2.4 교차 검증
2.4 교차 검증
일반적으로 훈련 데이터로 모델을 훈련하고, 테스트 데이터로 예측해 모델 성능을 측정한다. 모델을 훈련만 하고, 성능을 검증해보지 않으면 두 가지 문제가 발생할 수 있다.
- 모델이 과대적합될 가능성이 있다.
- 고정된 훈련 데이터만을 활용해 반복해서 훈련하면 모델이 훈련 데이터에만 과대적합될 가능성이 있다.
- 모델 성능을 확인하기 어렵다.
- 전체 데이터를 훈련 데이터와 검증 데이터로 나눈 뒤, 검증 데이터로 성능을 가늠해볼 수 있지만 그럴 경우 검증 데이터는 훈련에 사용하지 못해 손해이다. 실무에서도 마찬가지로 아직 주어지지 않은 미래 데이터로 미리 테스트해볼 수 없다. 즉 실제 서비스에 적용하기 전에는 모델 성능을 가늠해볼 수 없다.
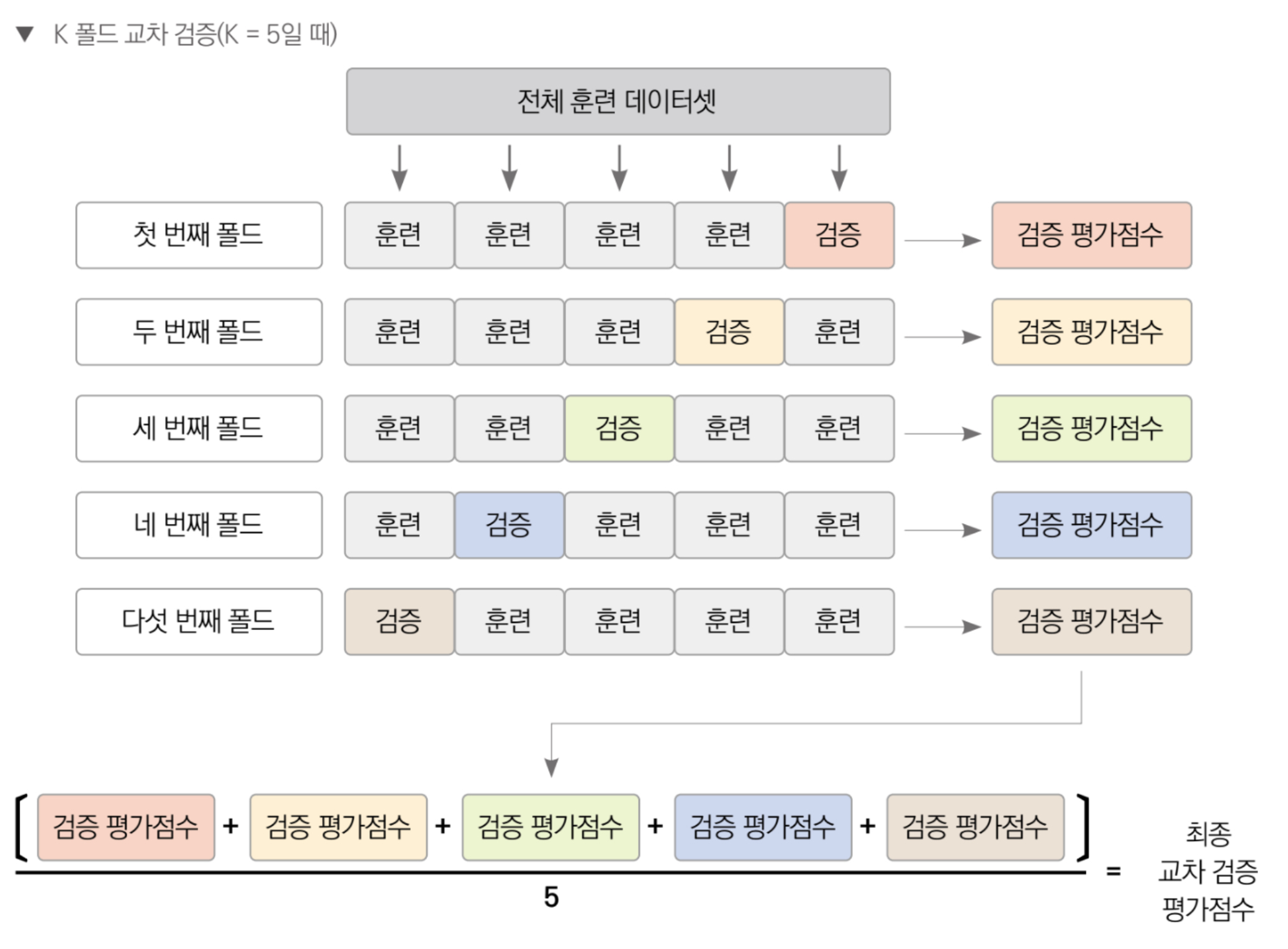
이상의 두 문제를 개선하기 위한 방법이 교차 검증이다. 교차 검증은 훈련 데이터를 여러 그룹으로 나누어 일부는 훈련 시 사용하고, 일부는 검증 시 사용해서 모델 성능을 측정하는 기법이다. 가장 일반적인 교차 검증 기법은 K 폴드 교차 검증이다.
1. K 폴드 교차 검증 (K-Fold Cross Validation)
K 폴드 교차 검증 절차는 다음과 같다.
전체 훈련 데이터를 K개 그룹으로 나눈다.
그룹 하나는 검증 데이터로, 나머지 K - 1개는 훈련 데이터로 지정한다.
훈련 데이터로 모델을 훈련하고, 검증 데이터로 평가한다.
평가점수를 기록한다.
검증 데이터를 다른 그룹으로 바꿔가며 2~4 절차를 K번 반복한다.
K개 검증 평가점수의 평균을 구한다.
K개 검증 평가점수의 평균이 최종 평가점수이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import numpy as np
from sklearn.model_selection import KFold
data = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
folds = KFold(n_split = 5, shuffle = False)
for train_idx, valid_idx in folds.split(data):
print(f'훈련 데이터: {data[train_idx]}, 검증 데이터: {data[valid_idx]}')
'''
훈련 데이터: [2 3 4 5 6 7 8 9], 검증 데이터: [0 1]
훈련 데이터: [0 1 4 5 6 7 8 9], 검증 데이터: [2 3]
훈련 데이터: [0 1 2 3 6 7 8 9], 검증 데이터: [4 5]
훈련 데이터: [0 1 2 3 4 5 8 9], 검증 데이터: [6 7]
훈련 데이터: [0 1 2 3 4 5 6 7], 검증 데이터: [8 9]
'''
KFold() 는 데이터를 K 폴드로 나누는 함수이다. n_splits 파라미터에 전달하는 값이 K값이다.
여기서는 5로 설정하여 데이터가 총 5개로 나뉜다. 폴드가 5개이므로 검증 데이터는 [0, 1], [2, 3], [4, 5], [6, 7], [8, 9]가 된다.
데이터가 편향되게 분포되어 있을 수도 있기 떄문에 폴드로 나누기 전에 데이터를 섞어주는게 좋다. shuffle 파라미터에 True를 전달하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
folds = KFold(n_split = 5, shuffle = True)
for train_idx, valid_idx in folds.split(data):
print(f'훈련 데이터: {data[train_idx]}, 검증 데이터: {data[valid_idx]}')
'''
훈련 데이터: [0 3 4 5 6 7 8 9], 검증 데이터: [1 2]
훈련 데이터: [0 1 2 3 5 6 7 9], 검증 데이터: [4 8]
훈련 데이터: [1 2 3 4 5 6 7 8], 검증 데이터: [0 9]
훈련 데이터: [0 1 2 3 4 7 8 9], 검증 데이터: [5 6]
훈련 데이터: [0 1 2 4 5 6 8 9], 검증 데이터: [3 7]
'''
2. 층화 K 폴드 교차 검증 (Stratified K-Fold Cross Validation)
층화 K 폴드 교차 검증은 타겟값이 골고루 분포되게 폴드를 나누는 K폴드 교차 검증 방법이다. 타겟값이 불균형하게 분포되어 있는 경우 층화 K 폴드를 사용하는게 좋다.
일반 메일과 스팸 메일을 분류하는 문제를 생각해보자. 받은 메일이 1,000개인데, 그중 스팸은 단 10개라고 가정해보면 스팸이 10개밖에 안되므로 K 폴드 교차 검증을 해도 특정 폴드에는 스팸이 아예 없을 수 있다. 스팸 데이터 없이 모델을 훈련하면 스팸 예측을 제대로 하지 못하게 된다.
이처럼 특정 타겟값이 다른 타겟값 보다 굉장히 작은 경우 주로 층화 K 폴드 교차 검증을 사용한다. 이 방식은 스팸 데이터를 모든 폴드에 균일하게 나누어 준다. 즉, 폴드가 5개면 각 폴드에 스팸 데이터를 2개씩 골고루 분배해서 교차 검증을 수행한다.
층화 K 폴드 교차 검증은 분류 문제에만 쓰인다. 회귀 문제의 타겟값은 연속된 값이기 때문에 폴드마다 균등한 비율로 나누는 게 불가능하기 때문이다.
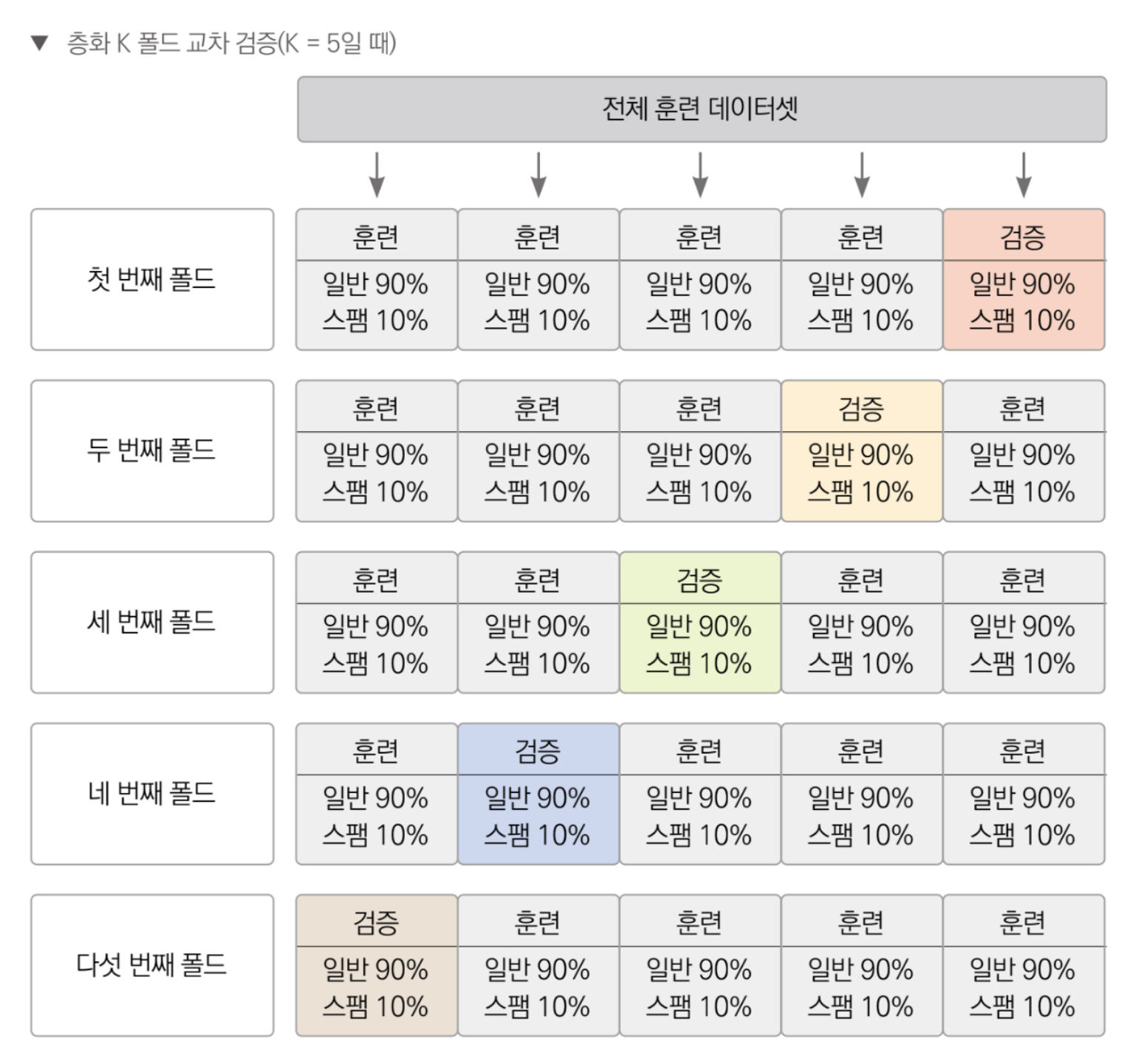
아래 코드는 일반 메일 45개 스팸 메일 5인 데이터를 K 폴드로 나눈 코드이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import numpy as np
from sklearn.model_selection import KFlod
y = np.array(['스팸'] * 5 + ['일반'] * 45)
folds = KFold(n_splits = 5, shuffle = True)
for idx, (train_idx, valid_idx) in enumerate(folds.split(y)):
print(f'Fold {idx + 1} 검증 데이터 타겟값: ')
print(y[valid_idx], '\n')
'''
Fold 1 검증 데이터 타겟값:
['스팸' '스팸' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반']
Fold 2 검증 데이터 타겟값:
['스팸' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반']
Fold 3 검증 데이터 타겟값:
['스팸' '스팸' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반']
Fold 4 검증 데이터 타겟값:
['일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반']
Fold 5 검증 데이터 타겟값:
['일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반']
'''
결과를 보면 검증 데이터 타겟값에 스팸이 없는 폴드가 있다. 이러면 학습이 제대로 되었는지 판단하기 어렵다. 따라서 모든 폴드에 스팸 데이터가 있게 하려면 층화 K 폴드를 사용하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from sklearn.model_selection import StratifiedKFold
X = np.array(range(50))
y = np.array(['스팸'] * 5 + ['일반'] * 45)
folds = StratifiedKFold(n_splits = 5)
for idx, (train_idx, val_idx) in enumerate(folds.split(X, y)):
print(f'Fold {idx + 1} 검증 데이터 타겟값: ')
print(y[val_idx], '\n')
'''
Fold 1 검증 데이터 타겟값:
['스팸' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반']
Fold 2 검증 데이터 타겟값:
['스팸' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반']
Fold 3 검증 데이터 타겟값:
['스팸' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반']
Fold 4 검증 데이터 타겟값:
['스팸' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반']
Fold 5 검증 데이터 타겟값:
['스팸' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반' '일반']
'''
층화 K 폴드 방식은 모든 폴드에 스팸이 1개씩 포함되어 있는것을 확인할 수 있다.
[!] KFold의 split()에는 데이터 하나만 전달해도 된다. 데이터 불균형 여부와 상관없이 임의로 K개로 분할하기 때문이다. 반면 StratifiedKFold의 split() 함수에는 피처와 타겟값 모두를 전달해야 한다.