2. Categorical Feature Encoding Challenge
2. Categorical Feature Encoding Challenge
| 난이도 | 2 | |||
|---|---|---|---|---|
| 경진대회명 | 범주형 데이터 이진분류 경진대회 | |||
| 미션 | 다양한 범주형 데이터를 활용해 타겟값 1에 속할 확률 예측 | |||
| 문제유형 | 이진분류 | 평가지표 | ROC AUC | |
| 제출시 사용한 모델 | 로지스틱 회귀 | |||
| 파이썬 버전 | 3.7.10 | |||
| 사용 라이브러리 버전 | numpy == 1.19.5 pandas == 1.3.2 seaborn == 0.11.2 matplotlib == 3.4.3 sklearn == 0.32.2 scipy ==1.7.1 |
학습 목표
- 범주형 데이터를 활용해 이진분류하는 경진대회에 참가
- 피처 구성을 이해하기 위해 탐색적 데이터 분석을 자세히 학습
- 데이터 특성에 따른 맞춤형 인코딩 방법 학습
- 최종적으로 프라이빗 리더보드에서 2등을 기록하는 모델 제작
학습 순서
- 경진대회 이해
- 탐색적 데이터 분석
- 베이스라인 모델(로지스틱 회귀)
- 성능개선 I (피처 엔지니어링 강화)
- 성능 개선 II (검증 데이터까지 훈련에 이용)
학습 키워드
- 유형 및 평가 지표 : 이진분류, ROC AUC
- 탐색적 데이터 분석 : 피처 요약표, 타겟값 분포, 이진/명목형/순서형/날짜 피처 분포
- 머신러닝 모델 : 로지스틱 회귀
- 피처 앤지니어링 : 원-핫 인코딩, 피처 맞춤 인코딩, 피처 스케일링
- 하이퍼파라미터 최적화 : 그리드 서치
1. 경진대회 이해
- 본 대회의 목표는 범주형 feature 23개를 활용해 해당 데이터가 타겟값 1에 속할 확률을 예측하는 것이다.
- 본 경진대회의 특징
본 대회는 인위적으로 만든 데이터를 제공한다. (연습용으로는 인공 데이터가 오히려 좋다.)
각 피처와 타겟값의 의미를 알 수 없다. 자전거 대여 수요 예측은 다르게 날씨가 좋을수록 자전거 대여 수량이 많을것이라 예상할 수 있었지만 이런 경우 활용할 수 있는 배경 지식이 없기 때문에 순전히 데이터만 보고 접근해야 한다.
- 제공되는 데이터가 모두 범주형이다. 값이 두개로만 구성된 데이터부터 순서형 데이터(ordinal data), 명목형 데이터(nominal data), 날짜 데이터까지 다양하게 제공된다.
- bin_로 시작하는 피처는 이진 피처, nom_로 시작하는 피처는 명목형 피처, ord_로 시작하는 피처는 순서형 피처이다.
- 순서형 피처 중 ord_3, ord_4, ord_5 는 알파벳순으로 고윳값 순서가 매져있다.
- 타겟값도 범주형 데이터 이다. 0과 1 두개로 구성되어 있다.
확률 예측
분류 문제에서는 타겟값이 0이냐 1이냐가 아니라 ‘1일 확률’을 예측한다. 보통 음성 값일 확률보다는 양성 값일 확률로 예측한다. 일반적으로 0은 음성, 1은 양성을 나타낸다. 스팸 메일을 거르는 문제라면 0은 일반 메일, 1은 스팸 메일을 뜻한다. 암을 진단하는 문제에서도 0은 정상, 1은 암 진단을 의미한다. 이런 문제들에서 우리가 알고싶은건 스팸 메일일 확률이나 암일 확률이기 때문에 양성값인 1일 확률을 예측한다.
2. 탐색적 데이터 분석
분석 과정은 아래와 같은 순서로 진행된다.
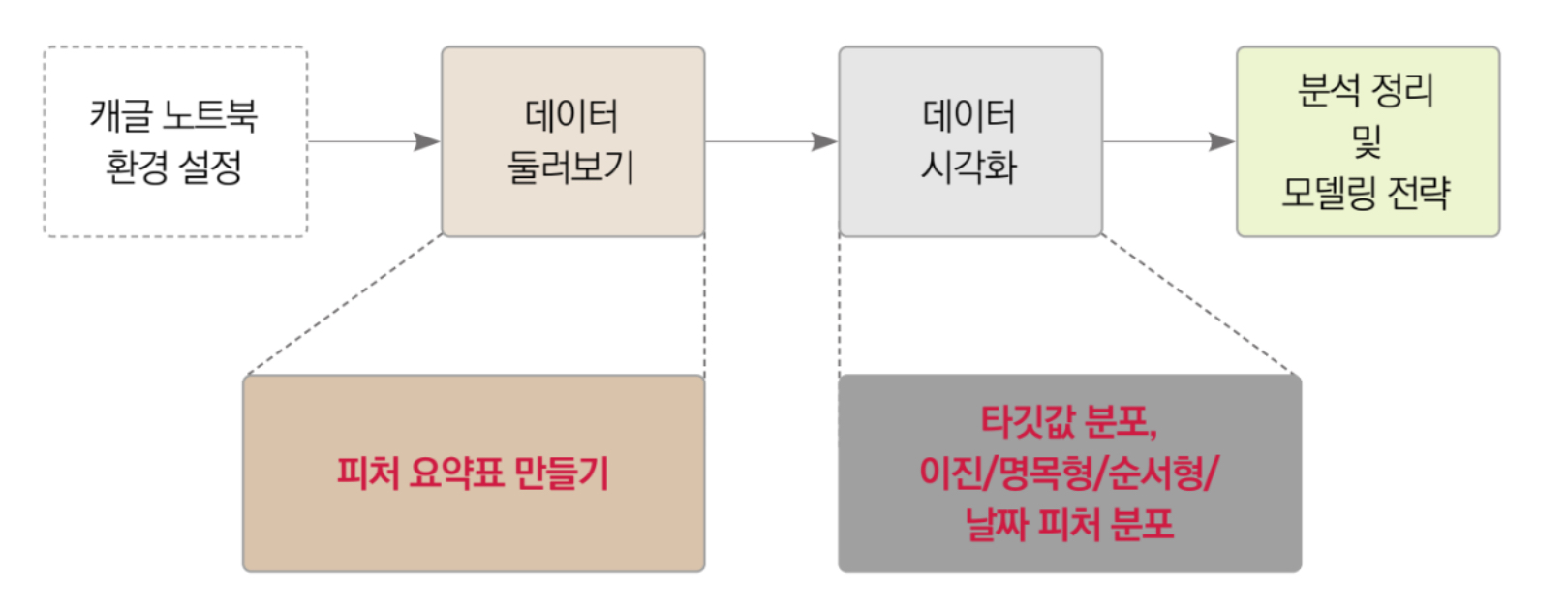
2.1 탐색적 데이터 분석
kaggle competitions download -c cat-in-the-dat
데이터 로드 및 shape 확인
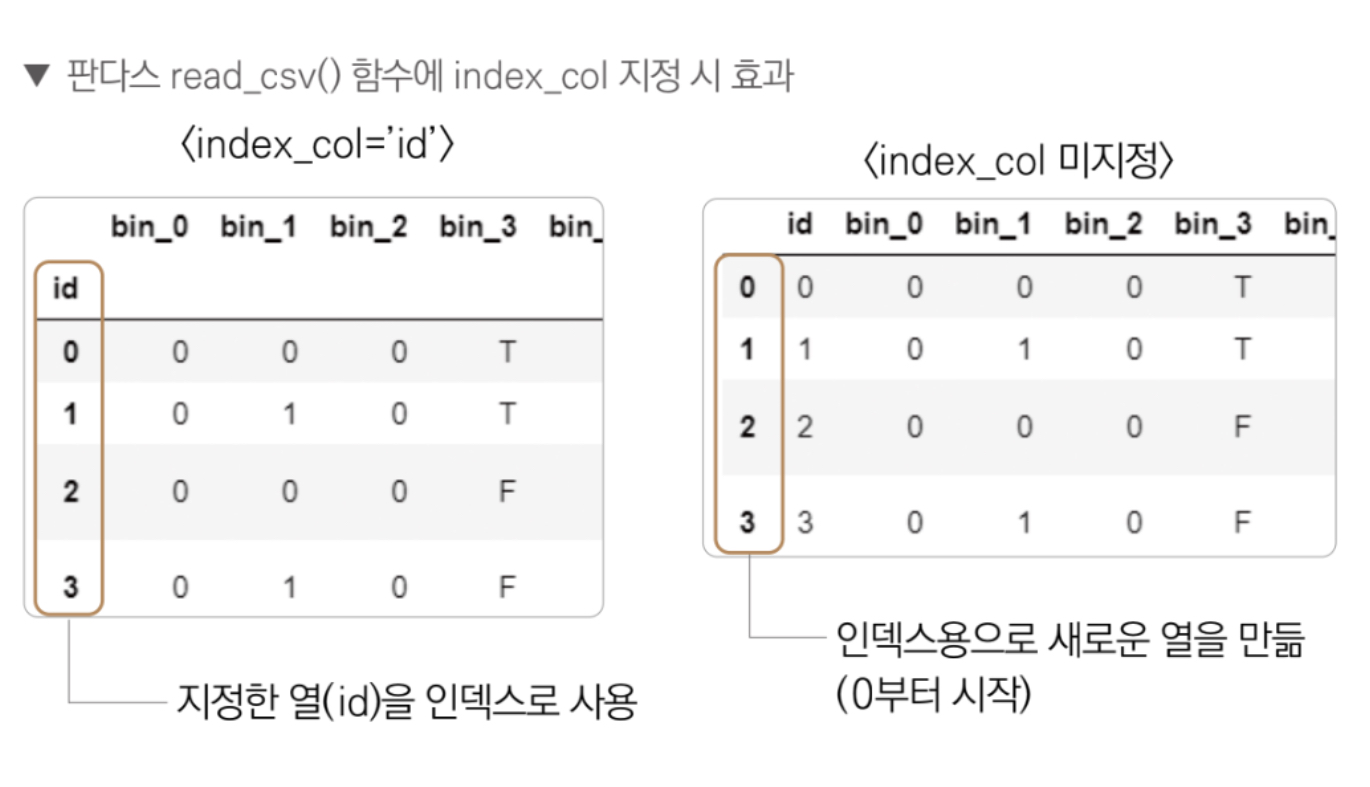
데이터를 읽어올 때 index_col 파라미터에 데이터가 가지고 있는 id를 전달했다. 열 이름을 전달하면 해당 열을 인덱스로 지정하며 명시하지 않으면 0부터 시작하는 새로운 열을 생성해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import pandas as pd
import numpy as np
data_path = 'datasets/'
train = pd.read_csv(data_path + 'train.csv', index_col = 'id')
test = pd.read_csv(data_path + 'test.csv', index_col = 'id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col = 'id')
print(train.shape, test.shape)
'''
(300000, 24) (200000, 23)
'''
train, test, submission의 첫 5행 출력
1
train.head()
| bin_0 | bin_1 | bin_2 | bin_3 | bin_4 | nom_0 | nom_1 | nom_2 | nom_3 | nom_4 | ... | nom_9 | ord_0 | ord_1 | ord_2 | ord_3 | ord_4 | ord_5 | day | month | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||
| 0 | 0 | 0 | 0 | T | Y | Green | Triangle | Snake | Finland | Bassoon | ... | 2f4cb3d51 | 2 | Grandmaster | Cold | h | D | kr | 2 | 2 | 0 |
| 1 | 0 | 1 | 0 | T | Y | Green | Trapezoid | Hamster | Russia | Piano | ... | f83c56c21 | 1 | Grandmaster | Hot | a | A | bF | 7 | 8 | 0 |
| 2 | 0 | 0 | 0 | F | Y | Blue | Trapezoid | Lion | Russia | Theremin | ... | ae6800dd0 | 1 | Expert | Lava Hot | h | R | Jc | 7 | 2 | 0 |
| 3 | 0 | 1 | 0 | F | Y | Red | Trapezoid | Snake | Canada | Oboe | ... | 8270f0d71 | 1 | Grandmaster | Boiling Hot | i | D | kW | 2 | 1 | 1 |
| 4 | 0 | 0 | 0 | F | N | Red | Trapezoid | Lion | Canada | Oboe | ... | b164b72a7 | 1 | Grandmaster | Freezing | a | R | qP | 7 | 8 | 0 |
5 rows × 24 columns
train.head()로 출력하면 중간에 피처가 생략된 상태로 출력돼 보기 불편하다. 이때 T 메서드를 호출하면 한눈에 보기 편하게 행과 열의 위치가 바뀐다.
1
train.head().T
| id | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| bin_0 | 0 | 0 | 0 | 0 | 0 |
| bin_1 | 0 | 1 | 0 | 1 | 0 |
| bin_2 | 0 | 0 | 0 | 0 | 0 |
| bin_3 | T | T | F | F | F |
| bin_4 | Y | Y | Y | Y | N |
| nom_0 | Green | Green | Blue | Red | Red |
| nom_1 | Triangle | Trapezoid | Trapezoid | Trapezoid | Trapezoid |
| nom_2 | Snake | Hamster | Lion | Snake | Lion |
| nom_3 | Finland | Russia | Russia | Canada | Canada |
| nom_4 | Bassoon | Piano | Theremin | Oboe | Oboe |
| nom_5 | 50f116bcf | b3b4d25d0 | 3263bdce5 | f12246592 | 5b0f5acd5 |
| nom_6 | 3ac1b8814 | fbcb50fc1 | 0922e3cb8 | 50d7ad46a | 1fe17a1fd |
| nom_7 | 68f6ad3e9 | 3b6dd5612 | a6a36f527 | ec69236eb | 04ddac2be |
| nom_8 | c389000ab | 4cd920251 | de9c9f684 | 4ade6ab69 | cb43ab175 |
| nom_9 | 2f4cb3d51 | f83c56c21 | ae6800dd0 | 8270f0d71 | b164b72a7 |
| ord_0 | 2 | 1 | 1 | 1 | 1 |
| ord_1 | Grandmaster | Grandmaster | Expert | Grandmaster | Grandmaster |
| ord_2 | Cold | Hot | Lava Hot | Boiling Hot | Freezing |
| ord_3 | h | a | h | i | a |
| ord_4 | D | A | R | D | R |
| ord_5 | kr | bF | Jc | kW | qP |
| day | 2 | 7 | 7 | 2 | 7 |
| month | 2 | 8 | 2 | 1 | 8 |
| target | 0 | 0 | 0 | 1 | 0 |
테스트 데이터 인덱스가 300,000 부터 시작하기 때문에 submission id는 300,000 부터 시작한다.
1
submission.head()
| target | |
|---|---|
| id | |
| 300000 | 0.5 |
| 300001 | 0.5 |
| 300002 | 0.5 |
| 300003 | 0.5 |
| 300004 | 0.5 |
1
test.head().T
| id | 300000 | 300001 | 300002 | 300003 | 300004 |
|---|---|---|---|---|---|
| bin_0 | 0 | 0 | 1 | 0 | 0 |
| bin_1 | 0 | 0 | 0 | 0 | 1 |
| bin_2 | 1 | 0 | 1 | 1 | 1 |
| bin_3 | T | T | F | T | F |
| bin_4 | Y | N | Y | Y | N |
| nom_0 | Blue | Red | Blue | Red | Red |
| nom_1 | Triangle | Square | Square | Star | Trapezoid |
| nom_2 | Axolotl | Lion | Dog | Cat | Dog |
| nom_3 | Finland | Canada | China | China | China |
| nom_4 | Piano | Piano | Piano | Piano | Piano |
| nom_5 | 0870b0a5d | a5c276589 | 568550f04 | c5725677e | e70a6270d |
| nom_6 | 9ceb19dd6 | 1ad744242 | 1fe17a1fd | a6542cec0 | 97b6a3518 |
| nom_7 | 530f8ecc3 | 12e6161c9 | 27d6df03f | 30c63bd0c | a42386065 |
| nom_8 | 9d117320c | 46ae3059c | b759e21f0 | 0b6ec68ff | f91f3b1ee |
| nom_9 | 3c49b42b8 | 285771075 | 6f323c53f | b5de3dcc4 | 967cfa9c9 |
| ord_0 | 2 | 1 | 2 | 1 | 3 |
| ord_1 | Novice | Master | Expert | Contributor | Grandmaster |
| ord_2 | Warm | Lava Hot | Freezing | Lava Hot | Lava Hot |
| ord_3 | j | l | a | b | l |
| ord_4 | P | A | G | Q | W |
| ord_5 | be | RP | tP | ke | qK |
| day | 5 | 7 | 1 | 2 | 4 |
| month | 11 | 5 | 12 | 3 | 11 |
2.2 피처 요약표 생성
피처 요약표는 피처별 데이터 타입, 결측값 개수, 고윳값 개수, 실제 입력값 등을 정리한 표이다.
피처 요약표를 만드는 3단계
1. 피처별 데이터 타입 DataFrame 생성*
2. 인덱스 재설정 후 열 이름 변경
3. 결측값 개수, 고윳값 개수, 1~3행 입력값 추가
1. 피처별 데이터 타입 DataFrame 생성
DataFrame 객체에서 dtypes를 호출하면 피처별 데이터 타입을 반환해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
train.dtypes
'''
bin_0 int64
bin_1 int64
bin_2 int64
bin_3 object
bin_4 object
nom_0 object
nom_1 object
nom_2 object
nom_3 object
nom_4 object
nom_5 object
nom_6 object
nom_7 object
nom_8 object
nom_9 object
ord_0 int64
ord_1 object
ord_2 object
ord_3 object
ord_4 object
ord_5 object
day int64
month int64
target int64
dtype: object
'''
이 값을 입력으로 DataFrame을 새로 생성하면 피처별 데이터 타입이 입력된 DataFrame이 만들어진다. 이 때 다음과 같이 columns 파라미터로 원하는 열 이름을 설정할 수 있다.
1
2
summary = pd.DataFrame(train.dtypes, columns = ['데이터 타입'])
summary.head()
| 데이터 타입 | |
|---|---|
| bin_0 | int64 |
| bin_1 | int64 |
| bin_2 | int64 |
| bin_3 | object |
| bin_4 | object |
2. 인덱스 재설정 후 열 이름 변경
현재 피처 이름들이 인덱스로 사용중이기 떄문에 현재 인덱스를 열로 옮기고 새로운 인덱스를 만든다.
reset_index()를 호출하면 현재 인덱스를 열로 옮기고 새로운 인덱스를 만든다. 새로운 인덱스는 0부터 시작해 1씩 증가하는 정수이며, 옮겨진 열의 이름은 ‘index’가 된다.
1
2
3
summary = summary.reset_index()
summary.head()
| index | 데이터 타입 | |
|---|---|---|
| 0 | bin_0 | int64 |
| 1 | bin_1 | int64 |
| 2 | bin_2 | int64 |
| 3 | bin_3 | object |
| 4 | bin_4 | object |
현재 피처 이름이 포함된 열 이름이 index 이기 때문에 rename()함수를 사용해 열 이름을 ‘피처’로 바꾼다.
1
2
3
summary = summary.rename(columns={'index':'피처'})
summary.head()
| 피처 | 데이터 타입 | |
|---|---|---|
| 0 | bin_0 | int64 |
| 1 | bin_1 | int64 |
| 2 | bin_2 | int64 |
| 3 | bin_3 | object |
| 4 | bin_4 | object |
3. 결측값 개수, 고유값 개수, 1~3행 입력값 추가
DataFrame에 결측값 개수, 고윳값 개수, 첫 세 개 행에 입력된 값을 추가해 보자.
피처별 결측값 개수를 DataFrame에 추가한다. isnull()은 결측값 포함 여부를 True, False로 반환하는 함수이다. True는 1, False는 0으로 간주되어 isnull()을 적용한 DataFrame에 sum() 함수를 호출하면 True의 개수, 즉 피처별 결측값 개수를 구해준다.
피처별 고유값 개수를 추가한다. nunique()는 피처별 고윳값 개수를 구하는 함수이다.
훈련 데이터 1~3행에 입력된 값을 요약표 DataFrame에 추가한다. 각 피처에 실제 어떤 값들이 들어있는지 확인하기 위함이다. loc[0]은 첫 번째 행, loc[1]은 두번째 행, loc[2]는 세번째 행의 값을 의미한다.
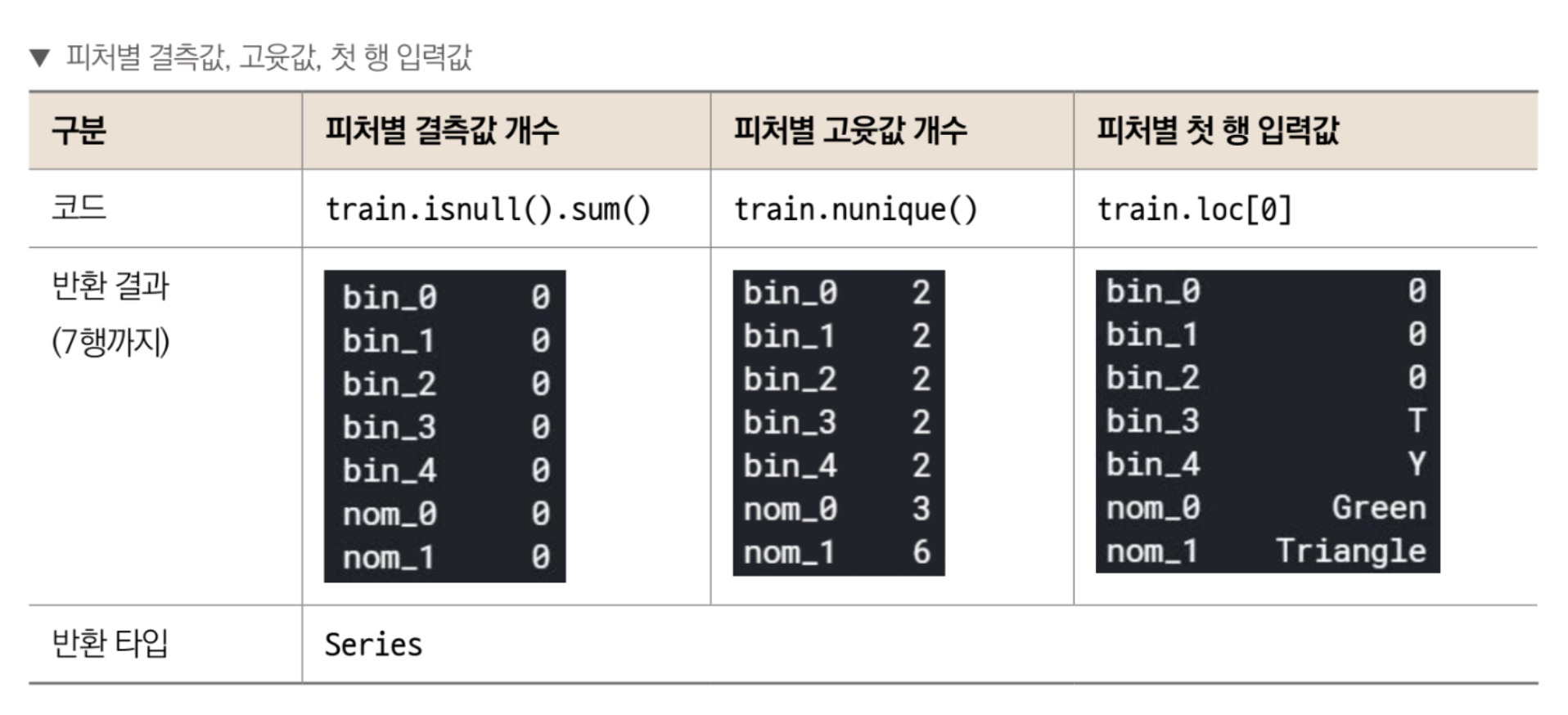
values 를 적용하지 않으면 반환 타입인 Series는 인덱스(bin_0, bin_1 등)과 값(0 등)의 쌍으로 이루어져 있다. 따라서 values를 호출해 값만 추출하여 summary에 추가한다.
axis 값 | 기준 방향 | 작동 방향 | 의미 |
|---|---|---|---|
axis=0 | 행(row) 기준 | 위→아래 방향 | 열(column) 단위 계산 |
axis=1 | 열(column) 기준 | 왼→오 방향 | 행(row) 단위 계산 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 1. 피처별 결측값 개수
summary['결측값 개수'] = train.isnull().sum().values
'''
- isnull() ➝ 원소 단위로 작동해서 True / False 값을 가진 동일 크기의 DataFrame을 반환
- sum() ➝ 기본적으로 열 단위(axis=0)로 작동해서 각 열의 결측값 개수를 반환
'''
# 2. 피처별 고윳값 개수
summary['고윳값 개수'] = train.nunique().values
'''
nunique()는 기본적으로 열(axis=0) 단위로 작동
'''
# 3. 1~3행에 입력되어 있는 값
summary['첫 번째 값'] = train.loc[0].values
summary['두 번째 값'] = train.loc[1].values
summary['세 번째 값'] = train.loc[1].values
summary.head()
| 피처 | 데이터 타입 | 결측값 개수 | 고윳값 개수 | 첫 번째 값 | 두 번째 값 | 세 번째 값 | |
|---|---|---|---|---|---|---|---|
| 0 | bin_0 | int64 | 0 | 2 | 0 | 0 | 0 |
| 1 | bin_1 | int64 | 0 | 2 | 0 | 1 | 1 |
| 2 | bin_2 | int64 | 0 | 2 | 0 | 0 | 0 |
| 3 | bin_3 | object | 0 | 2 | T | T | T |
| 4 | bin_4 | object | 0 | 2 | Y | Y | Y |
4. 피처 요약표 생성함수
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def resumetable(df):
print(f'데이터셋 형상: {df.shape}')
# 스텝 1: 피처별 데이터 타입 DataFrame 생성
summary = pd.DataFrame(df.dtypes, columns=['데이터 타입'])
# 스텝 2: 인덱스 재설정 후 열 이름 변경
# 2-1: 인덱스 재설정
summary = summary.reset_index()
# 2-2: 열 이름 변경
summary = summary.rename(columns={'index': '피처'})
# 스텝 3: 결측값 개수, 고윳값 개수, 1~3행 입력값 추가
# 피처별 결측값 개수
summary['결측값 개수'] = df.isnull().sum().values
# 피처별 고윳값 개수
summary['고윳값 개수'] = df.nunique().values
# 1~3행에 입력되어 있는 값
summary['첫 번째 값'] = df.loc[0].values
summary['두 번째 값'] = df.loc[1].values
summary['세 번째 값'] = df.loc[2].values
return summary
resumetable(train)
데이터셋 형상: (300000, 24)
| 피처 | 데이터 타입 | 결측값 개수 | 고윳값 개수 | 첫 번째 값 | 두 번째 값 | 세 번째 값 | |
|---|---|---|---|---|---|---|---|
| 0 | bin_0 | int64 | 0 | 2 | 0 | 0 | 0 |
| 1 | bin_1 | int64 | 0 | 2 | 0 | 1 | 0 |
| 2 | bin_2 | int64 | 0 | 2 | 0 | 0 | 0 |
| 3 | bin_3 | object | 0 | 2 | T | T | F |
| 4 | bin_4 | object | 0 | 2 | Y | Y | Y |
| 5 | nom_0 | object | 0 | 3 | Green | Green | Blue |
| 6 | nom_1 | object | 0 | 6 | Triangle | Trapezoid | Trapezoid |
| 7 | nom_2 | object | 0 | 6 | Snake | Hamster | Lion |
| 8 | nom_3 | object | 0 | 6 | Finland | Russia | Russia |
| 9 | nom_4 | object | 0 | 4 | Bassoon | Piano | Theremin |
| 10 | nom_5 | object | 0 | 222 | 50f116bcf | b3b4d25d0 | 3263bdce5 |
| 11 | nom_6 | object | 0 | 522 | 3ac1b8814 | fbcb50fc1 | 0922e3cb8 |
| 12 | nom_7 | object | 0 | 1220 | 68f6ad3e9 | 3b6dd5612 | a6a36f527 |
| 13 | nom_8 | object | 0 | 2215 | c389000ab | 4cd920251 | de9c9f684 |
| 14 | nom_9 | object | 0 | 11981 | 2f4cb3d51 | f83c56c21 | ae6800dd0 |
| 15 | ord_0 | int64 | 0 | 3 | 2 | 1 | 1 |
| 16 | ord_1 | object | 0 | 5 | Grandmaster | Grandmaster | Expert |
| 17 | ord_2 | object | 0 | 6 | Cold | Hot | Lava Hot |
| 18 | ord_3 | object | 0 | 15 | h | a | h |
| 19 | ord_4 | object | 0 | 26 | D | A | R |
| 20 | ord_5 | object | 0 | 192 | kr | bF | Jc |
| 21 | day | int64 | 0 | 7 | 2 | 7 | 7 |
| 22 | month | int64 | 0 | 12 | 2 | 8 | 2 |
| 23 | target | int64 | 0 | 2 | 0 | 0 | 0 |
2.3 피처 요약표 해석
이진(binary) 피처: bin_0 ~ bin_4
명목형(nominal) 피처: nom_0 ~ nom_9
순서형(ordinal) 피처: ord_0 ~ ord_5
그 외 피처: day, month, target
1. 이진(binary) 피처: bin_0 ~ bin_4
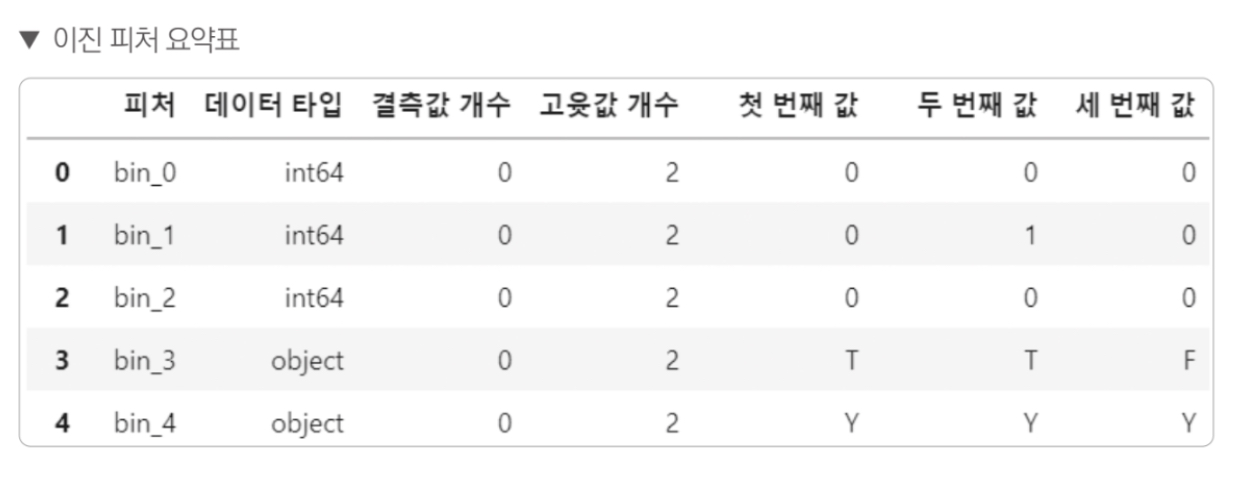
이진 피처들은 고윳값이 모두 2개이다. 이중 bin_0, bin_1, bin_2 는 데이터 타입이 int64고, 실젯값이 0 또는 1로 구성돼 있다.
bin_3, bin_4는 object 타입이고, 실젯값은 T 또는 F(bin_3 피처), Y 또는 N(bin_4 피처) 이다.
따라서 T와 Y는 1로, F와 N은 0으로 인코딩 한다.
2. 명목형(nominal) 피처: nom_0 ~ nom_9
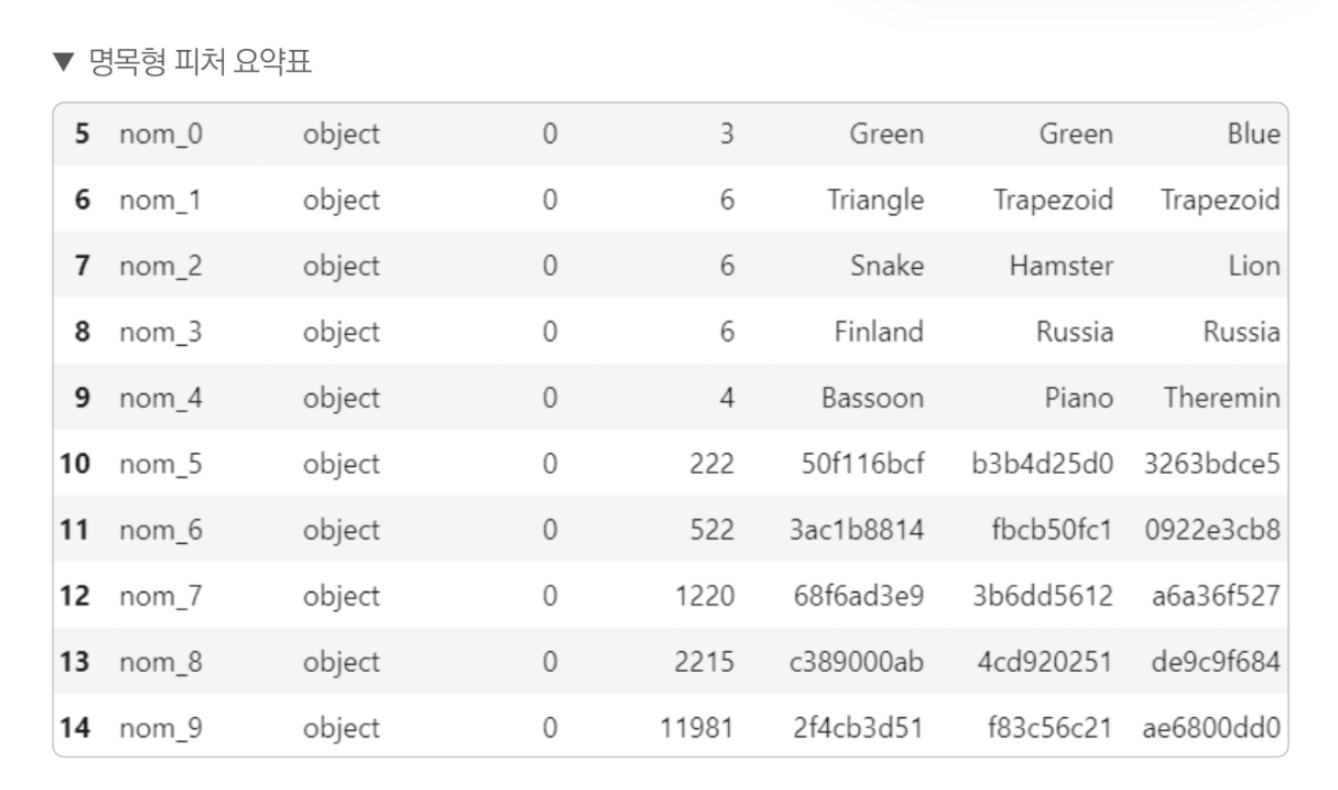
- 명목형 피처는 모두 object 타입이고 결측값은 없다. nom_0 부터 nom_4는 고윳값이 6개 이하인데, nom_5 부터 nom_9는 고윳값이 많으며 의미를 알 수 없는 값을 확인할 수 있다.
3. 순서형(ordinal) 피처: ord_0 ~ ord_5
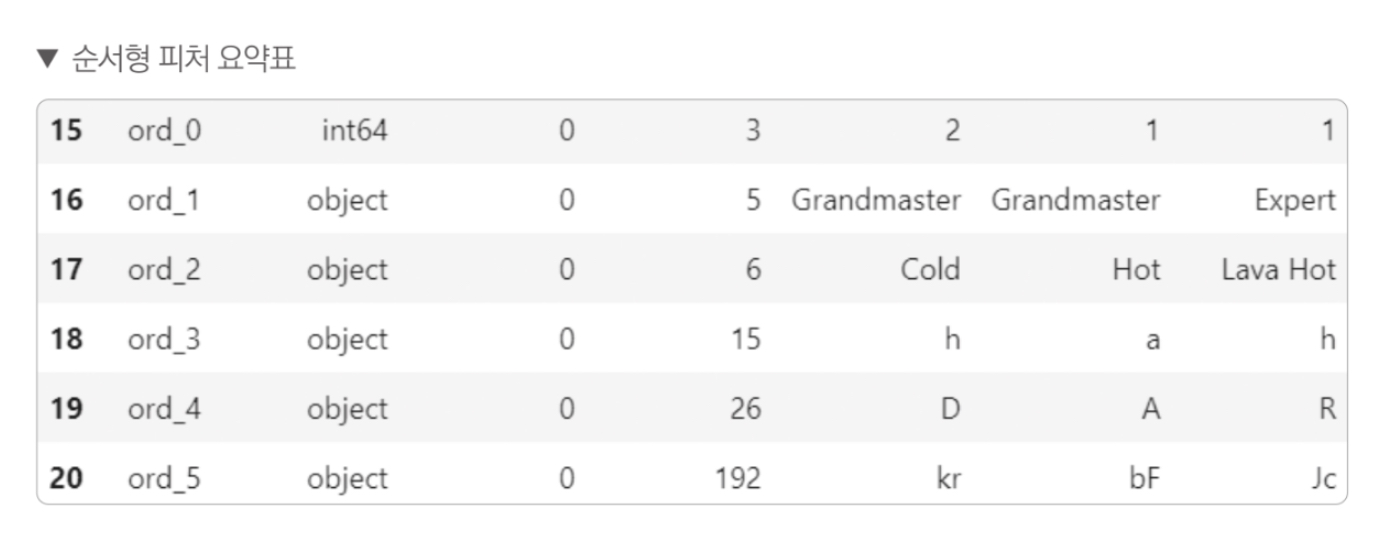
ord_0 피처만 int64 타입이고 나머지는 object 타입니다. 명목형 데이터와 다르게 순서형 데이터는 순서가 매우 중요하다.
순서에 따라 타겟값에 미치는 영향이 다르기 때문에 순서에 유의하여 인코딩 해야한다.
ord_0, ord_1, ord_2 feature 고윳값 확인
unique()함수를 통해 고윳값을 구할 수 있다.
1
2
3
4
5
6
7
8
9
for i in range(3):
feature = 'ord_' + str(i)
print(f'{feature} 고윳값: {train[feature].unique()}')
'''
ord_0 고윳값: [2 1 3]
ord_1 고윳값: ['Grandmaster' 'Expert' 'Novice' 'Contributor' 'Master']
ord_2 고윳값: ['Cold' 'Hot' 'Lava Hot' 'Boiling Hot' 'Freezing' 'Warm']
'''
unique() 함수는 고윳값이 등장한 순으로 출력한다. ord_0 피처의 고윳값은 숫자 크기에 순서를 맞추면 되고 ord_1 피처의 고윳값은 등급에 따라 Novice, Contributor, Expert, Master, Grandmaster 순으로 맞춘다.
ord_2 피처는 춥고 더움 정도를 나타내므로 Freezing, Cold, Warm, Hot, Boiling Hot, Lava Hot 순으로 맞춘다.
미리 정리해놔야 인코딩할 때 순서에 맞게 매핑하기 편하다.
고윳값 개수가 많은 ord_3, ord_4, ord_5 feature 고윳값 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
for i in range(3, 6):
feature = 'ord_' + str(i)
print(f'{feature} 고윳값 : {train[feature].unique()}', end='\n\n')
'''
ord_3 고윳값 : ['h' 'a' 'i' 'j' 'g' 'e' 'd' 'b' 'k' 'f' 'l' 'n' 'o' 'c' 'm']
ord_4 고윳값 : ['D' 'A' 'R' 'E' 'P' 'K' 'V' 'Q' 'Z' 'L' 'F' 'T' 'U' 'S' 'Y' 'B' 'H' 'J'
'N' 'G' 'W' 'I' 'O' 'C' 'X' 'M']
ord_5 고윳값 : ['kr' 'bF' 'Jc' 'kW' 'qP' 'PZ' 'wy' 'Ed' 'qo' 'CZ' 'qX' 'su' 'dP' 'aP'
'MV' 'oC' 'RL' 'fh' 'gJ' 'Hj' 'TR' 'CL' 'Sc' 'eQ' 'kC' 'qK' 'dh' 'gM'
'Jf' 'fO' 'Eg' 'KZ' 'Vx' 'Fo' 'sV' 'eb' 'YC' 'RG' 'Ye' 'qA' 'lL' 'Qh'
'Bd' 'be' 'hT' 'lF' 'nX' 'kK' 'av' 'uS' 'Jt' 'PA' 'Er' 'Qb' 'od' 'ut'
'Dx' 'Xi' 'on' 'Dc' 'sD' 'rZ' 'Uu' 'sn' 'yc' 'Gb' 'Kq' 'dQ' 'hp' 'kL'
'je' 'CU' 'Fd' 'PQ' 'Bn' 'ex' 'hh' 'ac' 'rp' 'dE' 'oG' 'oK' 'cp' 'mm'
'vK' 'ek' 'dO' 'XI' 'CM' 'Vf' 'aO' 'qv' 'jp' 'Zq' 'Qo' 'DN' 'TZ' 'ke'
'cG' 'tP' 'ud' 'tv' 'aM' 'xy' 'lx' 'To' 'uy' 'ZS' 'vy' 'ZR' 'AP' 'GJ'
'Wv' 'ri' 'qw' 'Xh' 'FI' 'nh' 'KR' 'dB' 'BE' 'Bb' 'mc' 'MC' 'tM' 'NV'
'ih' 'IK' 'Ob' 'RP' 'dN' 'us' 'dZ' 'yN' 'Nf' 'QM' 'jV' 'sY' 'wu' 'SB'
'UO' 'Mx' 'JX' 'Ry' 'Uk' 'uJ' 'LE' 'ps' 'kE' 'MO' 'kw' 'yY' 'zU' 'bJ'
'Kf' 'ck' 'mb' 'Os' 'Ps' 'Ml' 'Ai' 'Wc' 'GD' 'll' 'aF' 'iT' 'cA' 'WE'
'Gx' 'Nk' 'OR' 'Rm' 'BA' 'eG' 'cW' 'jS' 'DH' 'hL' 'Mf' 'Yb' 'Aj' 'oH'
'Zc' 'qJ' 'eg' 'xP' 'vq' 'Id' 'pa' 'ux' 'kU' 'Cl']
'''
ord_3, ord_4, ord_5 피처는 알파벳순으로 정렬되어 있다. 이 피처들은 알파벳순으로 인코딩 한다.
그 외 features: day, month, target
1
2
3
4
5
6
7
8
9
print('day 고윳값: ', train['day'].unique())
print('month 고윳값: ', train['month'].unique())
print('target 고윳값: ', train['target'].unique())
'''
day 고윳값: [2 7 5 4 3 1 6]
month 고윳값: [ 2 8 1 4 10 3 7 9 12 11 5 6]
target 고윳값: [0 1]
'''
day 피처의 고윳값이 7개 이다. 요일을 나타낸다고 짐작할 수 있다.
month 피처의 고윳값은 1부터 12이다. 월을 나타낸다.
타겟값은 0 또는 1로 구성돼 있다.
3. 데이터 시각화
시각화 라이브러리 import
1
2
3
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
3.1 타겟값 분포 확인
| 플롯 종류 | x 필요 | y 필요 | 데이터 개수 | 주요 목적 |
|---|---|---|---|---|
barplot | ✅ 있음 | ✅ 있음 | 2개 필요 | 카테고리별 통계량(평균) 시각화 |
countplot | ✅ 있음 | ❌ 없음 | 1개면 됨 | 카테고리별 빈도수 시각화 |
histplot | ✅ 있음 | ❌ 없음 | 1개면 됨 | 연속형 수치의 분포 시각화 (히스토그램) |
displot | ✅ 있음 | ❌ 없음 | 1개면 됨 | 조건별 분포(히스토그램 or KDE) 시각화 (Facet 가능) |
kdeplot | ✅ 있음 | ❌ 없음 | 1개면 됨 | 데이터의 확률 밀도 함수 곡선(KDE) 시각화 |
boxplot | ✅ 있음 | ✅ 있음 | 2개 필요 | 사분위/중앙값/이상치 시각화 (통계 요약) |
violinplot | ✅ 있음 | ✅ 있음 | 2개 필요 | boxplot + KDE → 분포와 요약을 동시에 표현 |
stripplot | ✅ 있음 | ✅ 있음 | 2개 필요 | 데이터의 개별 포인트 분포를 점으로 표시 |
swarmplot | ✅ 있음 | ✅ 있음 | 2개 필요 | stripplot의 점이 겹치지 않도록 자동 배치 |
📊 barplot
1
sns.barplot(x="과목", y="점수", data=df) # 과목별 평균 점수
📈 countplot
1
sns.countplot(x="성별", data=df) # → 남자/여자 각각 몇 명인지
📉 histplot
1
sns.histplot(x="연봉", data=df, bins=30) # → 연봉이 1000~~2000, 2000~~3000 이런 식으로 구간별로 몇 명 있는지
타겟값 분포를 알면 데이터가 얼마나 불균형한지 파악하기 쉽다.
이를 위해 카운트플롯으로 타겟값 0과 1의 개수를 파악한다.
카운트플롯은 범주형 데이터 개수를 확인할 때 주로 사용한다. (보통은 양성(타겟값 1)이 음성(타겟값 0)에 비해 개수가 적다.)
수치형 데이터의 분포를 파악할 땐 주로 displot()을 사용하고, 범주형 데이터의 분포를 파악할 땐 countplot()을 사용.
1
2
3
4
5
6
mpl.rc('font', size=15)
plt.figure(figsize=(7, 6))
# 타겟값 분포 카운트플롯
ax = sns.countplot(x='target', data=train)
ax.set_title('Target Distribution')

각 값의 비율을 그래프 상단에 표시
ax.patches
ax.patches 는 ‘ax 축을 구성하는 그래프 도형 객체 모두를 담은 리스트’ 이다.

countplot()에서 막대 도형의 높이는 데이터 개수와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
rectangle = ax.patches[0] # 첫 번째 Rectangle 객체
print('사각형 높이: ', rectangle.get_height())
print('사각형 너비: ', rectangle.get_width())
print('사각형 왼쪽 테두리의 x축 위치: ', rectangle.get_x())
print('텍스트 위치의 x좌표: ', rectangle.get_x() + rectangle.get_width() / 2.0)
print('텍스트 위치의 y좌표: ', rectangle.get_height() + len(train) * 0.001)
''' 출력
사각형 높이: 208236.0
사각형 너비: 0.8
사각형 왼쪽 테두리의 x축 위치: -0.4
텍스트 위치의 x좌표: 0.0
텍스트 위치의 y좌표: 208536.0
'''
비율을 포시헤주는 코드를 함수로 구현한 후, 함수를 사용해 카운트플롯 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def write_percent(ax, total_size):
'''도형 객체를 순회하며 막대 상단에 타겟값 비율 표시'''
for patch in ax.patches:
if patch.get_height() == 0:
continue
height = patch.get_height()
width = patch.get_width()
left_coord = patch.get_x() # 도형 왼쪽 테두리의 x축 위치
percent = height / total_size * 100 # target 값 비율
ax.text(x = left_coord + width / 2.0, # x축 위치
y = height + total_size * 0.001, # y축 위치 (생각보다 많이 커야해서 total_size에서 임의로 곱하는것)
s = f'{percent:1.1f}%', # 입력 텍스트 (s: string)
ha = 'center') # 가운데 정렬 (ha : horizontal alignment)
plt.figure(figsize=(7, 6))
ax = sns.countplot(x='target', data=train)
write_percent(ax, len(train)) # 비율 표시
ax.set_title('Target Disitribution')

3.2 이진 피처 분포
고윳값이 Yes와 No일 때 Yes인 데이터 중에서 타겟값이 0인 데이터와 1인 데이터의 분포(비율)을 나눠그리고, No인 데이터 중에서도 타겟값이 0인 비율과 1인 비율을 따로 그려보면, 특정 고윳값이 특정 타겟값에 치우치는지 확인할 수 있다.
범주형 피처의 타겟값 분포를 고윳값별로 구분해 그려보면 특정 고윳값이 특정 타겟값에 치우치는지 확인할 수 있다.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
import matplotlib.gridspec as gridspec # 여러 그래프를 격자 형태로 배치
# 3행 2열 틀(Figure) 준비
mpl.rc('font', size=12)
grid = gridspec.GridSpec(3, 2) # 그래프(서브플롯)를 3행 2열로 배치
'''
서브플롯을 3행 2열로 배치한 GridSpec 객체를 grid 변수에 할당한다.
추후 grid[0], grid[1], ... 식으로 원하는 서브플롯을 지정할 수 있다.
이진 피처는 총 5개이므로 마지막 서브플롯에는 그래프를 그리지 않는다.
'''
plt.figure(figsize=(10, 16)) # 전체 Figure 크기 설정
plt.subplots_adjust(wspace=0.4, hspace=0.3) # 서브플롯 간 좌우/상하 여백 설정
'''
서브플롯 사이의 여백을 조정한다. 앞에서는 tight_layout()을 이용해 여백을 자동으로 조정했지만,
subplots_adjust()를 활용하면 좌우, 상하 간격을 따로 조정할 수 있다.
wspace=0.4는 좌우 여백을 축 너비의 40%로, hspace=0.3은 상하 여백을 축 높이의 30%로 설정한다.
'''
# 서브플롯 그리기
bin_featuers = ['bin_0', 'bin_1', 'bin_2', 'bin_3', 'bin_4'] # 피처 목록
'''
이진 피처의 목록을 bin_features에 담은 후 for문을 활용해 각각의 카운트플롯을 그린다.
카운트플롯을 그리는 절차는 bin_feature를 순회하며 격자(grid)에서 이번 서브플롯을 그릴 위치를 ax축으로 지정하고
ax축에 타겟값 분포 카운트플롯을 그린 다음 제목을 달고 마지막으로 비율로 표시한다.
'''
for idx, feature in enumerate(bin_featuers):
ax = plt.subplot(grid[idx])
# ax축에 타겟값 붙포 카운트플롯 그리기
sns.countplot(x = feature,
data = train,
hue = 'target',
# `hue`는 색깔을 통해 "또 다른 범주(feature)"를 시각적으로 구분하는 역할
# `hue='target'` → feature가 같더라도, target 값(예: 0 vs 1)으로 서브 카테고리를 나눔
palette = 'pastel', # 그래프 색상 설정
ax = ax)
'''
hue: 세부적으로 나눠 그릴 기준 피처. 여기서는 타겟값을 전달.
palette: 그래프 색상맵. 'pastel'을 전달하면 파스텔톤으로 그래프 그림.
ax: 그래프를 그릴 축
'''
ax.set_title(f'{feature} Distribution by Target') # 그래프 제목 설정
write_percent(ax, len(train)) # 비율 표시
| 속성 | 역할 |
|---|---|
x or y | 메인 기준 (x축 또는 y축의 범주값) |
hue | 세부 그룹을 나누는 추가 기준 |
palette | hue로 구분된 값들에 부여할 색상 조합 |
hue는 시각적으로 “누가 누군지” 색으로 구분짓는 기준

고윳값 별로 나눠봐도 타겟값 0, 1의 분포가 대체로 7:3 수준이다. 즉 이진 피처들이 특정 타겟값에 치우치지 않았음을 확인할 수 있다.
3.3. 명목형 피처 분포
명목형 피처 분포와 명목형 피처별 타겟값 1의 비율을 살펴보자. nom_5부터 nom_9 피처까지는 고유값 개수가 많고 의미를 알 수 없는 문자열이 입력돼 있기 때문에 여기서는 nom_0 부터 nom_4 피처까지만 시각화한다.

Step1: 교차분석표 생성 함수 만들기
위 그림의 포인트플롯은 명목형 피처별 타겟값이 1인 비율을 나타내는 그래프이다. 교차표 혹은 교차분석표는 범주형 데이터 2개를 비교 분석하는 데 사용되는 표로, 각 범주형 데이터의 빈도나 통계량을 행과 열로 결합해놓은 표를 말한다. 여기서 교차분석표를 만드는 이유는 명목형 피처별 타겟값 1의 비율을 구하기 위함이다.
교차분석표를 활용해 명목형 피처와 타겟값을 비교 분석하고, 그 결과를 이용해 그래프를 그린다.
Pandas 의 crosstab() 함수로 교차분석표를 만들 수 있다. 명목형 피처인 nom_0와 타겟값 인 target 간 교차분석표를 만든다.
1
pd.crosstab(train['nom_0'], train['target'])
| target | 0 | 1 |
|---|---|---|
| nom_0 | ||
| Blue | 72914 | 23252 |
| Green | 85682 | 41659 |
| Red | 49640 | 26853 |
현재 인덱스가 피처 이름(nom_0)으로 되어 있다. 이를 열로 가져와야 그래프를 그리기 편기 때문에 인덱스를 재설정 한다.
1
2
crosstab = crosstab.reset_index() #인덱스 재설정
crosstab
| target | nom_0 | 0 | 1 |
|---|---|---|---|
| 0 | Blue | 75.820976 | 24.179024 |
| 1 | Green | 67.285478 | 32.714522 |
| 2 | Red | 64.894827 | 35.105173 |
교차분석표 함수화
1
2
3
4
5
6
7
def get_crosstab(df, feature):
crosstab = pd.crosstab(df[feature], df['target'], normalize='index') * 100
crosstab = crosstab.reset_index()
return crosstab
crosstab = get_crosstab(train, 'nom_0')
crosstab
| target | nom_0 | 0 | 1 |
|---|---|---|---|
| 0 | Blue | 75.820976 | 24.179024 |
| 1 | Green | 67.285478 | 32.714522 |
| 2 | Red | 64.894827 | 35.105173 |
포인트플롯은 타겟값 1의 비율을 나타내는 그래프이기 때문에 1인 비율만 선택한다.
key값의 타입에 따른 접근 방식
- 문자열 컬럼명:
df['column_name']- 예: df[‘target’], df[‘nom_0’]
- 반드시 따옴표 필요
- 숫자형 컬럼명:
df[0],df[1]- int나 float 타입의 컬럼명
- 직접 숫자로 접근
- 따옴표 사용하면 KeyError 발생
- 변수에 저장된 컬럼명:
df[variable]- 예: feature = ‘nom_0’일 때 df[feature]
1
2
3
4
5
6
7
8
crosstab[1]
''' 출력
0 24.179024
1 32.714522
2 35.105173
Name: 1, dtype: float64
'''
Step2: 포인트플롯 생성 함수 만들기
교차분석표를 통해 타겟값 1의 비율을 나타내는 포인트플롯을 그리는 함수를 만든다.
함수 이름은 plot_pointpolt()이며 다음의 세 파라미터를 받는다.
- ax: 포인트플롯 그릴 축
- feature: 포인트플롯으로 그릴 피처
- crosstab: 교차분석표
plot_pointplot()은 이미 카운트플롯이 그려진 축에 포인트플롯을 중복으로 그려준다.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def plot_pointplot(ax, feature, crosstab):
ax2 = ax.twinx() # x축은 공유하고 y축은 공유하지 않는 새로운 축 생성
'''
축 하나에 서로 다른 그래프를 그리려면 x축을 공유해야한다.
ax.twinx()로 x축은 공유하지만 y축은 공유하지 않는 새로운 축 ax2를 만든다.
ax2 는 포인트플롯을 그리기 위한 축이다.
'''
# 새로운 축에 포인트플롯 그리기
ax2 = sns.pointplot(x=feature, y=1, data=crosstab,
order=crosstab[feature].values, # 포인트플롯 순서
color='black', # 포린트플롯 색상
legend=False) # 범례 미표시
'''
y 파라미터에는 타겟값이 양성(True, Yes 등등)인 비율을 나타내는 1, data 파라미터에는 교차분석표 crosstab을 전달한다.
order 파라미터에는 포인트플롯을 그릴 순서를 전달할 수 있다. 교차분석표의 열 순서대로 그리도록 했다.
(crosstab['nom_0'].values -> array(['Blue', 'Green', 'Red'], dtype=object))
'''
ax2.set_ylim(crosstab[1].min()-5, crosstab[1].max()*1.1) # y축 범위 설정 (추세를 보기 위한 왜곡)
'''
포인트플롯을 보기 좋게 하기 위해 y축 범위를 설정한다. 타겟값이 1인 비율 중 최솟값에서 5를 뺀 수치부터
최댓값에 1.1을 곱한 수치까지로 잡았다.
'''
ax2.set_ylabel('Target 1 Ratio(%)')
Step3: 피처 분포도 및 피처별 타겟값 1의 비율 포인트플롯 생성 함수 만들기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
def plot_cat_dist_with_true_ratio(df, features, num_rows, num_cols, size=(15, 20)):
plt.figure(figsize=size) # 전체 Figure 크기 설정
grid = gridspec.GridSpec(num_rows, num_cols) # 서브플롯 배치
'''
서브플롯들을 격자 형태로 배치하기 위해 GridSpec을 사용한다.
'''
plt.subplots_adjust(wspace=0.45, hspace=0.3) # 서브플롯 좌우/상하 여백 설정
for idx, feature in enumerate(features): # features를 순회하며 서브플롯을 하나씩 그린다.
ax = plt.subplot(grid[idx])
crosstab = get_crosstab(df, feature) # 교차분석표 생성
# ax축에 타겟값 분포 카운트플롯 그리기
sns.countplot(x=feature, data=df,
order=crosstab[feature].values,
color='skyblue',
ax=ax)
write_percent(ax, len(df)) # 비율 표시
plot_pointplot(ax, feature, crosstab) # 포인트플롯 그리기
ax.set_title(f'{feature} Distribution') # 그래프 제목 설정
nom_features = ['nom_0', 'nom_1', 'nom_2', 'nom_3', 'nom_4'] # 명목형 피처
plot_cat_dist_with_true_ratio(train, nom_features, num_rows=3, num_cols=2)

이 그림에서 카운트플롯은 피처별 고윳값의 비율을 나타낸다.
nom_0 피처의 고윳값은 Blue, Green, Red이며, 차례로 32.1%, 42.4%, 25.5%를 차지한다. 꺽은 선 그래프는 포인트플롯으로, 해당 고윳값 중 타겟값이 1인 비율을 나타낸다. Red 중 타겟값이 1인 데이터는 35% 정도이다. 당연히 Red 중 타겟값이 0인 데이터는 65% 정도일 것이다.
명목형 피처는 순서를 무시해도 되고 고윳값 갯수도 적어 추후 원-핫 인코딩한다.
nom_5부터 num_9 피처는 고유값 개수가 많고 의미 없는 문자로 이루어져 있어 시각화하기 어렵다. 따라서 이 피처들은 시각화 하지 않고 필요한 피처라 가정하고 모델링에 사용한다. 고윳값 갯수는 많지만 피처들의 의미를 몰라 그룹화하기 어렵고, 전체 데이터 양이 많지 않기 때문에 이 피처들 또한 원-핫 인코딩한다.
3.4. 순서형 피처 분포
순서형 피처는 총 6개이며 ord_0 부터 ord_3 까지는 고윳값 개수가 15개 이하인 반면, ord_4 와 ord_5는 고윳값이 많다. 따라서 ord_0부터 ord_3까지는 2행 2열로 그래프를 그리고, ord_4와 ord_5는 2행 1열 그래프로 그린다.
ord_0 ~ ord3 피처 분포 확인
1
2
3
ord_features = ['ord_0', 'ord_1', 'ord_2', 'ord_3'] # 순서형 피처
plot_cat_dist_with_true_ratio(train, ord_features,
num_rows=2, num_cols=2, size=(15, 12))

ord_1 과 ord_2 피처 값들의 순서가 정렬되지 않았다.
ord_1 피처는 ‘Novice’, ‘Contributor’, ‘Expert’, ‘Master’, ‘Grandmaster’ 순으로 정렬하고, ord_2 피처는 ‘Freezing’, ‘Cold’, ‘Hot’, ‘Boiling Hot’, ‘Lava Hot’ 순으로 정렬한다.
CategoricalDtype()을 통해 피처 순서 지정
CategoricalDtype()
- categories : 범주형 데이터 타입으로 인코딩할 값 목록
- ordered : True로 설정하면 categories에 전달한 값의 순서가 유지된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from pandas.api.types import CategoricalDtype
ord_1_value = ['Novice', 'Contributor', 'Expert', 'Master', 'Grandmaster']
ord_2_value = ['Freezing', 'Cold', 'Hot', 'Boiling Hot', 'Lava Hot']
# 순서를 지정한 범주형 데이터 타입
ord_1_dtype = CategoricalDtype(categories=ord_1_value, ordered=True)
ord_2_dtype = CategoricalDtype(categories=ord_2_value, ordered=True)
# 데이터 타입 변경
train['ord_1'] = train['ord_1'].astype(ord_1_dtype)
train['ord_2'] = train['ord_2'].astype(ord_2_dtype)
''' 순서를 지정하게 되면 아래 Categories 항목이 추가됨
Categories (5, object): ['Novice' < 'Contributor' < 'Expert' < 'Master' < 'Grandmaster']
'''
plot_cat_dist_with_true_ratio(train, ord_features, num_rows=2, num_cols=2, size=(15, 12))

ord_0는 순자 크기 순으로, ord_1과 ord_2는 지정된 순서대로, ord_3는 알파벳 순으로 정렬된 것을 확인할 수 있다.
이 결과로 고윳값 순서에 따라 타겟값 1 비율도 비례해서 커진다는 것을 확인할 수 있다.
ord_4, ord_5 피처 분포 확인
ord_4와 ord_5의 분포는 고윳값 개수가 많아 2행 1열로 그린다.
1
plot_cat_dist_with_true_ratio(train, ['ord_4', 'ord_5'], num_rows=2, num_cols=1, size=(15, 12))

ord_5는 고윳값 개수가 많아 x축 라벨이 겹치지만 타겟값 1 비율의 전체적인 양상을 보면 ord_4와 ord_5 모두 고윳값 순서에 따라 타겟값 1 비율이 증가한다.
모든 그래프에서 순서와 비율 사이에 상관관계가 있으므로 순서형 피처는 모두 모델링시 사용한다.
3.5. 날씨 피처 분포
1
2
3
date_feature = ['day', 'month']
plot_cat_dist_with_true_ratio(train, date_feature, num_rows=2, num_cols=1, size=(10, 10))

요일과 월 피처 모두 값이 숫자이다. 머신러닝 모델은 숫자 값을 가치의 크고 작음으로 해석한다. 예를 들어 12월과 다음해 1월, 1월과 2월의 차이는 둘 다 한달 차이이지만 머신러닝 모델은 차이가 같다고 보지 않는다. 이럴 때 삼각함수(sin, cos)를 사용해 인코딩하면 시작과 끝점이 매끄럽게 연결돼 문제가 해결된다. 이렇게 매년, 매월, 매주, 매일 반복되는 데이터를 순환형 데이터(cyclical data)라고 부른다. 계절, 월, 요일, 시간 등이 이에 속한다.
하지만 이번 장에서는 명목형 피처 또한 원-핫 인코딩을 적용한다.
분석 정리 및 모델링 전략
분석 정리
결측값은 없다.
모든 피처가 중요하며 제가할 피처를 찾지 못했다.
이진 피처 인코딩 : 값이 숫자가 아닌 이진 피처는 0과 1로 인코딩한다.
명목형 피처 인코딩 : 전체 데이터가 크지 않으므로 모두 원-핫 인코딩함
순서형 피처 인코딩 : 고윳값들의 순서에 맞게 인코딩한다.(이미 숫자로 되어 있다면 인코딩 필요 없음)
날짜 피처 인코딩 : 값의 크고 작음으로 해석되지 못하도록 원-핫 인코딩
모델링 전략
이번 대회 참가 목표는 데이터 특성에 따른 맞춤형 인코딩 방법을 익히는것이다. 따라서 머신러닝 모델은 기본적인 로지스틱 회귀 모델을 계속 사용하면서 피처 엔지니어링에 집중한다. 그 외 이용할 수 있는 하이퍼파라미터 최적화 등의 성능 개선 방법을 학습한다.
- 베이스라인 모델 : 로지스틱 회귀 모델
- 피처 엔지니어링 : 모든 피처를 원-핫 인코딩
- 성능 개선 : 추가 피처 엔지니어링과 하이퍼파라미터 최적화
- 피처 엔지니어링 : 피처 맞춤 인코딩과 피처 스케일링
- 하이퍼파라미터 최적화 : 그리드 서치
- 추가 팁 : 검증 데이터를 훈련에 이용
4. 베이스라인 모델
베이스라인 모델 전체 프로세스

데이터 로드
1
2
3
4
5
6
7
import pandas as pd
data_path = 'datasets/'
train = pd.read_csv(data_path + 'train.csv', index_col='id')
test = pd.read_csv(data_path + 'test.csv', index_col='id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col='id')
4.1 피처 엔지니어링
데이터 합치기
머신러닝 모델은 문자 데이터를 인식하지 못한다. 따라서 문자를 숫자로 바꿔야한다.
이처럼 데이터의 표현 형태를 바꾸는 작업을 인코딩이라고 한다.
훈련 데이터와 테스트 데이터에 동일한 인코딩을 위해 둘이 합친 다음 DataFrame에서 타겟값을 제거한다.
1
2
3
4
5
6
import pandas as pd
all_data = pd.concat([train, test])
all_data = all_data.drop(['target'], axis=1)
all_data
| bin_0 | bin_1 | bin_2 | bin_3 | bin_4 | nom_0 | nom_1 | nom_2 | nom_3 | nom_4 | ... | nom_8 | nom_9 | ord_0 | ord_1 | ord_2 | ord_3 | ord_4 | ord_5 | day | month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||
| 0 | 0 | 0 | 0 | T | Y | Green | Triangle | Snake | Finland | Bassoon | ... | c389000ab | 2f4cb3d51 | 2 | Grandmaster | Cold | h | D | kr | 2 | 2 |
| 1 | 0 | 1 | 0 | T | Y | Green | Trapezoid | Hamster | Russia | Piano | ... | 4cd920251 | f83c56c21 | 1 | Grandmaster | Hot | a | A | bF | 7 | 8 |
| 2 | 0 | 0 | 0 | F | Y | Blue | Trapezoid | Lion | Russia | Theremin | ... | de9c9f684 | ae6800dd0 | 1 | Expert | Lava Hot | h | R | Jc | 7 | 2 |
| 3 | 0 | 1 | 0 | F | Y | Red | Trapezoid | Snake | Canada | Oboe | ... | 4ade6ab69 | 8270f0d71 | 1 | Grandmaster | Boiling Hot | i | D | kW | 2 | 1 |
| 4 | 0 | 0 | 0 | F | N | Red | Trapezoid | Lion | Canada | Oboe | ... | cb43ab175 | b164b72a7 | 1 | Grandmaster | Freezing | a | R | qP | 7 | 8 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 499995 | 0 | 0 | 0 | F | N | Green | Square | Lion | Canada | Theremin | ... | 9e4b23160 | acc31291f | 1 | Novice | Lava Hot | j | A | Gb | 1 | 3 |
| 499996 | 1 | 0 | 0 | F | Y | Green | Trapezoid | Lion | China | Piano | ... | cfbd87ed0 | eae3446d0 | 1 | Contributor | Lava Hot | f | S | Ed | 2 | 2 |
| 499997 | 0 | 1 | 1 | T | Y | Green | Trapezoid | Lion | Canada | Oboe | ... | 1108bcd6c | 33dd3cf4b | 1 | Novice | Boiling Hot | g | V | TR | 3 | 1 |
| 499998 | 1 | 0 | 0 | T | Y | Blue | Star | Hamster | Costa Rica | Bassoon | ... | 606ac930b | d4cf587dd | 2 | Grandmaster | Boiling Hot | g | X | Ye | 2 | 1 |
| 499999 | 0 | 0 | 0 | T | Y | Green | Star | Lion | India | Piano | ... | 4ea576eb6 | 2d610f52c | 2 | Novice | Freezing | l | J | ex | 2 | 2 |
500000 rows × 23 columns
원-핫 인코딩
문자로 구성된 피처는 모델이 훈련을 할 수 없기 때문에 반드시 인코딩 해야한다. 반면 숫자로 구성된 피처는 반드시 인코딩 할 필요는 없다.
단, 모델 성능을 더 좋게 하기 위해 숫자로 구성된 범주형 피처도 인코딩 하는 경우가 있다.
여기서는 편의상 모든 피처를 인코딩 하며, 모델 성능 개선에서 피처의 특성에 따라 다른 인코딩을 적용한다.
1
2
3
4
5
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder() # 원-핫 인코더 객체 생성
all_data_encoded = encoder.fit_transform(all_data) # 원-핫 인코딩 적용
Train, Test, target 데이터 나누기
훈련 데이터와 테스트 데이터를 다시 분리한다. 여기서는 행 번호를 기준으로 다시 나눌 수 있다.
1
2
3
4
5
6
7
num_train = len(train) # 훈련 데이터 개수
# 훈련 데이터와 테스트 데이터 나누기
X_train = all_data_encoded[:num_train]
X_test = all_data_encoded[num_train:]
y = train['target']
train_test_split 함수를 사용하여 train, val 데이터 분리
검증 데이터를 이용해 제출 전 모델 성능을 평가한다. 이를 통해 어떤걸 수정했을 때 모델 성능이 좋아졌는지 가늠할 수 있다.
1
2
3
4
5
6
7
from sklearn.model_selection import train_test_split
# 훈련 데이터, 검증 데이터 분리
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y,
test_size = 0.1,
stratify=y,
random_state=10)
train_test_split()은 전체 데이터를 훈련 데이터와 검증(혹은 테스트) 데이터로 나누는 함수이다.
첫번째 인수로는 피처(X_train)를, 두번째 인수로는 타겟값(y)을 전달한다.
test_size는 검증 데이터 크기를 지정하는 파라미터이다. 값이 정수면 검증 데이터의 갯수를, 실수면 비율을 의미한다. 여기서는 0.1을 전달했으므로 10%를 검증 데이터로 분리하겠다는 뜻이다.
stratify는 파라미터로 지정한 값을 각 그룹에 공정하게 배분한다. 여기서는 타겟값인 y를 전달했으므로 타겟값이 훈련 데이터와 검증 데이터에 같은 비율로 포함되게끔 나눠준다. stratify 파라미터를 지정하지 않으면 훈련 데이터와 검증 데이터에 타겟값이 불균형하게 분포 될 수 있고, 그렇게 되면 훈련과 검증이 올바르게 이루어지지 않으므로 되도록이면 stratify 파라마미터에 타겟값을 넘겨주는게 바람직하다.

검증 데이터는 대체로 10~20% 정도로 잡는다.

4.2 모델 훈련
로지스틱 회귀 모델 생성 및 훈련
- 최대 에폭: 1000
- 시드값: 42
1
2
3
4
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression(max_iter=1000, random_state=42)
logistic_model.fit(X_train, y_train)
4.3 모델 성능 검증
사이킷런은 타겟값 예측 메서드로 predict()와 predict_proba() 두 가지를 제공한다.
- predict(): 타겟값 자체(0이냐 1이냐)를 예측
- predict_proba(): 타겟값의 확률(0일 확률과 1일 확률)을 예측
predict_proba() 메서드로 타겟값 예측
1
2
3
4
5
6
7
8
9
10
11
logistic_model.predict_proba(X_valid)
''' 출력
array([[0.22992663, 0.77007337],
[0.91391701, 0.08608299],
[0.8251393 , 0.1748607 ],
...,
[0.25365496, 0.74634504],
[0.49236783, 0.50763217],
[0.95856154, 0.04143846]])
'''
첫 번째 열은 타겟값이 0일 확률을 나타내고 두 번째 열은 1일 확률을 나타낸다.
당연히 두 값을 합하면 1이 된다.
predict() 메서드로 타겟값 예측
1
2
3
4
5
logistic_model.predict(X_valid)
''' 출력
array([1, 0, 0, ..., 1, 1, 0])
'''
0 또는 1로 예측한 것을 확인할 수 있다. predict_proba()로 예측한 결과와 비교해보면, 첫 행의 타겟값이 0일 확률은 0.2299이고, 1일 확률은 0.7700이다. 1일 확률이 더 크다.
따라서 predict()는 타겟값을 1로 예측했다. 나머지 행도 마찬가지 이다.
본 대회에서는 타겟값이 1일 ‘확률’ 을 예측해야 한다. 따라서 predict_proba()로 예측한 결과의 두번째 열을 타겟 예측값으로 사용한다.
predict_proba() 메서드로 타겟값이 1일 확률만 추출
1
y_valid_preds = logistic_model.predict_proba(X_valid)[:, 1]
y_valid_preds 변수에는 검증 데이터 타겟값이 1일 확률이 저장된다.
타겟 예측값인 y_valid_preds 와 실제 타겟값인 y_valid를 이용해 ROC AUC 계산
ROC AUC 점수는 사이킷런의 roc_auc_score() 를 통해 구할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
from sklearn.metrics import roc_auc_score
# 검증 데이터 ROC AUC
roc_auc = roc_auc_score(y_valid, y_valid_preds)
print(f'검증 데이터 ROC AUC: {roc_auc:.4f}')
''' 출력
검증 데이터 ROC AUC: 0.7965
'''
ROC AUC
분류(Classification) 문제에서 사용
- ROC Curve는 FPR(False Positive Rate) vs TPR(True Positive Rate) 그래프
AUC는 그 곡선 아래 면적을 말함 (0.5~1 사이)
- 사용:
- 이진 분류(binary classification) 문제에서
- 특히 클래스 불균형(불량:정상=1:100 같은) 상황에서 유용
- 특징:
- 확률 예측이 정확할수록 높은 점수
- 클래스 간 순서(rank) 에 기반 (예측이 1에 가까운 샘플이 실제로 1이냐를 봄)
- 정확도(accuracy)보다 임계값에 덜 민감
Accuracy vs F1 Score vs ROC AUC
| 항목 | Accuracy (정확도) | F1 Score (정밀도+재현율 균형) | ROC AUC (순위 정렬 능력) |
|---|---|---|---|
| 뜻 | 전체 중에서 맞춘 비율 | 중요한 정답(양성)을 얼마나 정확하고 놓치지 않았는지 보는 점수 | 정답이 1일 가능성이 높은 순서를 얼마나 잘 매겼는지 보는 점수 |
| 사용 예시 | 시험에서 몇 문제 맞췄는지 | 암 환자 예측에서 진짜 환자들을 정확하게 찾아내는 능력 | 암 환자일 확률이 높은 사람을 순서대로 줄 세우는 능력 |
| 기준 | 단순히 예측 결과(0 또는 1)가 맞았는지 여부 | 정답이 1일 때 얼마나 잘 맞히고, 얼마나 덜 틀렸는지 | 정답이 1일수록 확률을 더 높게 주었는지 (순위 기준) |
| 목적 | 예측이 얼마나 많이 맞았나 | 중요 클래스(양성)를 정확히 맞추는 게 중요할 때 | 확률 예측을 잘해서, 중요한 걸 먼저 찾는 게 중요할 때 |
| 주의점 | 클래스가 치우쳐 있으면 의미 없음 (예: 전부 0만 예측해도 90%) | 정밀도(Precision), 재현율(Recall) 중 무엇이 낮은지 안 보임 | 실제 정답이 뭔지는 몰라도, 순서만 맞춰도 점수는 높을 수 있음 |
| 언제 유용? | 결과를 그냥 0/1로 쓸 수 있을 때 | 정답이 1인 걸 놓치면 안 되는 경우(의료, 보안 등) | 우선순위만 중요하거나 임계값 정하기 전 모델 비교할 때 |
| 점수 해석 | 1.0 = 전부 맞춤 0.0 = 전부 틀림 | 1.0 = 중요 정답 잘 맞춤 0.0 = 전혀 못 맞춤 | 1.0 = 순서를 완벽히 맞춤 0.5 = 랜덤과 동일 |
예시 상황
예: 100명 중 5명이 암 환자인 데이터를 모델이 예측했다고 가정.
Accuracy = 95%
👉 그냥 전부 “암 아니다”라고 예측해도 95% 맞춘 것처럼 보임 ❌F1 Score = 0.0
👉 실제 암 환자를 하나도 못 맞추면 F1은 0점ROC AUC = 0.5
👉 암 환자에게 높은 확률을 안 줬다면, 랜덤이나 다름없음
4.4 예측 및 결과 제출
테스트 데이터를 활용해 타겟값이 1일 확률을 예측하고, 결과 제출
1
2
3
4
5
6
# 타겟값이 1일 확률 예측
y_preds = logistic_model.predict_proba(X_test)[:, 1]
# 제출 파일 생성
submission['target'] = y_preds
submission.to_csv('submission.csv')
1
!kaggle competitions submit -c cat-in-the-dat -f submission.csv -m "Message"
1
2
100%|██████████████████████████████████████| 5.07M/5.07M [00:02<00:00, 2.28MB/s]
Successfully submitted to Categorical Feature Encoding Challenge

프라이빗 점수는 0.79612, 퍼블릭 점수는 0.80108 이 나온다.
프라이빗 점수는 대화가 종료된 후 전체 테스트 데이터로 평가한 점수이다. 반면 퍼블릭 점수는 대회가 종료되기 전, 테스트 데이터 일부만 사용해 평가한 점수이다.
프라이빗 점수가 최종 점수이며, 퍼블릭 점수는 큰 의미가 없다.
Leaderboard 메뉴에서 확인해보면 프라이빗 점수 기준 상위 52.7%로 그다지 좋지 않은것을 확인할 수 있다.
5. 성능 개선 I
자전거 대여 수요 예측 문제 에서는 베이스라인 모델과 다른 모델을 사용해 더 높은 성능을 얻었지만, 이번 문제에서는 베이스 라인 모델 자체의 성능을 높인다.

성능 향상을 위해 아래 세 가지에 중점을 두어 모델링을 진행한다.
- 피처 맞춤 인코딩
- 피처 스케일링
- 피처간 값의 범위가 다르면 훈련이 안될 수 있기 때문에 피처 간 값의 범위를 일치시킨다.
- 하이퍼파라미터 최적화
데이터 로드
1
2
3
4
5
6
7
import pandas as pd
data_path = 'datasets/'
train = pd.read_csv(data_path + 'train.csv', index_col = 'id')
test = pd.read_csv(data_path + 'test.csv', index_col='id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col='id')
5.1 피처 엔지니어링 I: 피처 맞춤 인코딩
베이스라인 에서는 모든 피처를 일괄적으로 원-핫-인코딩 했지만 피처 특성에 맞게 인코딩하면 성능이 더 좋아질 수 있다.
인코딩은 이진 피처, 순서형 피처, 명목형 피처, 날짜 피처 순으로 진행한다.

데이터 합치기
인코딩 전 훈련 데이터와 테스트 데이터를 합쳐 all_data를 만들고 타겟값은 제거한다.
1
2
3
4
# 훈련 데이터와 테스트 데이터 합치기
all_data = pd.concat([train, test])
all_data = all_data.drop('target', axis=1)
이진 피처 인코딩
bin_0, bin_1, bin_2 피처는 이미 0과 1로만 구성돼 있어 따로 인코딩 하지 않아도 된다. 반면 bin_3과 bin_4 피처는 각각 T와 F, Y와 N이라는 문자로 구성돼 있다. 따라서 각각 1과 0으로 치환한다.
1
2
3
all_data['bin_3'] = all_data['bin_3'].map({'F': 0, 'T': 1})
all_data['bin_4'] = all_data['bin_4'].map({'N': 0, 'Y': 1})
순서형 피처 인코딩1 (ord_1, ord_2)
순서형 피처의 고윳값은 아래와 같다.
ord_0 고윳값: [2 1 3]
ord_1 고윳값: ['Grandmaster' 'Expert' 'Novice' 'Contributor' 'Master']
ord_2 고윳값: ['Cold' 'Hot' 'Lava Hot' 'Boiling Hot' 'Freezing' 'Warm']
ord_3 고윳값 : ['h' 'a' 'i' 'j' 'g' 'e' 'd' 'b' 'k' 'f' 'l' 'n' 'o' 'c' 'm']
ord_4 고윳값 : ['D' 'A' 'R' 'E' 'P' 'K' 'V' 'Q' 'Z' 'L' 'F' 'T' 'U' 'S' 'Y' 'B' 'H' 'J'
'N' 'G' 'W' 'I' 'O' 'C' 'X' 'M']
ord_5 고윳값 : ['kr' 'bF' 'Jc' 'kW' 'qP' 'PZ' 'wy' 'Ed' 'qo' 'CZ' 'qX' 'su' 'dP' 'aP'
'MV' 'oC' 'RL' 'fh' 'gJ' 'Hj' 'TR' 'CL' 'Sc' 'eQ' 'kC' 'qK' 'dh' 'gM'
'Jf' 'fO' 'Eg' 'KZ' 'Vx' 'Fo' 'sV' 'eb' 'YC' 'RG' 'Ye' 'qA' 'lL' 'Qh'
'Bd' 'be' 'hT' 'lF' 'nX' 'kK' 'av' 'uS' 'Jt' 'PA' 'Er' 'Qb' 'od' 'ut'
'Dx' 'Xi' 'on' 'Dc' 'sD' 'rZ' 'Uu' 'sn' 'yc' 'Gb' 'Kq' 'dQ' 'hp' 'kL'
'je' 'CU' 'Fd' 'PQ' 'Bn' 'ex' 'hh' 'ac' 'rp' 'dE' 'oG' 'oK' 'cp' 'mm'
'vK' 'ek' 'dO' 'XI' 'CM' 'Vf' 'aO' 'qv' 'jp' 'Zq' 'Qo' 'DN' 'TZ' 'ke'
'cG' 'tP' 'ud' 'tv' 'aM' 'xy' 'lx' 'To' 'uy' 'ZS' 'vy' 'ZR' 'AP' 'GJ'
'Wv' 'ri' 'qw' 'Xh' 'FI' 'nh' 'KR' 'dB' 'BE' 'Bb' 'mc' 'MC' 'tM' 'NV'
'ih' 'IK' 'Ob' 'RP' 'dN' 'us' 'dZ' 'yN' 'Nf' 'QM' 'jV' 'sY' 'wu' 'SB'
'UO' 'Mx' 'JX' 'Ry' 'Uk' 'uJ' 'LE' 'ps' 'kE' 'MO' 'kw' 'yY' 'zU' 'bJ'
'Kf' 'ck' 'mb' 'Os' 'Ps' 'Ml' 'Ai' 'Wc' 'GD' 'll' 'aF' 'iT' 'cA' 'WE'
'Gx' 'Nk' 'OR' 'Rm' 'BA' 'eG' 'cW' 'jS' 'DH' 'hL' 'Mf' 'Yb' 'Aj' 'oH'
'Zc' 'qJ' 'eg' 'xP' 'vq' 'Id' 'pa' 'ux' 'kU' 'Cl']
ord_0 피처는 이미 숫자로 구성돼 있어 인코딩 하지 않아도 된다.
ord_1 과 ord_2 피처는 순서를 정해서 인코딩 한다.
ord_3부터 ord_5는 알파벳 순서대로 인코딩 해야한다.
1
2
3
4
5
ord1dict = {'Novice':0, 'Contributor':1, 'Expert':2, 'Master':3, 'Grandmaster':4}
ord2dict = {'Freezing': 0, 'Cold':1, 'Warm':2, 'Hot':3, 'Boiling Hot':4, 'Lava Hot': 5}
all_data['ord_1'] = all_data['ord_1'].map(ord1dict)
all_data['ord_2'] = all_data['ord_2'].map(ord2dict)
순서형 피처 인코딩2 (ord_3 ~ ord_5)
OrdinalEncoder의 fit_transform()을 적용해 인코딩 하고, 알파벳 순으로 잘 인코딩 됐는지 확인.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
from sklearn.preprocessing import OrdinalEncoder
ord_345 = ['ord_3', 'ord_4', 'ord_5']
ord_encoder = OrdinalEncoder() # OrdinalEncoder 객체 생성
# ordinal 인코딩 적용
all_data[ord_345] = ord_encoder.fit_transform(all_data[ord_345])
# 피처별 인코딩 순서 출력
for feature, categories in zip(ord_345, ord_encoder.categories_):
print(feature)
print(categories)
all_data[['ord_3', 'ord_4', 'ord_5']]
''' 출력
ord_3
['a' 'b' 'c' 'd' 'e' 'f' 'g' 'h' 'i' 'j' 'k' 'l' 'm' 'n' 'o']
ord_4
['A' 'B' 'C' 'D' 'E' 'F' 'G' 'H' 'I' 'J' 'K' 'L' 'M' 'N' 'O' 'P' 'Q' 'R'
'S' 'T' 'U' 'V' 'W' 'X' 'Y' 'Z']
ord_5
['AP' 'Ai' 'Aj' 'BA' 'BE' 'Bb' 'Bd' 'Bn' 'CL' 'CM' 'CU' 'CZ' 'Cl' 'DH'
'DN' 'Dc' 'Dx' 'Ed' 'Eg' 'Er' 'FI' 'Fd' 'Fo' 'GD' 'GJ' 'Gb' 'Gx' 'Hj'
'IK' 'Id' 'JX' 'Jc' 'Jf' 'Jt' 'KR' 'KZ' 'Kf' 'Kq' 'LE' 'MC' 'MO' 'MV'
'Mf' 'Ml' 'Mx' 'NV' 'Nf' 'Nk' 'OR' 'Ob' 'Os' 'PA' 'PQ' 'PZ' 'Ps' 'QM'
'Qb' 'Qh' 'Qo' 'RG' 'RL' 'RP' 'Rm' 'Ry' 'SB' 'Sc' 'TR' 'TZ' 'To' 'UO'
'Uk' 'Uu' 'Vf' 'Vx' 'WE' 'Wc' 'Wv' 'XI' 'Xh' 'Xi' 'YC' 'Yb' 'Ye' 'ZR'
'ZS' 'Zc' 'Zq' 'aF' 'aM' 'aO' 'aP' 'ac' 'av' 'bF' 'bJ' 'be' 'cA' 'cG'
'cW' 'ck' 'cp' 'dB' 'dE' 'dN' 'dO' 'dP' 'dQ' 'dZ' 'dh' 'eG' 'eQ' 'eb'
'eg' 'ek' 'ex' 'fO' 'fh' 'gJ' 'gM' 'hL' 'hT' 'hh' 'hp' 'iT' 'ih' 'jS'
'jV' 'je' 'jp' 'kC' 'kE' 'kK' 'kL' 'kU' 'kW' 'ke' 'kr' 'kw' 'lF' 'lL'
'll' 'lx' 'mb' 'mc' 'mm' 'nX' 'nh' 'oC' 'oG' 'oH' 'oK' 'od' 'on' 'pa'
'ps' 'qA' 'qJ' 'qK' 'qP' 'qX' 'qo' 'qv' 'qw' 'rZ' 'ri' 'rp' 'sD' 'sV'
'sY' 'sn' 'su' 'tM' 'tP' 'tv' 'uJ' 'uS' 'ud' 'us' 'ut' 'ux' 'uy' 'vK'
'vq' 'vy' 'wu' 'wy' 'xP' 'xy' 'yN' 'yY' 'yc' 'zU']
'''
zip
zip()은 이터러블한 두(또는 그 이상) 변수에서 같은 순서끼리 하나씩 짝지어 튜플로 꺼낼 때 사용
! zip 안쓰면 각각의 변수에 분배 못함
1
2
3
4
5
6
7
8
9
print(list(zip(ord_345, ord_encoder.categories_)))
'''
[('ord_3', array(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o'], dtype=object)),
('ord_4', array(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'], dtype=object)),
('ord_5', array(['AP', 'Ai', 'Aj', 'BA', 'BE', 'Bb', 'Bd', 'Bn', 'CL', 'CM', 'CU', 'CZ', 'Cl', 'DH', 'DN', 'Dc', 'Dx', 'Ed', 'Eg', 'Er', 'FI', 'Fd', 'Fo', 'GD', 'GJ', 'Gb', 'Gx', 'Hj', 'IK', 'Id', 'JX', 'Jc', 'Jf', 'Jt', 'KR', 'KZ', 'Kf', 'Kq', 'LE', 'MC', 'MO', 'MV', 'Mf', 'Ml', 'Mx', 'NV', 'Nf', 'Nk', 'OR', 'Ob', 'Os', 'PA', 'PQ', 'PZ', 'Ps', 'QM', 'Qb', 'Qh', 'Qo', 'RG', 'RL', 'RP', 'Rm', 'Ry', 'SB', 'Sc', 'TR', 'TZ', 'To', 'UO', 'Uk', 'Uu', 'Vf', 'Vx', 'WE', 'Wc', 'Wv', 'XI', 'Xh', 'Xi', 'YC', 'Yb', 'Ye', 'ZR', 'ZS', 'Zc', 'Zq', 'aF', 'aM', 'aO', 'aP', 'ac', 'av', 'bF', 'bJ', 'be', 'cA', 'cG', 'cW', 'ck', 'cp', 'dB', 'dE', 'dN', 'dO', 'dP', 'dQ', 'dZ', 'dh', 'eG', 'eQ', 'eb', 'eg', 'ek', 'ex', 'fO', 'fh', 'gJ', 'gM', 'hL', 'hT', 'hh', 'hp', 'iT', 'ih', 'jS', 'jV', 'je', 'jp', 'kC', 'kE', 'kK', 'kL', 'kU', 'kW', 'ke', 'kr', 'kw', 'lF', 'lL', 'll', 'lx', 'mb', 'mc', 'mm', 'nX', 'nh', 'oC', 'oG', 'oH', 'oK', 'od', 'on', 'pa', 'ps', 'qA', 'qJ', 'qK', 'qP', 'qX', 'qo', 'qv', 'qw', 'rZ', 'ri', 'rp', 'sD', 'sV', 'sY', 'sn', 'su', 'tM', 'tP', 'tv', 'uJ', 'uS', 'ud', 'us', 'ut', 'ux', 'uy', 'vK', 'vq', 'vy', 'wu', 'wy', 'xP', 'xy', 'yN', 'yY', 'yc', 'zU'], dtype=object))]
'''
| ord_3 | ord_4 | ord_5 | |
|---|---|---|---|
| id | |||
| 0 | 7.0 | 3.0 | 136.0 |
| 1 | 0.0 | 0.0 | 93.0 |
| 2 | 7.0 | 17.0 | 31.0 |
| 3 | 8.0 | 3.0 | 134.0 |
| 4 | 0.0 | 17.0 | 158.0 |
| ... | ... | ... | ... |
| 499995 | 9.0 | 0.0 | 25.0 |
| 499996 | 5.0 | 18.0 | 17.0 |
| 499997 | 6.0 | 21.0 | 66.0 |
| 499998 | 6.0 | 23.0 | 82.0 |
| 499999 | 11.0 | 9.0 | 114.0 |
500000 rows × 3 columns
ord_encoder_categories_ 는 어떤 순서로 ordinal 인코딩을 적용했는지 보여준다. 출력 결과 알파벳 순으로 인코딩 된 것을 확인할 수 있다.

알파벳 순으로 인코딩 했기 때문에 a는 0.0, b는 1.0, c는 2.0, d는 3.0 식으로 바뀌었다.
명목형 피처 인코딩
명목형 피처는 순서를 무시해도 되기 때문에 원-핫 인코딩을 적용한다.
명목형 피처를 원-핫 인코딩해 별도 행렬에 저장하고, 이어서 all_data에서 명목형 피처를 삭제한다.
원-핫 인코딩을 하면 열 개수가 늘어나서 all_data에서 바로 인코딩할 수 없기 때문이다.
명목형 피처를 원-핫 인코딩한 결과를 encoded_nom_matrix에 저장한다. 이는 CSR형식의 행렬이다.
1
2
3
4
5
6
7
# ❌ 오류 코드
from sklearn.preprocessing import OneHotEncoder
nom_features = ['nom_' + str(i) for i in range(10)] # 명목형 피처
onehot_encoder = OneHotEncoder()
all_data[nom_features] = onegot_encoder.fit_transform(all_data[nom_features])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# ✅ 정상 실행되는 코드
from sklearn.preprocessing import OneHotEncoder
nom_features = ['nom_' + str(i) for i in range(10)] # 명목형 피처
onehot_encoder = OneHotEncoder()
encoded_nom_matrix = onehot_encoder.fit_transform(all_data[nom_features])
encoded_nom_matrix
''' 출력
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 5000000 stored elements and shape (500000, 16276)>
'''
OneHotEncoder로 원-핫 인코딩을 적용하면 희소 행렬을 CSR형식으로 반환한다.
출력 결과를 보면 원-핫 인코딩된 명목형 피처의 행렬 크기가 (500000 x 16276)이다. 원-핫 인코딩 때문에 열이 16,276개나 생성된 것이다.
| 피처 | 데이터 타입 | 결측값 개수 | 고윳값 개수 | 첫 번째 값 | 두 번째 값 | 세 번째 값 | |
|---|---|---|---|---|---|---|---|
| 0 | nom_0 | object | 0 | 3 | Green | Green | Blue |
| 1 | nom_1 | object | 0 | 6 | Triangle | Trapezoid | Trapezoid |
| 2 | nom_2 | object | 0 | 6 | Snake | Hamster | Lion |
| 3 | nom_3 | object | 0 | 6 | Finland | Russia | Russia |
| 4 | nom_4 | object | 0 | 4 | Bassoon | Piano | Theremin |
| 5 | nom_5 | object | 0 | 222 | 50f116bcf | b3b4d25d0 | 3263bdce5 |
| 6 | nom_6 | object | 0 | 522 | 3ac1b8814 | fbcb50fc1 | 0922e3cb8 |
| 7 | nom_7 | object | 0 | 1220 | 68f6ad3e9 | 3b6dd5612 | a6a36f527 |
| 8 | nom_8 | object | 0 | 2215 | c389000ab | 4cd920251 | de9c9f684 |
| 9 | nom_9 | object | 0 | 11981 | 2f4cb3d51 | f83c56c21 | ae6800dd0 |
피처 3개(nom_0, nom_1, nom_2) 가 있고, 각각 고윳값이 다를 때 묶어서 인코딩한 경우
샘플 데이터
1
2
3
4
5
6
7
import pandas as pd
data = pd.DataFrame({
'nom_0': ['Red', 'Green', 'Blue'],
'nom_1': ['Circle', 'Square', 'Triangle'],
'nom_2': ['Dog', 'Cat', 'Bird']
})
묶어서 인코딩
모든 값을 하나의 열로 보고, 전체에서 고윳값 9개를 뽑고 인코딩됨 → 피처 구분 없이 단일 벡터로 바뀜
| Red | Green | Blue | Circle | Square | Triangle | Dog | Cat | Bird |
|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
피처가 6개 늘어난 게 아닌 3개가 9개로 확장
| 개념 | 설명 |
|---|---|
| 원래 피처 | 모델이 이해 못함 (텍스트) |
| 원핫 인코딩 후 | 모델이 이해할 수 있는 수치 피처로 변환 |
| 의미상 변화 | 피처가 “추가”된 게 아니라 “확장/변환” |
- 원래 피처 3개는 범주형(categorical)
- 예: Red, Green, Blue → 머신러닝 모델이 직접 이해할 수 없다.
- 원핫 인코딩은 그 3개를 각각 숫자형 벡터로 바꿔서 모델이 이해할 수 있게 해주는 전처리
- 즉, 3개의 “비교 불가능한 단어 피처” → 9개의 “비교 가능한 수치 피처”로 변환된 것
| 구분 | 피처 수 |
|---|---|
| 인코딩 전 | 3개 (nom_0, nom_1, nom_2) |
| 인코딩 후 | 9개 (각 카테고리 고윳값 수의 합) |
| 최종 | 피처 수는 9개 |
→ 기존 피처는 수치화(확장)되면서 대체
희소 행렬과 COO, CSR 형식
대부분 값이 0으로 채워진 행렬을 희소 행렬(sparse matrix)라고 한다. 반대로 대부분 값이 0이 아닌 값으로 채워진 행렬을 밀집 행렬(dense matrix)라고 한다. 원-핫 인코딩을 적용하면 희소 행렬을 만든다. (메모리 낭비 + 연산 시간 증가) 이런 문제를 개선하기 위해 COO (Coordinate list)형식과 CSR(Compressed sparse row)형식이 있다. 희소 헹렬을 COO형식이나 CSR 형식으로 표현하면 메모리 낭비를 줄일 수 있다. 이중에서도 CSR형식이 메모리를 더 적게 쓰면서 연산도 빠르다. 그래서 일반적으로 COO 형식보다 CSR형식을 많이 사용한다.
all_data에서 기존 명목형 피처 삭제
all_data에서 기존 명목형 피처를 삭제한다. 추 후 encoded_nom_matrix와 all_data를 합칠 때 하나의 피처가 형식만 다르게 중복되어 들어가기 때문이다.
1
all_data = all_data.drop(nom_features, axis=1) # 기존 명목형 피처 삭제
날짜 피처 인코딩
day와 month는 날짜 피처이며 이 피처 또한 원-핫 인코딩을 적용한다.
1
2
3
4
5
6
7
8
9
10
11
12
date_features = ['day', 'month'] # 날짜 피처
# 원-핫 인코딩 적용
encoded_date_matrix = onehot_encoder.fit_transform(all_data[date_features])
all_data = all_data.drop(date_features, axis=1)
encoded_date_matrix
''' 출력
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 1000000 stored elements and shape (500000, 19)>
'''
원-핫 인코딩된 행렬 크기는(500000x 19)이다. day 피처 고윳값 7개, month피처 고윳값 12개라서 인코딩 후 열이 총 19개가 된다.
5.2 피처 엔지니어링 II: 피처 스케일링
피처 스케일링 이란 서로 다른 피처들의 값의 범위가 일치하도록 조정하는 작업이다. 수치형 피처들의 유효 값 범위가 서로 다르면 훈련이 제대로 안될 수도 있기 떄문이다.
이진, 명목형, 날짜 피처를 모두 0과 1로 인코딩 했다. 하지만 순서형 피처는 여전히 여러 값을 갖고 있으므로 순서형 피처의 값 범위도 0~1 사이가 되도록 스케일링 한다.
순서형 피처 스케일링
다른 피처들과 범위를 맞추기 위해 순서형 피처에 min-max 정규화를 적용한다. min-max 정규화는 피처 값의 범위를 0~1로 조정한다.
\[x_{scaled} = {x - x_{min} \over x_{max} - x_{min}}\]2.3 데이터 정규화 참고
1
2
3
4
5
6
from sklearn.preprocessing import MinMaxScaler
ord_features = ['ord_' + str(i) for i in range(6)] # 순서형 피처
# min-max 정규화
all_data[ord_features] = MinMaxScaler().fit_transform(all_data[ord_features])
모든 피처의 값 범위가 0 ~ 1로 맞춰졌다. 다음 표는 피쳐 스케일링에 따른 순서형 피처 값 변화를 보여준다.

인코딩 및 스케일링된 피처 합치기
현재 all_data 에는 이진 피처와 순서형 피처가 인코딩돼 있다. 명목형 피처와 날짜 피처는 원-핫 인코딩되어 각각 encoded_nom_matrix와 encoded_data_matrix에 저장돼 있다.
all_data는 DataFrame이고 encoded_nom_matrix와 encoded_date_matrix는 CSR 형식의 행렬이다. 따라서 all_data를 CSR형식으로 만들어 합친다.
crs_matrix()는 전달받은 데이터를 csr형식으로 바꿔준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from scipy import sparse
# 인코딩 및 스케일링된 피처 합치기
all_data_sprs = sparse.hstack([sparse.csr_matrix(all_data),
encoded_nom_matrix,
encoded_date_matrix],
format='csr')
all_data_sprs
''' 출력
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 9163718 stored elements and shape (500000, 16306)>
'''
hstack()은 행렬을 수평 방향으로 합친다. format=’csr’을 전달하면 합친 결과를 csr 형식으로 반환한다.(기본값 COO)
all_data_sprs 는 500,000행 16,306열로 되어있다. 이 크기를 DataFrame으로 처리하면 메모리 낭비가 심하고 훈련 속도도 떨어진다. 따라서 DataFrame 으로 변환하지 않고, CSR형식을 그대로 사용한다.
데이터 나누기
훈련데이터와 테스트 데이터로 나눈다.
1
2
3
4
5
6
7
num_train = len(train) # 훈련 데이터 갯수
# 훈련 데이터와 테스트 데이터 나누기
X_train = all_data_sprs[:num_train] # 0~num_train - 1행
X_test = all_data_sprs[num_train:] # num_train ~ 마지막 행
y = train['target']
베이스라인과 마찬가지로 훈련 데이터를 다시 훈련 데이터와 검증 데이터로 나눈다.
1
2
3
4
5
6
7
from sklearn.model_selection import train_test_split
# 훈련 데이터, 검증 데이터 분리
X_train_splited, X_valid, y_train_splited, y_valid = train_test_split(X_train, y,
test_size=0.1,
stratify=y,
random_state=10)
5.3 하이퍼파라미터 최적화
최종 데이터를 활용해 모델을 훈련하고 결과를 제출한다. 이 과정에서 베이스라인 모델과 달리 하이퍼파라미터를 최적화 한다. 그리드 서치를 활용해 로지스틱 회귀 모델의 하이퍼파라미터를 최적화한다. 탐색할 하이퍼파라미터는 C와 max_iter이다. C는 규제 강도를 조절하는 파라미터로, 값이 작을수록 규제 강도가 세진다.
로지스틱 회귀는 선형 회귀 방식을 응용해 분류 문제에 적용한 모델이다. (훈련 원리는 선형 회귀 모델과 유사)
모델을 생성하고 평가지표를 ROC AUC로 지정해 그리드서치를 수행
C: 규제(Regularization) 강도 조절
→ 값이 작을수록 규제가 강해짐
→ 값이 클수록 규제가 약해짐
ex)
- C = 0.01: 강한 규제 → 단순 모델 → 과소적합 위험
- C = 10: 약한 규제 → 복잡 모델 → 과적합 위험
solver: 최적화 알고리즘
(Adam, RMSProp처럼 모델 파라미터를 학습시키는 방식 지정 — 다만 전통 ML 방식)
| solver 이름 | 특징 |
|---|---|
'liblinear' | 작은 데이터셋에 적합, L1/L2 규제 모두 가능 |
'lbfgs' | 대용량 데이터에 적합, L2 규제만 지원 |
'newton-cg' | L2 규제만 지원, 고차원 데이터에 적합 |
'saga' | 대규모 데이터, 희소(sparse) 데이터, L1/L2 모두 지원 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
%%time # 해당 셀 실행 후 소요 시간을 출력해주는 기능
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression()
lr_params = {'C':[0.1, 0.125, 0.2], 'max_iter':[800, 900, 1000],
'solver':['liblinear'], 'random_state':[42]}
gridsearch_logistic_model = GridSearchCV(estimator=logistic_model,
param_grid=lr_params,
scoring='roc_auc',
cv=5)
gridsearch_logistic_model.fit(X_train_splited, y_train_splited)
print('최적 하이퍼파라미터: ', gridsearch_logistic_model.best_params_)
''' 출력
최적 하이퍼파라미터: {'C': 0.125, 'max_iter': 800, 'random_state': 42, 'solver': 'liblinear'}
CPU times: user 1min 22s, sys: 1.48 s, total: 1min 24s
Wall time: 1min 25s
'''
5.4 모델 성능 검증
베이스라인과 동일하게 검증 데이터로 모델 성능을 검증한다.
검증 데이터로 타겟 예측값을 구한다.
1
y_valid_preds = gridsearch_logistic_model.predict_proba(X_valid)[:, 1]
검증 데이터 ROC AUC 계산
1
2
3
4
5
6
7
8
9
10
11
from sklearn.metrics import roc_auc_score # ROC AUC 점수 계산 함수
# 검증 데이터 ROC AUC
roc_auc = roc_auc_score(y_valid, y_valid_preds)
print(f'검증 데이터 ROC AUC: {roc_auc:.4f}')
''' 출력
검증 데이터 ROC AUC: 0.8045
'''
5.5 예측 및 결과 제출
제출 파일을 만들어 제출
1
2
3
4
5
6
# 타겟값 1일 확률 예측
y_preds = gridsearch_logistic_model.best_estimator_.predict_proba(X_test)[:, 1]
# 제출 파일 생성
submission['target'] = y_preds
submission.to_csv('submission.csv')
1
! kaggle competitions submit -c cat-in-the-dat -f submission.csv -m "개별 encoding"

베이스라인 모델보다 점수가 높지만 프라이빗 점수 기준으로 전체 428등으로 상위 32%이다.
6. 성능 개선 II
앞서 모델 훈련 시 전체 훈련 데이터를 9:1 비율로 훈련 데이터와 검증 데이터로 나누었다. 훈련 데이터는 훈련용으로만 사용하고, 검증데이터는 모델 성능 검증용으로만 사용했다.

검증 데이터는 전체 훈련 데이터의 10%를 차지한다. 따라서 지금까지 다룬 모델링 절차를 그대로 유지한 채로 훈련 데이터 전체를 사용해 모델을 훈련한다. train_test_split() 으로 훈련 데이터(90%)와 검증 데이터(10%)로 나누는 부분과 연관된 코드를 제외하고 나머지 모든 절차는 동일하게 수행한다.
훈련 데이터가 달라지면 그에 따라 최적 하이퍼파라미터도 달라질 수 있다. 훈련 데이터 90%를 사용해 구한 최적 하이퍼파라미터가 훈련 데이터 100%를 사용할 때도 최적이라는 보장은 없다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
%%time
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression()
lr_params = {'C':[0.1, 0.125, 0.2], 'max_iter':[800, 900, 1000],
'solver':['liblinear'], 'random_state':[42]}
gridsearch_logistic_model = GridSearchCV(estimator=logistic_model,
param_grid=lr_params,
scoring='roc_auc',
cv=5)
gridsearch_logistic_model.fit(X_train, y)
print('최적 하이퍼파라미터: ', gridsearch_logistic_model.best_params_)
''' 출력
최적 하이퍼파라미터: {'C': 0.125, 'max_iter': 800, 'random_state': 42, 'solver': 'liblinear'}
CPU times: user 1min 30s, sys: 1.44 s, total: 1min 31s
Wall time: 1min 32s
'''
1
y_train_preds = gridsearch_logistic_model.predict_proba(X_train)[:, 1]
1
2
3
4
5
6
7
8
9
10
from sklearn.metrics import roc_auc_score # ROC AUC 점수 계산 함수
# 검증 데이터 ROC AUC
roc_auc = roc_auc_score(y, y_train_preds)
print(f'검증 데이터 ROC AUC: {roc_auc:.4f}')
''' 출력
검증 데이터 ROC AUC: 0.8276
'''
1
2
3
4
5
6
# 타겟값 1일 확률 예측
y_preds = gridsearch_logistic_model.best_estimator_.predict_proba(X_test)[:, 1]
# 제출 파일 생성
submission['target'] = y_preds
submission.to_csv('submission.csv')
1
! kaggle competitions submit -c cat-in-the-dat -f submission.csv -m "validation 통합"

프라이빗 점수가 0.80282이다. 90%의 훈련 데이터만으로 모델링했을 때 (0.80220) 보다 0.0062 만큼 향상되었다.
더 일반적인 흐름
이번엔 하나의 머신러닝 모델(로지스틱 회귀 모델)을 계속 사용했지만, 일반적으로는 여러 가지 방법으로 모델링해서, 그중 검증 데이터 성능이 가장 높은 모델을 제출용으로 사용한다.
제출용 모델을 선정했다면, 선정된 모델을 ‘검증 데이터 까지 포함한 전체 훈련 데이터로 다시 훈련’ 하여 그 결과를 최종 제출 데이터로 사용한다는 것이 이번 학습의 요지이다.
아래 그림은 세 가지 모델 A, B, C 중 B의 검증 성능이 가장 좋았을 때의 시나리오를 보여준다.

핵심 요약
피처 요약표 는 피처별 데이터 타입, 결측값 개수, 고윳값 개수, 실제 입력 등을 정리한 표이다.
타겟값 분포 를 알면 데이터가 얼마나 불균형한지 파악하여 부족한 타겟값에 더 집중해 모델링을 수행할 수 있다.
- 피처별로 데이터 특성에 알맞게 인코딩 해줘야 모델 성능을 효과적으로 끌어올릴 수 있다.
- 이진 피처 : 값이 0과 1이 아닌 경우 0과 1로 인코딩한다.
- 명목형 피처 : 고윳값 개수가 너무 많지 않다면 머신러닝 모델이 이해할 수 있도록 원-핫 인코딩을 적용한다.
- 순서형 피처 : 고윳값들의 순서에 맞게 인코딩한다.
- 날짜 피처 : 순환형 데이터는 삼각함수를 사용해 인코딩하거나 원-핫 인코딩을 적용한다.
로지스틱 회귀 는 선형 회귀 방식을 응용해 분류 문제에 적용한 모델이다. 훈련 원리는 선형 회귀 모델과 유사하다.
- 피처 스케일링 이란 피처 간 값의 범위를 일치시키는 작업이다. 피처마다 값의 범위가 다르면 훈련이 제대로 안될 수 있으므로 범위 차이가 심한 피처들은 스케일링하여 비슷하게 맞춰줘야 한다.