고 채널 수(여기서는 3채널, 일반적으로 RGB 이미지를 의미)를 나타낸다.
"""
image = tf.cast(image, tf.float32) / 255.
"""
이미지 데이터를 `float32` 형식으로 변환하고 0과 1 사이의 값으로 정규화.
일반적으로 이미지 데이터는 0부터 255까지의 정수 값을 가지므로, 이를 255로 나누어 0과 1 사이의
부동소수점 값으로 변환
"""
x = tf.cast(parsed_features['x'], tf.float32)
y = tf.cast(parsed_features['y'], tf.float32)
w = tf.cast(parsed_features['w'], tf.float32)
h = tf.cast(parsed_features['h'], tf.float32)
gt = tf.stack([x, y, w, h], -1) # [0.381 0.5015015 0.534 0.8408408]
# x, y, w, h가 현재는 스칼라 이므로 -1이 있으나 없으나 똑같은 결과 나옴
return image, gt
1
2
3
4
5
6
7
8
9
10
11
12
13
train_dataset = tf.data.TFRecordDataset(tfr_train_dir)
train_dataset = train_dataset.map(_parse_function,
num_parallel_calls =
tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(
buffer_size = N_TRAIN).prefetch(
tf.data.AUTOTUNE).batch(N_BATCH)
val_dataset = tf.data.TFRecordDataset(tfr_val_dir)
val_dataset = val_dataset.map(_parse_function,
num_parallel_calls =
tf.data.AUTOTUNE).batch(N_BATCH)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
img, gt = next(iter(train_dataset.take(1).unbatch()))
for img, gt in train_dataset.take(1):
print(gt.shape) # (40 ,4) (batch, (x, y, w, h))
print(gt[:, 0].shape) # (40, ) (40개의 x)
print(gt[0].shape) # (0번째 gt의 x, y, w, h)
for image, gt in val_dataset.take(1):
'''
그림을 그리기 위해 bbox의 왼쪽 위 꼭지점 좌표를 계산하고,
xmin, ymin, w, h 각각을 image size에 맞게 scaling
'''
x = gt[:, 0]
y = gt[:, 1]
w = gt[:, 2]
h = gt[:, 3]
"""
중심 x 좌표 (`x[0].numpy()`)에서 너비의 절반 (`w[0].numpy() / 2`)을 빼면
중심에서 왼쪽으로 너비의 절반만큼 이동하여 사각형의 왼쪽 가장자리에 도달
"""
xmin = x[0].numpy() - w[0].numpy() / 2.
ymin = y[0].numpy() - h[0].numpy() / 2.
rect_x = int(xmin * IMG_SIZE)
rect_y = int(ymin * IMG_SIZE)
rect_w = int(w[0].numpy() * IMG_SIZE)
rect_h = int(h[0].numpy() * IMG_SIZE)
rect = Rectangle((rect_x, rect_y), rect_w, rect_h, fill = False,
color = 'red')
plt.axes().add_patch(rect)
plt.imshow(image[0])
plt.show()
모델 학습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
def create_model():
model = keras.Sequential()
model.add(keras.layers.Cov2D(filters = 32,
kernel_size = 3,
activation = 'relu',
padding = 'same',
input_shape = (IMG_SIZE, IMG_SIZE, 3)))
model.add(keras.layers.MaxPool2D(padding = 'same'))
model.add(keras.layers.Conv2D(filters = 64,
kernel_size = 3,
activation = 'relu',
padding = 'same'))
model.add(keras.layers.MaxPool2D(padding = 'same'))
model.add(keras.layers.Conv2D(filters = 128,
kernel_size = 3,
activation = 'relu',
padding = 'same'))
model.add(keras.layers.MaxPool2D(padding = 'same'))
model.add(keras.layers.Conv2D(filters = 256,
kernel_size = 3,
activation = 'relu',
padding = 'same'))
model.add(keras.layers.MaxPool2D(padding = 'same'))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(units = 1024, activation = 'relu'))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(units = 4, activation = 'sigmoid'))
return model
model = create_model()
model.summary()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def loss_fn(y_true, y_pred):
return keras.losses.MeanSquaredError()(y_true, y_pred)
lr_schedult = keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate = learning_rate,
decay_steps = N_TRAIN / N_BATCH * 10, # 10에폭 마다
decay_rate = 0.5,
staircase = True)
model.compile(keras.optimizers.RMSprop(lr_schedule, momentum = 0.9),
loss = loss_fn)
model.fit(train_dataset,
validation_data = val_dataset,
epochs = N_EPOCHS)
학습 결과 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
"""
총 685장 을 137장씩 1배치로 묶어서 총 5 배치가 나왔기 때문에 for문은 5번 반복
"""
idx = 0
for val_data, val_gt in val_dataset:
x = val_gt[:, 0]
y = val_gt[:, 1]
h = val_gt[:, 2]
w = val_gt[:, 3]
xmin = x[idx].numpy() - w[idx].numpy() / 2.
ymin = y[idx].numpy() - h[idx].numpy() / 2.
rect_x = int(xmin * IMG_SIZE)
rect_y = int(ymin * IMG_SIZE)
rect_w = int(w[idx].numpy() * IMG_SIZE)
rect_h = int(h[idx].numpy() * IMG_SIZE)
rect = Rectangle((rect_x, rect_y), rect_w, rect_h,
fill = False, color = 'red')
plt.axes().add_patch(rect)
prediction = model.predict(val_data)
pred_x = prediction[:, 0]
pred_y = prediction[:, 1]
pred_w = prediction[:, 2]
pred_h = prediction[:, 3]
pred_xmin = pred_x[idx] - pred_w[idx] / 2.
pred_ymin = pred_y[idx] - pred_h[idx] / 2.
pred_rect_x = int(pred_xmin * IMG_SIZE)
pred_rect_y = int(pred_ymin * IMG_SIZE)
pred_rect_w = int(pred_w[idx] * IMG_SIZE)
pred_rect_h = int(pred_h[idx] * IMG_SIZE)
pred_rect = Rectangle((pred_rect_x, pred_rect_y), pred_rect_w, pred_rect_h,
fill = False, color = 'blue')
plt.axes().add_patch(pred_rect)
plt.imshow(val_data[idx])
plt.show()
IOU 계산
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
avg_iou = 0
for val_data, val_gt in val_dataset:
x = val_gt[:, 0]
y = val_gt[:, 1]
w = val_gt[:, 2]
h = val_gt[:, 3]
prediction = model.predict(val_data)
pred_x = prediction[:, 0]
pred_y = prediction[:, 1]
pred_w = prediction[:, 2]
pred_h = prediction[:, 3]
for idx in range(N_VAL_BATCH): # 137
xmin = int((x[idx].numpy() - w[idx].numpy() / 2.) * IMG_SIZE)
ymin = int((y[idx].numpy() - h[idx].numpy() / 2.) * IMG_SIZE)
xmax = int((x[idx].numpy() + w[idx].numpy() / 2.) * IMG_SIZE)
ymax = int((y[idx].numpy() + h[idx].numpy() / 2.) * IMG_SIZE)
pred_xmin = int((pred_x[idx].numpy() - pred_w[idx].numpy() / 2.)
* IMG_SIZE)
pred_ymin = int((pred_y[idx].numpy() - pred_h[idx].numpy() / 2.)
* IMG_SIZE)
pred_xmax = int((pred_x[idx].numpy() + pred_w[idx].numpy() / 2.)
* IMG_SIZE)
pred_ymax = int((pred_y[idx].numpy() + pred_h[idx].numpy() / 2.)
* IMG_SIZE)
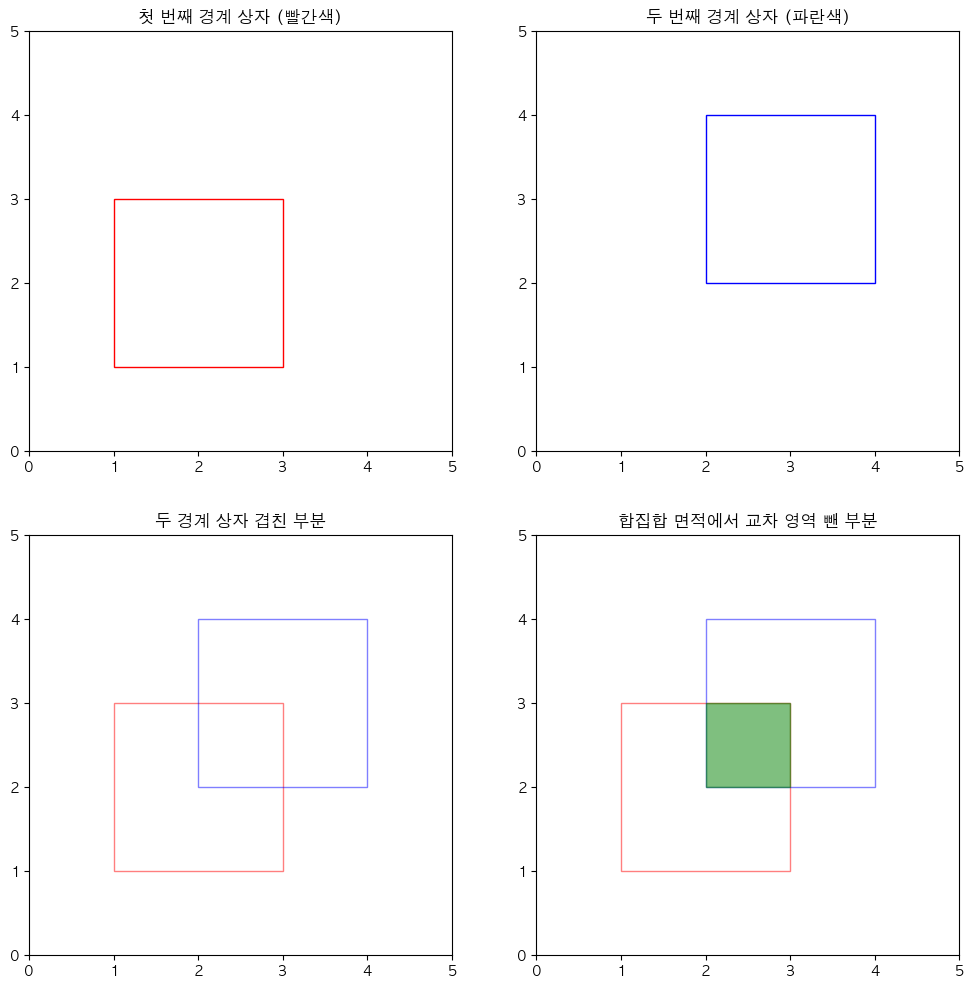
if xmin > pred_xmax or xmax < pred_xmin:
continue
if ymin > pred_ymax or ymax < pred_ymin:
continue
"""
경계 상자 간 겹침 확인
`if xmin > pred_xmax or xmax < pred_xmin:`
이 조건문은 첫 번째 경계 상자와 두 번째 경계 상자가 x축 방향으로 겹치지 않는 경우를 체크.
첫 번째 상자의 최소 x 좌표(xmin)가 두 번째 상자의 최대 x 좌표(pred_xmax)보다 크거나,
첫 번째 상자의 최대 x 좌표(xmax)가 두 번째 상자의 최소 x 좌표(pred_xmin)보다 작으면,
두 상자는 겹치지 않는다.
`if ymin > pred_ymax or ymax < pred_ymin:`:
이 조건문은 y축 방향으로 두 상자가 겹치지 않는 경우를 체크.
"""
# 겹치는 부분의 너비 제일 큰 애들 중 작은거 - 제일 작은 애들 중 큰거 = 겹치는 부분
w_inter = np.min((xmax, pred_xmax)) - np.max((xmin, pred_xmin))
# 겹치는 부분의 길이
h_inter = np.min((ymax, pred_ymax)) - np.max((ymin, pred_ymin))
"""
교차 영역 계산
`w_inter = np.min((xmax, pred_xmax)) - np.max((xmin, pred_xmin))`:
교차 영역의 너비를 계산.
두 상자의 x 좌표 중 최대값을 찾아서 교차 영역의 최소 x 좌표를 결정하고,
두 상자의 x 좌표 중 최소값을 찾아서 교차 영역의 최대 x 좌표를 결정.
`h_inter = np.min((ymax, pred_ymax)) - np.max((ymin, pred_ymin))`:
교차 영역의 높이를 계산. 위의 너비 계산과 유사한 방법으로 y 좌표를 사용.
"""
inter = w_inter * h_inter
union = (w[idx].numpy() * h[idx].numpy() + pred_w[idx] * pred_h[idx])
- inter
"""
교차 영역과 합집합 계산
`inter = w_inter * h_inter`: 계산된 교차 영역의 너비와 높이를 곱하여
교차 영역의 면적을 구한다.
`union = (w[idx].numpy() * h[idx].numpy() + pred_w[idx] * pred_h[idx])
- inter`:
합집합의 면적을 계산.
이는 두 상자 각각의 면적을 더한 값에서 교차 영역의 면적을 빼는 것으로 계산.
"""
iou = inter / union
avg_iou += iou / N_VAL
"""
IoU 계산 및 평균 IoU 업데이트
`iou = inter / union`: 교차 영역을 합집합으로 나누어 IoU를 계산
`avg_iou += iou / N_VAL`: 계산된 IoU 값을 전체 검증 데이터셋의 샘플 수(`N_VAL`)
로 나누어 평균 IoU를 갱신
"""
print(avg_iou)
1
2
3
4
5
if xmin > pred_xmax or xmax < pred_xmin:
continue
if ymin > pred_ymax or ymax < pred_ymin:
continue

1
union = (w[idx].numpy() * h[idx].numpy() + pred_w[idx] * pred_h[idx]) - inter
1
avg_iou += iou / N_VAL
\(\frac{a}{n} + \frac{b}{n} + \frac{c}{n} = \frac{a + b + c}{n}\)
이는 평균 IoU 계산에도 적용됩니다. 예를 들어, 각 샘플의 IoU 값을 더한 다음에 총 샘플 수로 나누는 것은 각 IoU 값을 개별적으로 샘플 수로 나누고 그 결과를 더하는 것과 동일
따라서, 이전 예시에서 avg_iou += iou / N_VAL를 사용하는 것은 모든 IoU 값을 더한 후 N_VAL로 나누는 것과 같은 결과를 제공
\(\text{평균 IoU} = \frac{0.9 + 0.8 + 0.7 + 0.6 + 0.5}{5}\) 이 방식은 코드에서 avg_iou를 각 샘플의 iou / N_VAL로 점진적으로 증가시키는 것과 동일한 결과를 제공
MobileNetV2 Localization 학습 (Multi-task Learning)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def _parse_function(tfrecord_serialized):
feature = {'image': tf.io.FixedLenFeature([], tf.string),
'cls_num': tf.io.FixedLenFeature([], tf.int64),
'x': tf.io.FixedLenFeature([], tf.float32),
'y': tf.io.FixedLenFeature([], tf.float32),
'w': tf.io.FixedLenFeature([], tf.float32),
'h': tf.io.FixedLenFeature([], tf.float32)
}
parsed_features = tf.io.parse_single_example(tfrecord_serialized, features)
image = tf.io.decode_raw(parsed_features['image'], tf.uint8)
image = tf.reshape(image, [IMG_SIZE, IMG_SIZE, 3])
image = tf.cast(image, tf.float32) / 255.
cls_num = tf.cast(parsed_features['cls_num'], tf.float32)
x = tf.cast(parsed_features['x'], tf.float32)
y = tf.cast(parsed_features['y'], tf.float32)
w = tf.cast(parsed_features['w'], tf.float32)
h = tf.cast(parsed_features['h'], tf.float32)
gt = tf.stack([cls_num, x, y, w, h], -1)
return image, gt
1
2
3
4
5
6
7
8
9
10
train_dataset = tf.data.TFRecordDataset(tfr_train_dir)
train_dataset = train_dataset.map(_parse_function,
num_parallel_calls = tf.data.AUTOTUE)
train_dataset = train_dataset.shuffle(buffer_size =
N_TRAIN).prefetch(tf.data.AUTOTUNE).batch(N_BATCH)
val_dataset = tf.data.TFRecordDataset(tfr_val_dir)
val_dataset = val_dataset.map(_parse_function,
num_parallel_calls = tf.data.AUTOTUNE).batch(N_BATCH)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
mobilenetv2 = MobileNetV2(weights = 'imagenet',
include_top = False,
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
def create_multitask_model():
gap = GlobalAveragePooling2D()(mobilnetv2.output)
dense_b1_1 = Dense(units = 256)(gap)
bn_b1_2 = BatchNormalization()(dense_b1_1)
relu_b1_3 = ReLU()(bn_b1_2)
dense_b1_4 = Dnese(units = 64)(relu_b1_3)
bn_b1_5 = BatchNormalization()(dense_b1_4)
relu_b1_6 = ReLU()(bn_b1_5)
output1 = Dense(units = 2, activation = 'softmax')(relu_b1_6)
dense_b2_1 = Dense(units = 256)(gap)
bn_b2_2 = BatchNormalization()(dense_b2_1)
relu_b2_3 = ReLU()(bn_b2_2)
dense_b2_4 = Dense(units = 64)(relu_b2_3)
bn_b2_5 = BatchNormalization()(dense_b2_4)
relu_b2_6 = ReLU()(bn_b2_5)
output2 = Dense(units = 4, activation = 'sigmoid')(relu_b2_6)
concat = Concatenate()([output1, output2])
return keras.Model(inputs = mobilenetv2.input, outputs = concat)
model = create_multitask_model()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
def loss_fn(y_true, y_pred):
cls_labels = tf.cast(y_true[:, :1], tf.int64)
loc_labels = y_true[:, 1:]
cls_preds = y_pred[:, :2]
loc_preds = y_pred[:, 2:]
# cls 원핫 인코딩 안했기 때문에 SparseCC 사용. 출력은 [0.3, 0.7] 이런식
cls_loss = keras.losses.SparseCategoricalCrossentropy()(cls_labels,cls_preds)
loc_loss = keras.losses.MeanSquaredError()(loc_labels, loc_preds)
return cls_loss + 5 * loc_loss
"""
이 코드에서 `+ 5`는 위치(location) 손실(`loc_loss`)에 가중치를 부여하기 위해 사용.
`cls_loss + 5 * loc_loss`는 클래스 분류 손실(`cls_loss`)과 위치 손실(`loc_loss`)을
합산하여 최종 손실을 계산하는데, 여기서 위치 손실에 5배의 가중치를 주는 것
가중치를 조정하는 이유
1. 손실 간 균형 조정: 모델이 두 가지 다른 종류의 작업(여기서는 클래스 분류와 위치 예측)을 동시에
수행할 때, 각 작업의 손실이 서로 다른 크기와 스케일을 가질 수 있다.
가중치를 조정하여 두 손실 간의 균형을 맞추는 것이 중요.
2. 특정 작업에 중점 두기: 경우에 따라 한 종류의 작업이 다른 작업보다 더 중요할 수 있다.
예를 들어, 위치 예측의 정확도가 클래스 분류보다 더 중요하다고 판단될 경우,
위치 손실에 더 큰 가중치를 부여할 수 있다.
3. 학습 안정성 향상: 가중치 조정은 모델의 학습 안정성과 성능을 향상시키는 데 도움이 될 수 있다.
손실 함수의 가중치를 조절함으로써, 모델이 두 작업을 더 균형 있게 학습하도록 유도할 수 있다.
이 코드에서 `5 * loc_loss`는 위치 손실이 클래스 분류 손실보다 상대적으로 더 중요하거나
더 큰 가중치를 필요로 한다는 것을 나타낸다.
"""
1
2
3
4
5
6
7
8
9
10
11
lr_schedule = keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate = learning_rate,
decay_steps = N_TRAIN / N_BATCH * 10,
decay_rate = 0.5,
staircase = True)
model.compile(keras.optimizers.RMSprop(lr_schedule, momentum = 0.9),
loss = loss_fn)
model.fit(train_dataset, epochs = N_EPOCHS, validation_data = val_dataset)
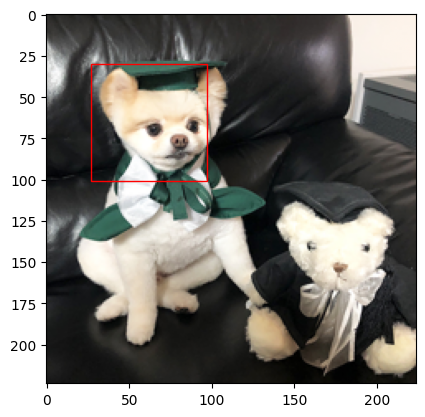
새로운 image로 test
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
image = Image.open('~/.test.jpg')
image = image.resize((IMG_SIZE, IMG_SIZE))
image = np.array(image)
image = image / 255.
image = np.reshape(image, (1, 224, 224, 3))
pred = model.predict(image)
pred_x = pred[0, 2]
pred_y = pred[0, 3]
pred_w = pred[0, 4]
pred_h = pred[0, 5]
pred_xmin = pred_x - pred_w / 2.
pred_ymin = pred_y - pred_h / 2.
pred_rect_x = int(pred_xmin * IMG_SIZE)
pred_rect_y = int(pred_ymin * IMG_SIZE)
pred_rect_w = int(pred_w * ING_SIZE)
pred_rect_h = int(pred_h * ING_SIZE)
pred_rect = Rectangle((pred_rect_x, pred_rect_y), pred_rect_w, pred_rect_h,
fill = False, color = 'red')
plt.axes().add_patch(pred_rect)
plt.imshow(image[0])
plt.show()
This post is licensed under CC BY 4.0 by the author.