4. Accelerating For Loops.
CUDA Thread Hierarchy

1
2
3
4
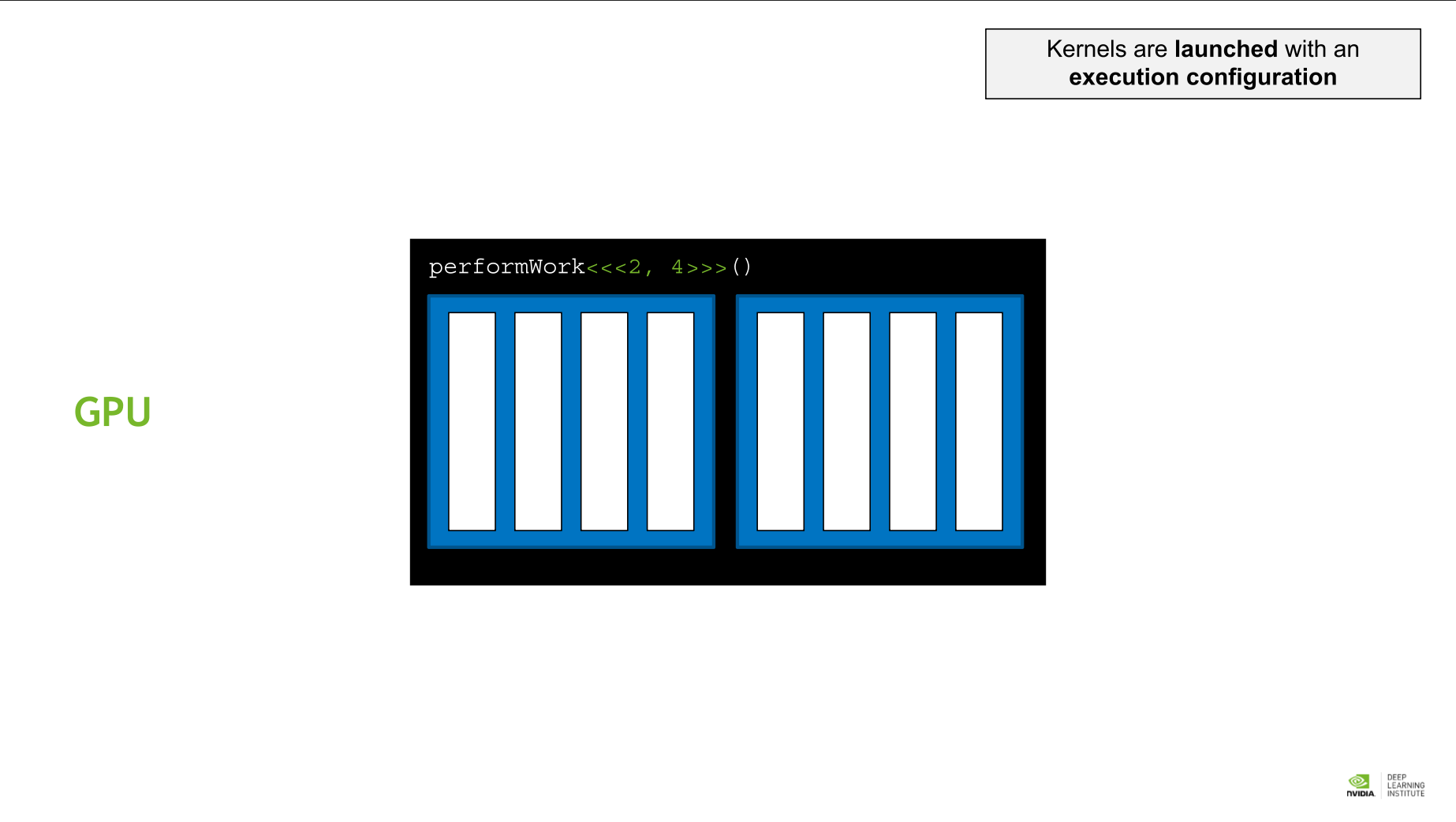
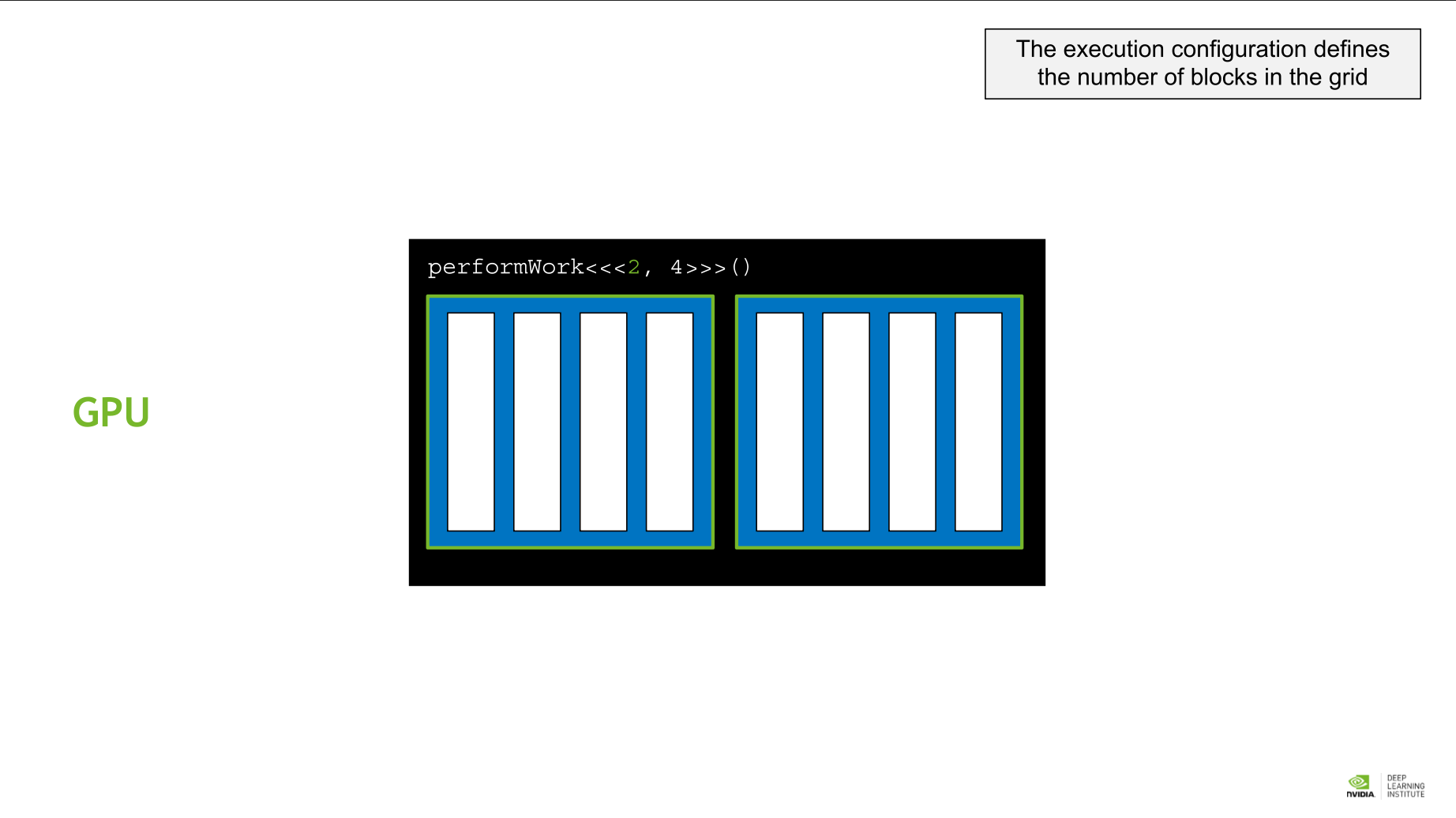
- kernel: GPU function을 부르는 용어. kernel은 execution configuration에 따라 실행된다.
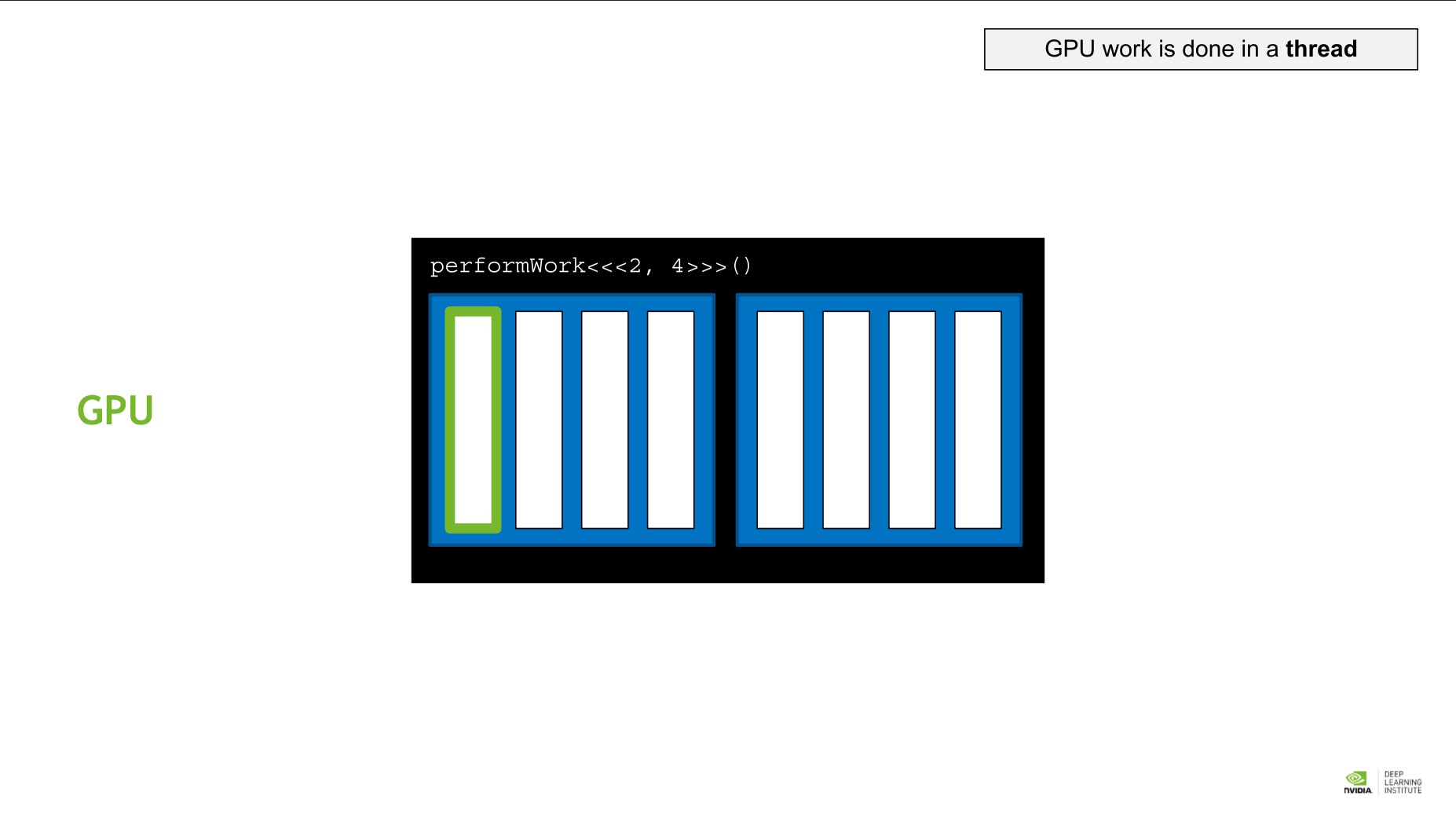
- thread: GPU 작업의 기본 단위. 여러 thread가 병렬적으로 작동한다.
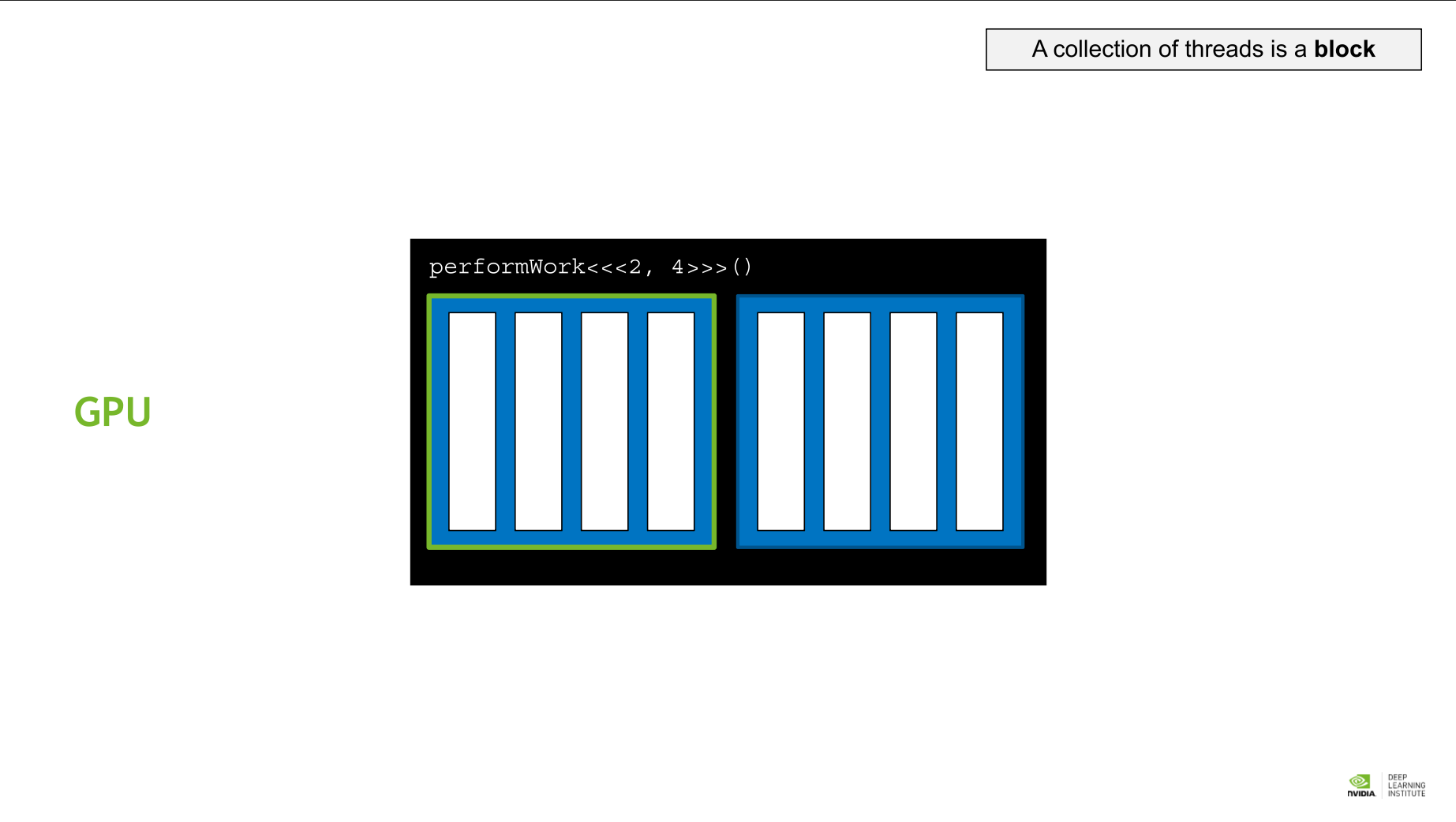
- block: thread의 모임을 block이라 한다.
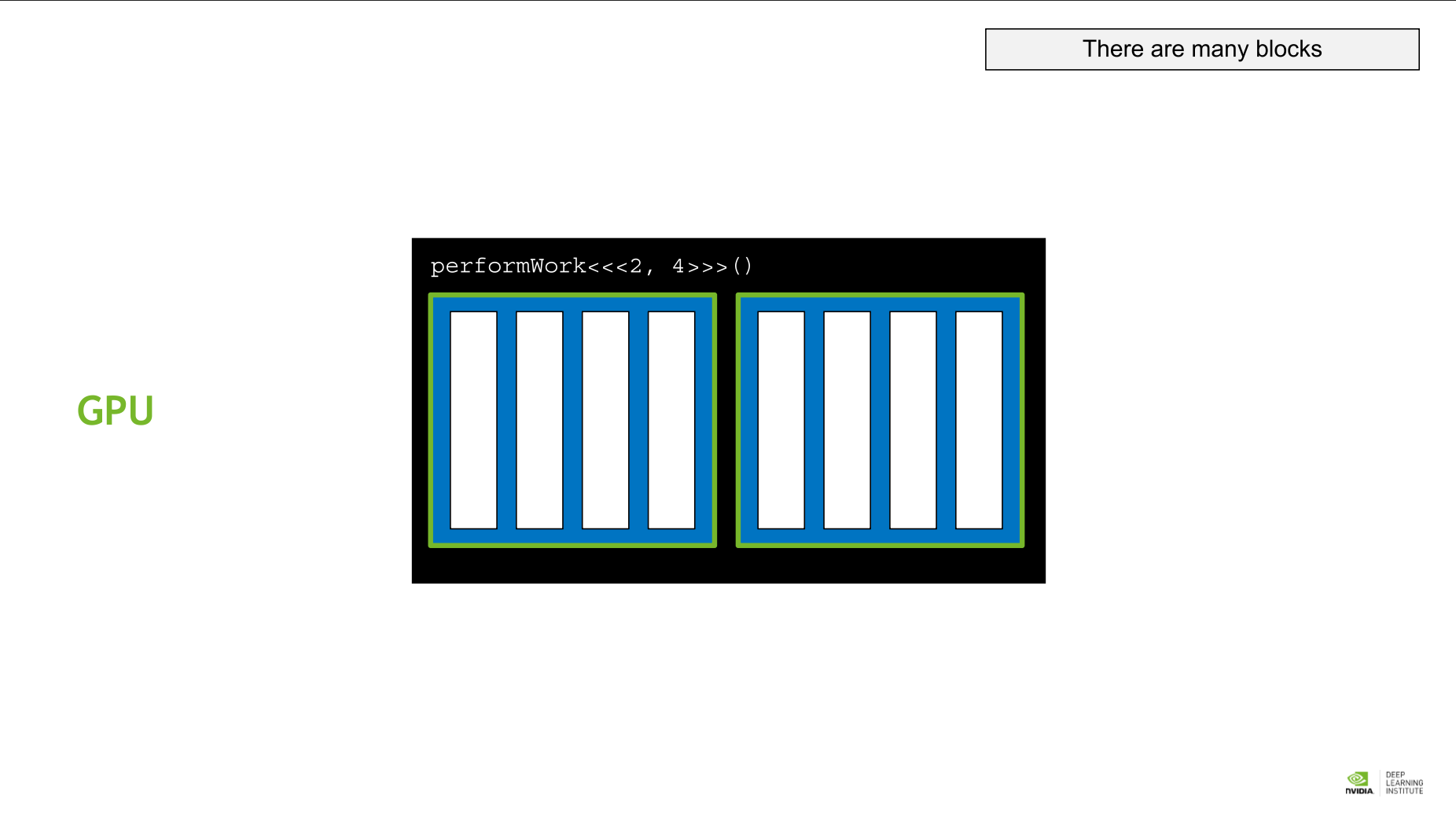
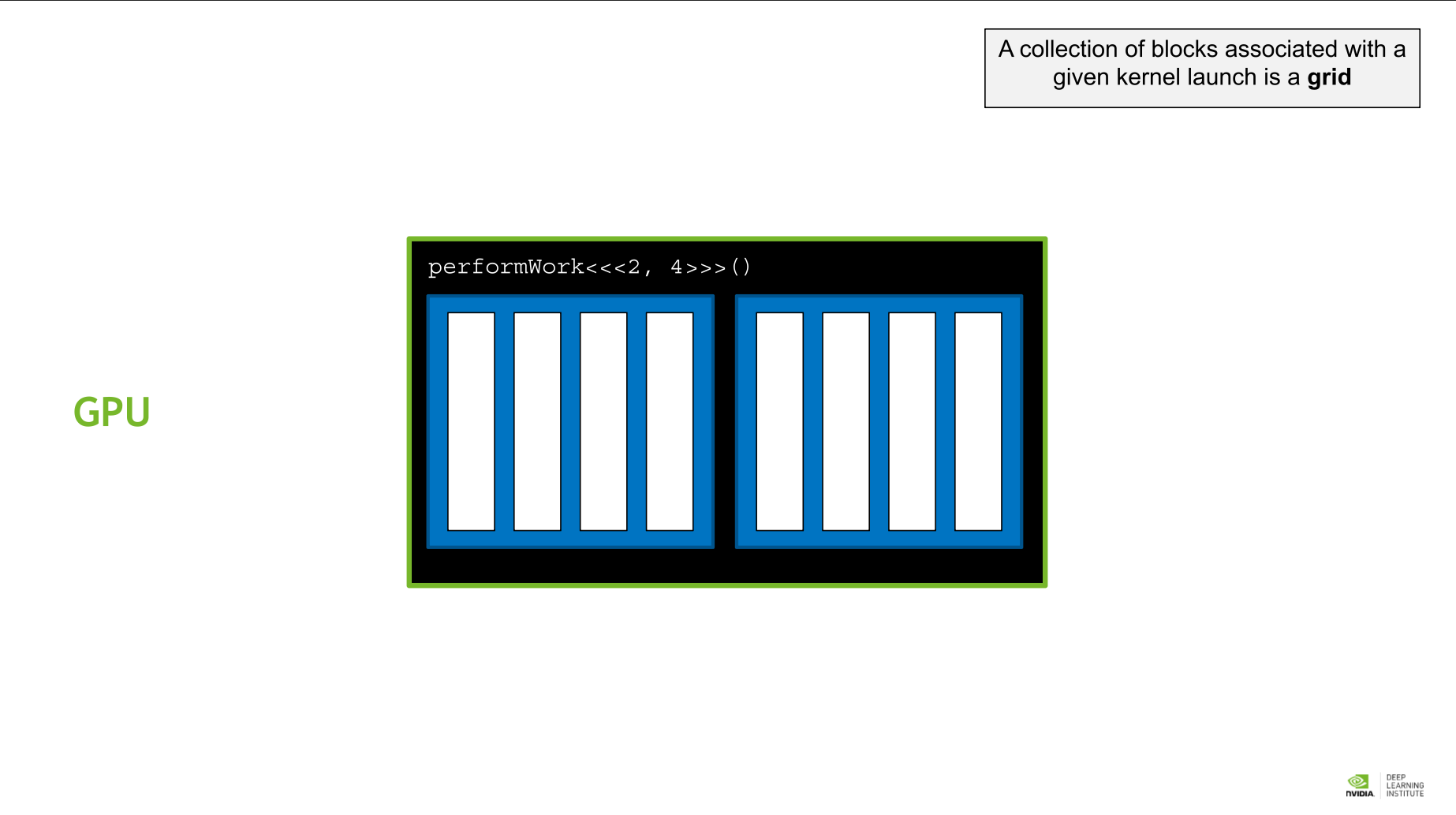
- grid: 주어진 kernel의 execution configuration에서 block들의 모임, 즉 전체를 그리드라 부른다.
그리드 > 블록 > 쓰레드
CUDA-Provided Thread Hierarchy Variables
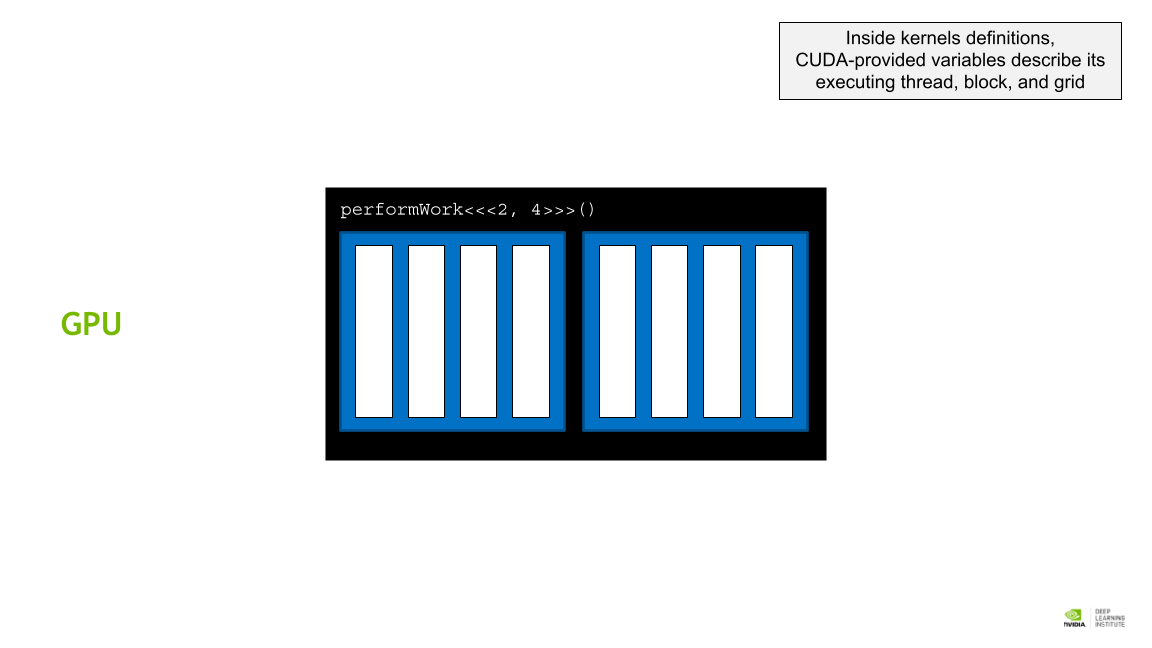 커널 정의 내에서 CUDA 제공 변수는 실행 스레드, 블록 및 그리드를 설명한다.
커널 정의 내에서 CUDA 제공 변수는 실행 스레드, 블록 및 그리드를 설명한다.
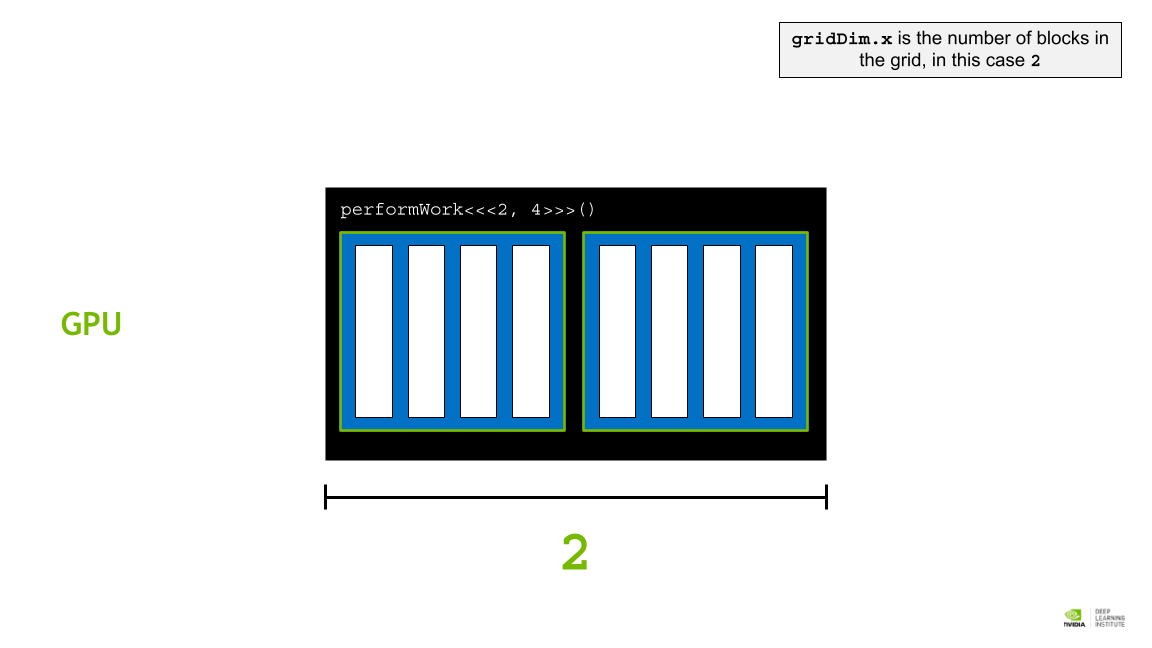 gridDim.x 는 그리드의 블록 수이며, 이 경우는 2이다.
gridDim.x 는 그리드의 블록 수이며, 이 경우는 2이다.
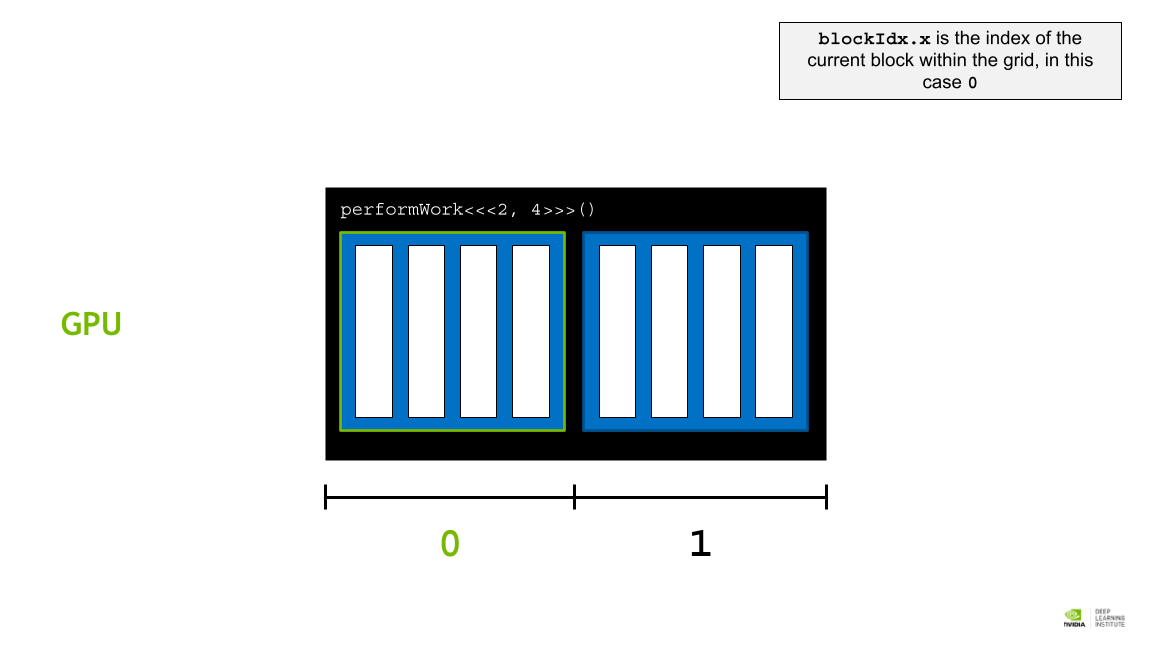 blockIdx.x 는 그리드 내의 현재 블록의 인덱스이며, 이 경우 0이다.
blockIdx.x 는 그리드 내의 현재 블록의 인덱스이며, 이 경우 0이다.
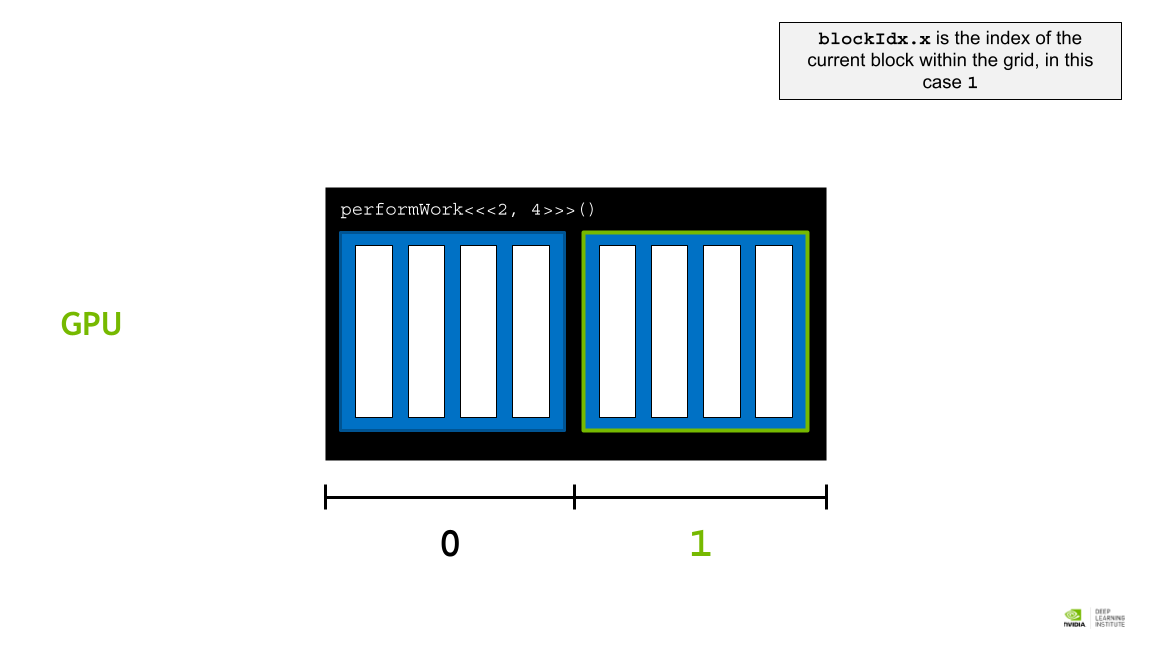 blockIdx.x 는 그리드 내의 현재 블록의 인덱스이며, 이 경우 1이다.
blockIdx.x 는 그리드 내의 현재 블록의 인덱스이며, 이 경우 1이다.
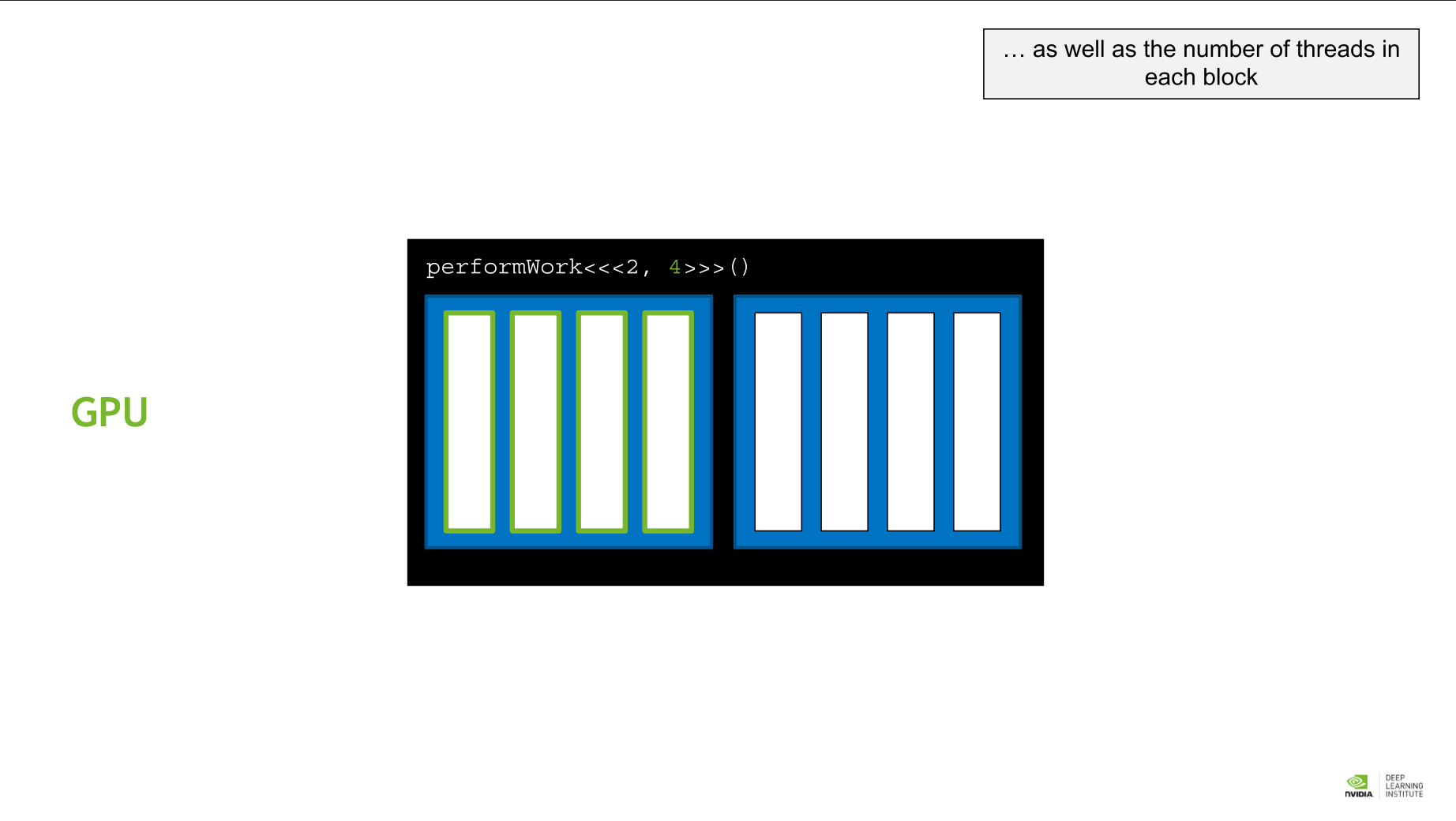
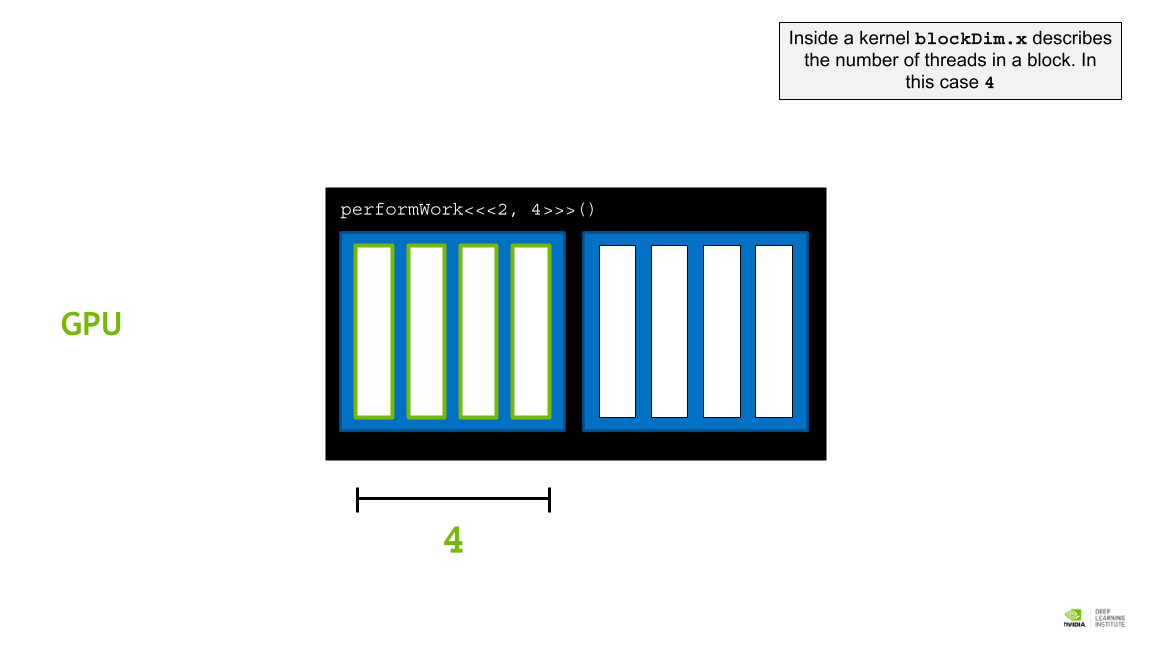 Kernel blockDim.x는 블록 내의 스레드 수를 나타낸다. 이 경우는 4이다.
Kernel blockDim.x는 블록 내의 스레드 수를 나타낸다. 이 경우는 4이다.
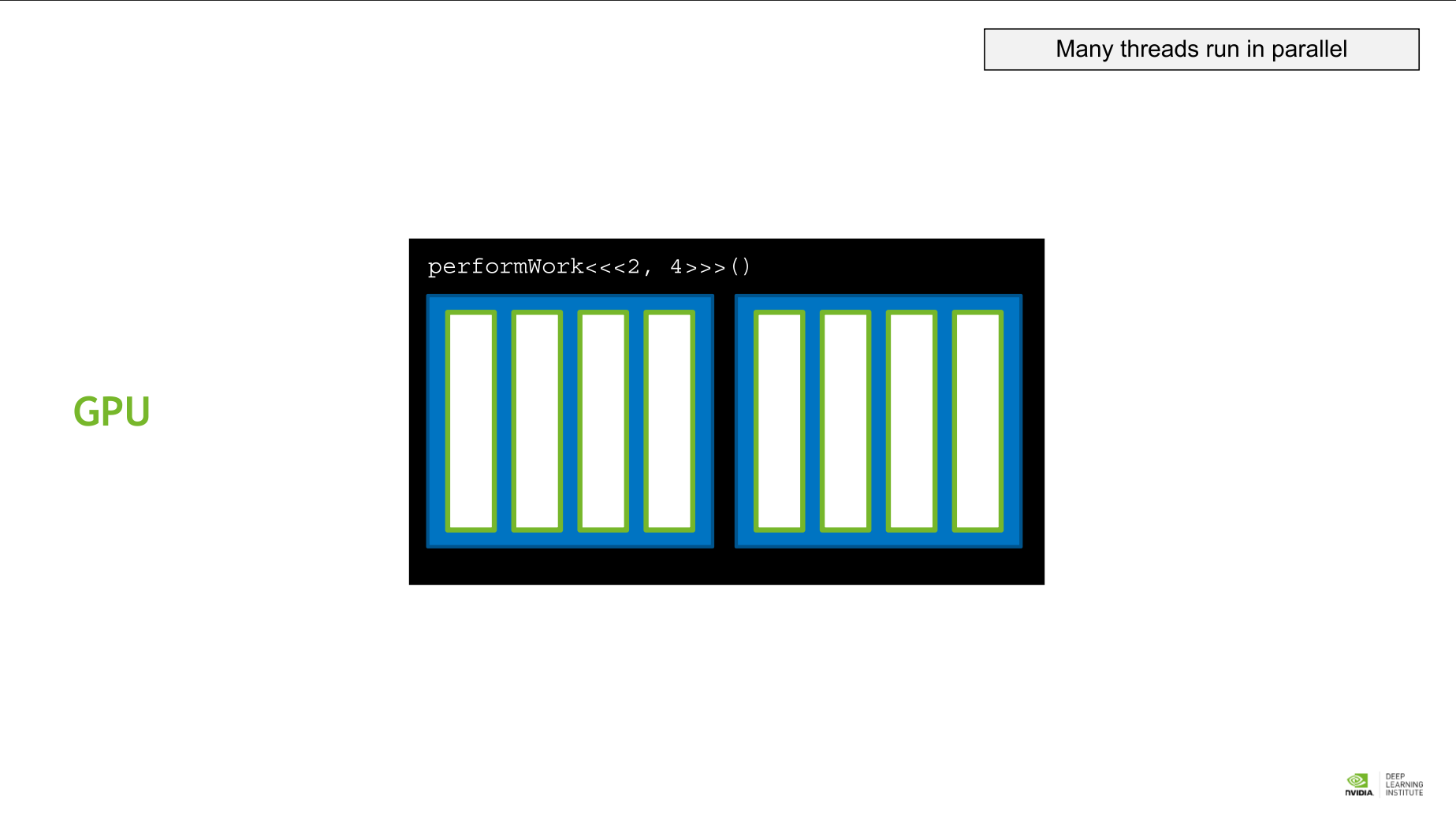
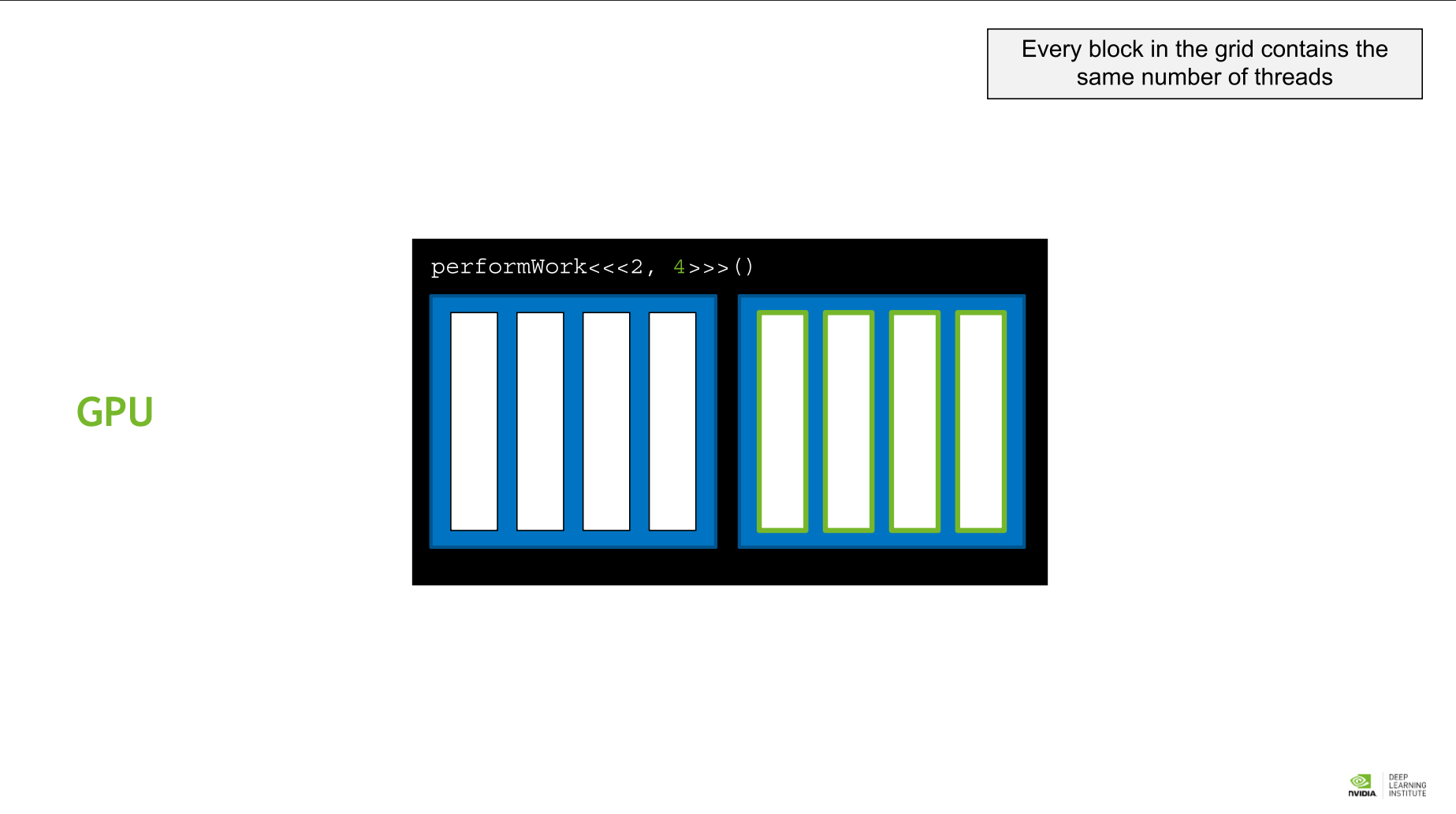
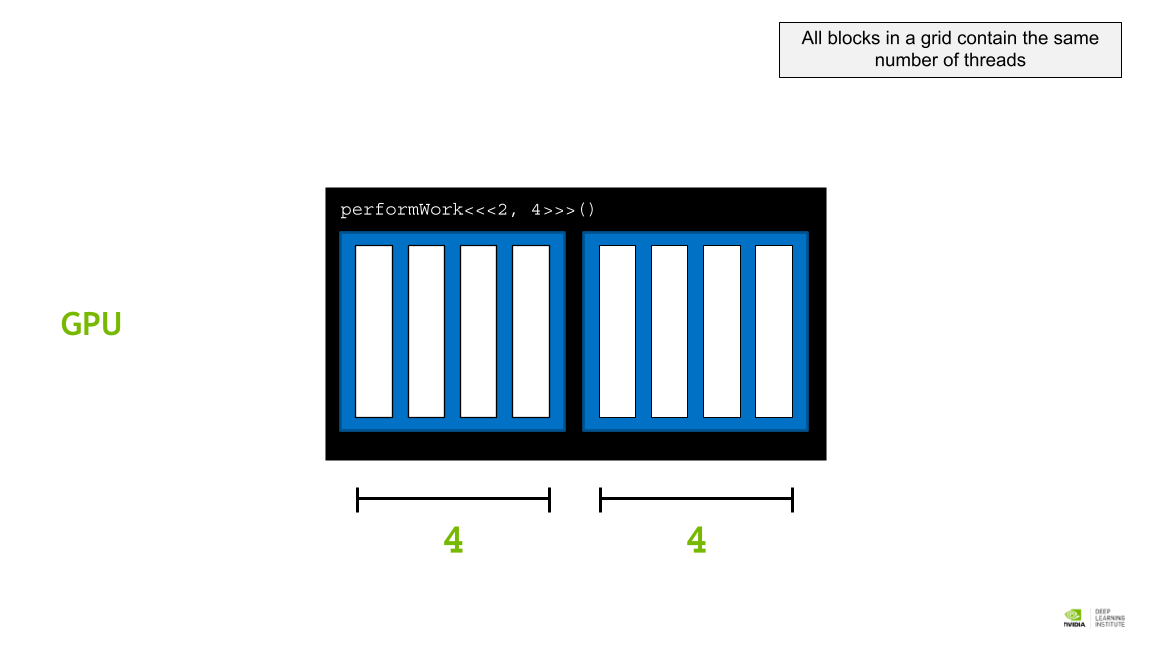 그리드의 모든 블록에 동일한 수의 스레드가 포함되어 있다.
그리드의 모든 블록에 동일한 수의 스레드가 포함되어 있다.
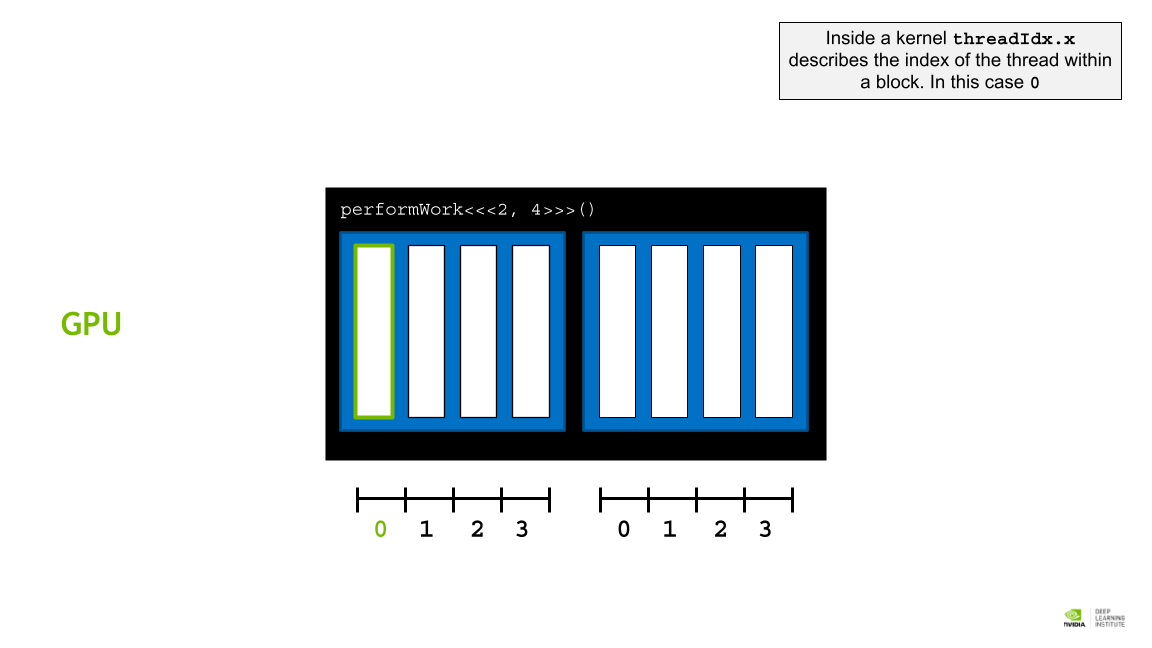 커널 내부의 threadIdx.x는 블록 내 스레드의 인덱스를 설명한다. 이 경우 0이다.
커널 내부의 threadIdx.x는 블록 내 스레드의 인덱스를 설명한다. 이 경우 0이다.
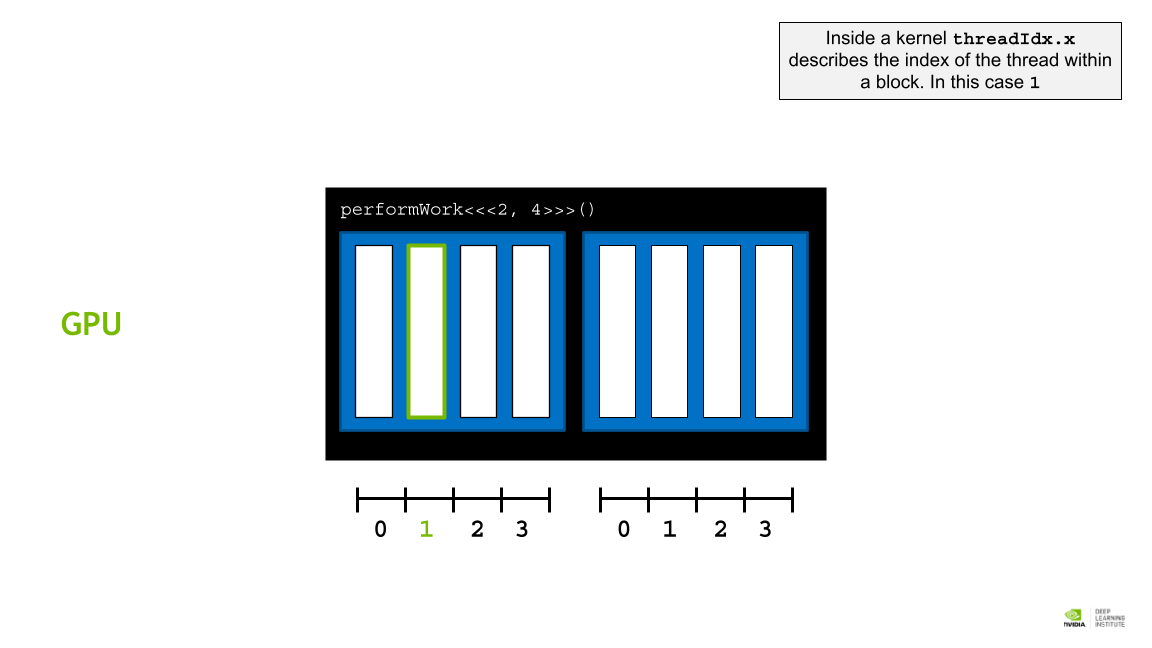
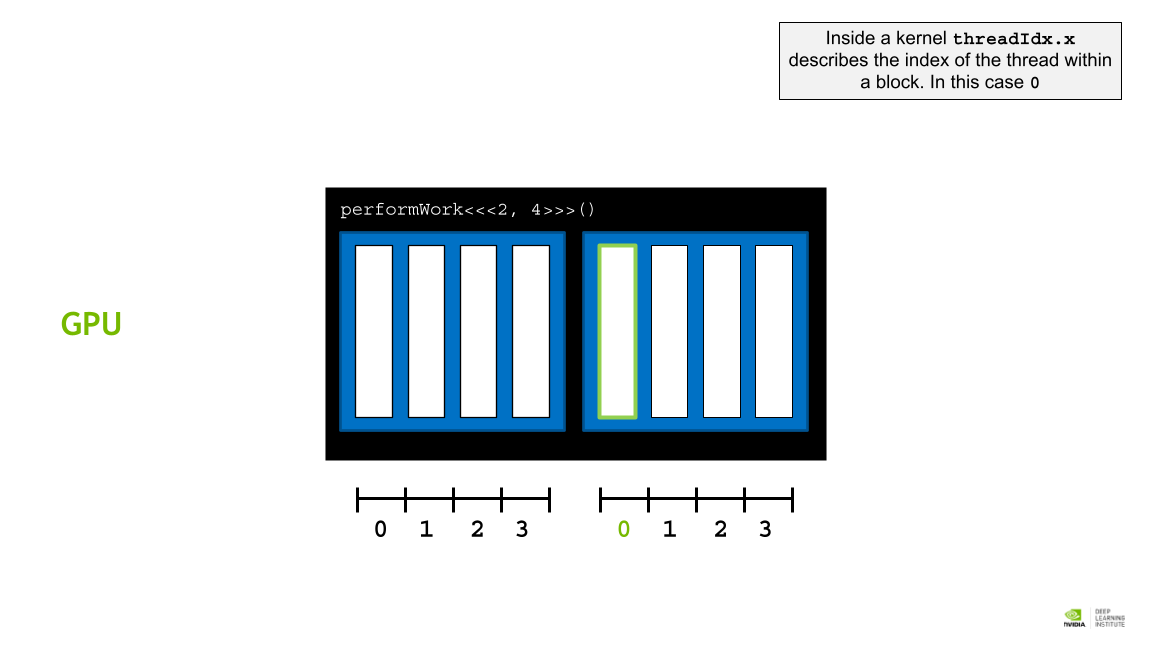
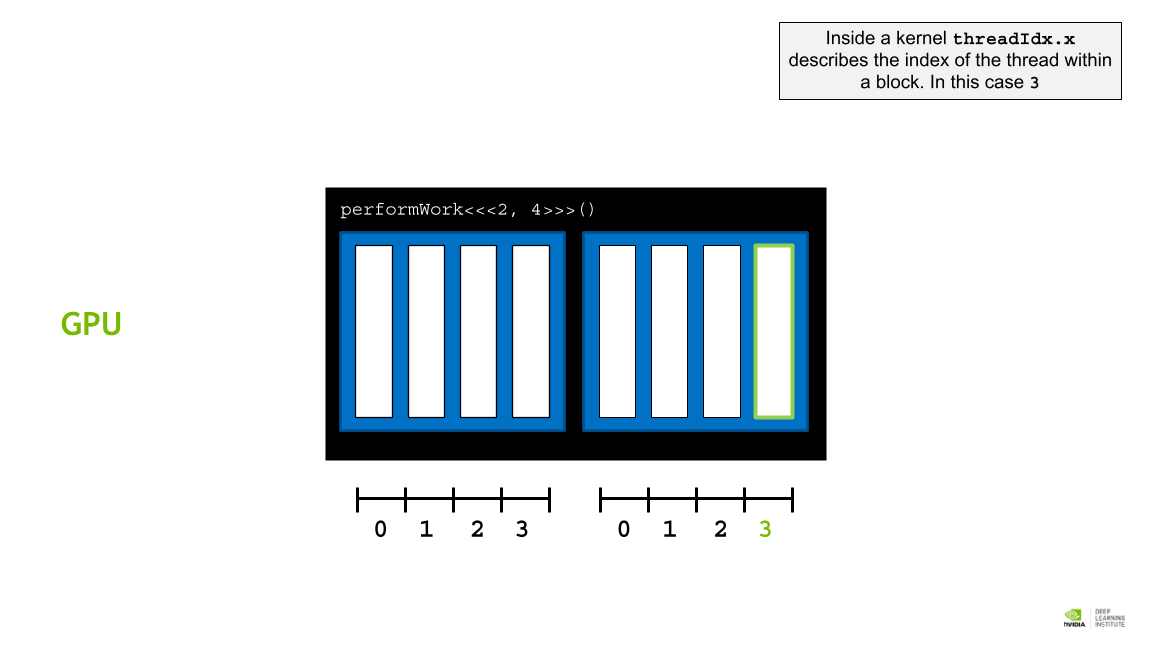
CUDA Thread Hierarchy 에서는 미리 정해진 변수를 통해 각 block 과 thread에 접근할 수 있다.
1
2
3
4
5
6
7
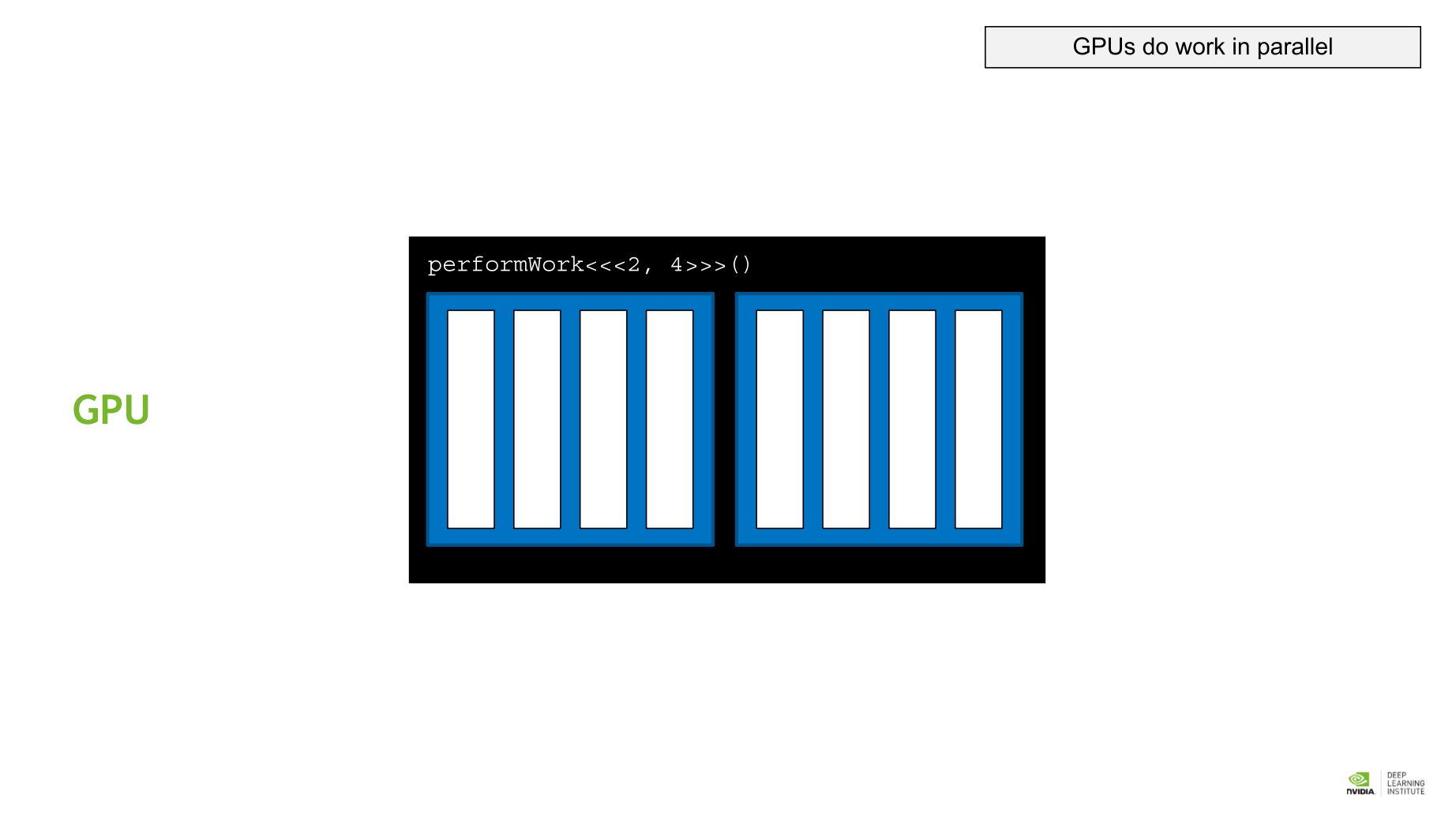
- gridDim.x: gird 내에 있는 block의 개수. performWork<<<2, 4>>>() 같은 kernel의 경우 블록 갯수가 2가 된다. [블록 갯수]
- blockIdx.x: grid 내에 있는 block들 중 해당 block의 위치 인덱스. performWork<<<2,4>>>() 와 같은 kernel을 실행한다면 0, 1 이 될 수 있다. [블록 인덱스 접근]
- blockDim.x: block 내에 있는 thread의 갯수. performWork<<<2, 4>>>() 와 같은 kernel의 경우 4가 된다. 한 grid내에 있 는 모든 block은 같은 수의 thread를 가진다. [쓰레드 갯수]
- threadIdx.x: block내에 있는 thread 중 해당 thread의 위치 인덱스. performWork<<<2, 4>>>()와 같은 kernel의 경우 0, 1, 2, 3 중 하나가 된다. [쓰레드 인덱스 접근]
Accelerating For Loops
반복문 가속화
Exercise: Accelerating For Loop with a Single Block of Threads
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#include <stdio.h>
/*
* Refactor 'loop' to be a CUDA Kernel. The new kernel should
* only do the work of 1 iteration of the original loop.
*/
void loop(int N){
for(int i = 0; i < N; i++){
printf("This is iteration number %d\n", i);
}
}
int main(){
/*
* When refactoring 'loop' to launch as a kernel, be sure
* to use the execution configuration to control how many
* "iterations" to perform.
* For this execrcise, only use 1 block of threads.
*/
int N = 10;
loop(N);
}
이런 반복문을 어떻게 GPU로 가속할 수 있을까? 병렬화를 하기 위해서는 2가지 단계를 꼭 거쳐야 한다:
- kernel 은 해당 반복문에서 딱 한 번의 반복 작업만 하도록 설계되어야 한다.
- kernel 이 다른 kernel에 대해서 알지 못하기 때문에, execution configuration이 해당 반복문에서 반복되는 작업의 수에 맞춰 선언되어야 한다.
위에서 배운 Thread Hierarchy Variable을 활용하면 이를 달성할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
#include <stdio.h>
__global__ void loop(){
printf("This is iteration number %d\n", threadIdx.x);
}
int main(){
int N = 10;
loop<<<1, N>>>(); // 1개 블록, 블록 내부 쓰레드 10개
cudaDeviceSynchronize();
}
This post is licensed under CC BY 4.0 by the author.