1. 자전거 대여 수요 예측
1. 자전거 대여 수요 예측
| 난이도 | 1 | |||
|---|---|---|---|---|
| 경진대회명 | 자전거 대여 수요 예측 경진대회 | |||
| 미션 | 날씨, 계절, 근무일 여부, 날씨, 온도, 체감 온도, 풍속 데이터를 활용하여 자전거 대여 수량 예측 | |||
| 문제유형 | 회귀 | 평가지표 | RMSLE | |
| 제출시 사용한 모델 | 랜덤 포레스트 회귀 | |||
| 파이썬 버전 | 3.7.1 | |||
| 사용 라이브러리 버전 | numpy == 1.19.5 pandas == 1.3.2 seaborn == 0.11.2 matplotlib == 3.4.3 sklearn == 0.32. 2 datetime, calendar |
학습 목표
- 머신러닝 모델링 프로세스와 기본적인 회귀 모델들을 학습.
- 캐글 코드를 활용해 데이터가 어떻게 구성되어 있는지 살펴보고, 그래프로 데이터 시작화.
- 간단한 회귀 모델을 훈련/평가하는 방법 학습.
- 최종적으로 훈련된 모델로 예특한 결과 제출 후 순위 확인
학습 순서
- 경진대회 이해
- 캐글 세부 메뉴 소개
- 탐색적 데이터 분석
- 베이스라인 모델(선형회귀)
- 성능개선 I (릿지 회귀)
- 성능 개선 II (라쏘 회귀)
- 성능 개선 III (랜덤 포레스트 회귀)
학습 키워드
- 유형 및 평가 지표 : 회귀, RMSLE
- 탐색적 데이터 분석 : 분포도, 막대그래프, 박스플롯, 포인트플롯, 산점도, 히트맵
- 머신러닝 모델 : 선형회귀, 릿지 회귀, 라쏘 회귀, 랜덤 포레스트 회귀
- 피처 앤지니어링 : 파생 피처 추가, 피처 제거
- 하이퍼파라미터 최적화 : 그리드 서치
1. 경진대회 이해
주어진 데이터는 2년간의 자전거 대여 데이터이다. 대여 데이터는 한 시간 간격으로 기록되어 있다.
그 중 훈련 데이터는 매달 1일부터 19일까지의 기록이고, 테스트 데이터는 메달 20일부터 월말까지의 기록이다.
피치는 대여 날짜, 시간, 요일, 계절, 날씨, 실제 온도, 체감 온도, 습도, 풍속, 회원 여부이다.
위 데이터들을 활용해 시간별 자전거 대여 수량을 예측하면 된다. 예측할 값이 범주형 데이터가 아니므로 본 대회는 회귀 문제에 속한다.
피처와 타겟값이란?
머신러닝에서 feature는 원하는 값을 예측하기 위해 활용하는 데이터를 의미하며 target 값은 예측해야 할 값이다.
대여 날짜, 시간, 요일, 계절, 날씨, 온도를 활용하여 대여 수량을 예측하는 문제를 생각해보자. 여기서 피처는 대여 날짜, 시간, 요일, 계절, 날씨, 온도 이다.
target값은 대여 수량이다. 다른 말로 feature는 독립변수이고, target값은 종속변수이다.
2. 탐색적 데이터 분석
문제를 푸려면 우선 주어진 데이터를 면밀히 살펴서 어느 데이터가 예측에 도움될지, 혹은 되지 않을지를 파악해야 한다.
이를 파악하는 단계가 탐색적 데이터 분석이다.
이 분석 과정은 아래와 같은 순서로 진행된다.
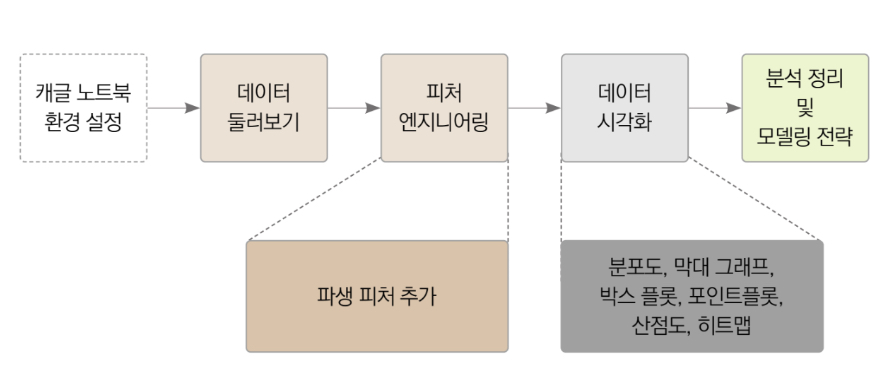
2.1 탐색적 데이터 분석
kaggle competitions download -c bike-sharing-demand
데이터 로드 및 shape 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import numpy as np
import pandas as pd
data_path = 'datasets/'
train = pd.read_csv(data_path + 'train.csv')
test = pd.read_csv(data_path + 'test.csv')
subission = pd.read_csv(data_path + 'sampleSubmission.csv')
train.shape, test.shape
'''
((10886, 12), (6493, 9))
'''
train, test, submission의 첫 5행 출력
| 피처명 | 설명 |
|---|---|
| datetime | 기록 일시 (1시간 간격) |
| season | 계절 (1: 봄, 2: 여름, 3: 가을, 4: 겨울) |
| holiday | 공휴일 여부(0: 공휴일 아님, 1: 공휴일) |
| workingday | 근무일 여부 (0: 근무일 아님, 1: 근무일) * 주말과 공휴일이 아니면 근무일이라고 간주 |
| weather | 날씨(1: 맑음, 2: 옅은 안개, 약간 흐림, 3 : 약간 눈, 약간의 비와 천둥 번개, 흐림, 4: 폭우와 천둥 번개, 눈과 짙은 안개) * 숫자가 클수록 날씨 안좋음 |
| temp | 실제 온도 |
| atemp | 체감 온도 |
| humidity | 상대 습도 |
| windspeed | 풍속 |
| casual | 등록되지 않은 사용자(비회원) 수 |
| registered | 등록된 사용자(회원) 수 |
| count | 자전거 대여 수량 |
1
train.head()
| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 3 | 10 | 13 |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 0 | 1 | 1 |
1
test.head()
| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-20 00:00:00 | 1 | 0 | 1 | 1 | 10.66 | 11.365 | 56 | 26.0027 |
| 1 | 2011-01-20 01:00:00 | 1 | 0 | 1 | 1 | 10.66 | 13.635 | 56 | 0.0000 |
| 2 | 2011-01-20 02:00:00 | 1 | 0 | 1 | 1 | 10.66 | 13.635 | 56 | 0.0000 |
| 3 | 2011-01-20 03:00:00 | 1 | 0 | 1 | 1 | 10.66 | 12.880 | 56 | 11.0014 |
| 4 | 2011-01-20 04:00:00 | 1 | 0 | 1 | 1 | 10.66 | 12.880 | 56 | 11.0014 |
1
submission.head()
| datetime | count | |
|---|---|---|
| 0 | 2011-01-20 00:00:00 | 0 |
| 1 | 2011-01-20 01:00:00 | 0 |
| 2 | 2011-01-20 02:00:00 | 0 |
| 3 | 2011-01-20 03:00:00 | 0 |
| 4 | 2011-01-20 04:00:00 | 0 |
- datetime부터 registered 까지는 예측에 사용할 수 있는 feature
- count는 예측해야 할 target값
- datetime은 한시간 간격으로 기록되어 있음
- 결국 예측해야 할 값은 시간당 총 자전거 대여 수량
- test 데이터에는 casual과 registered 가 빠져있으므로 훈련시에도 두 feature는 제외
train, test 데이터셋에 각 열의 결측값과 데이터 타입 파악
1
train.info()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10886 entries, 0 to 10885
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 10886 non-null object
1 season 10886 non-null int64
2 holiday 10886 non-null int64
3 workingday 10886 non-null int64
4 weather 10886 non-null int64
5 temp 10886 non-null float64
6 atemp 10886 non-null float64
7 humidity 10886 non-null int64
8 windspeed 10886 non-null float64
9 casual 10886 non-null int64
10 registered 10886 non-null int64
11 count 10886 non-null int64
dtypes: float64(3), int64(8), object(1)
memory usage: 1020.7+ KB
1
test.info()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6493 entries, 0 to 6492
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 6493 non-null object
1 season 6493 non-null int64
2 holiday 6493 non-null int64
3 workingday 6493 non-null int64
4 weather 6493 non-null int64
5 temp 6493 non-null float64
6 atemp 6493 non-null float64
7 humidity 6493 non-null int64
8 windspeed 6493 non-null float64
dtypes: float64(3), int64(5), object(1)
memory usage: 456.7+ KB
- 모든 feature의 비결측값 데이터 갯수 (Non-Null Count)가 전체 데이터 개수와 똑같은 10,886개 이므로 훈련 데이터에는 결측값이 없다.
- 테스트 데이터 또한 결측값이 없고, 데이터 타입도 훈련 데이터와 동일하다
결측값은 해당 피처의 평균값, 중앙값, 최빈값으로 대체하거나 결측값을 포함하는 피처를 아예 제거하는 방법이 있다. 또는 결측값을 target값으로 간주하고, 다른 feature를 활용해 결측값을 예측할 수도 있다.
3. 효과적인 분석을 위한 피처 엔지니어링
일부 데이터는 시각화하기에 적합하지 않은 형태일 수 있다. 본 경진대회에서는 datetime 피처가 그렇다.
시각화하기 전에 이 피처를 분석하기 적합하게 변환(피처 엔지니어링)한다.
datetime은 연도, 월, 일, 시간, 분, 초로 구성되어 이있다. 세부적으로 분석해보기 위해 구성요소별로 나누어 보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
print(train['datetime'][100])
print(train['datetime'][100].split())
print(train['datetime'][100].split()[0]) # 날짜
print(train['datetime'][100].split()[1]) # 시간
'''
2011-01-05 09:00:00
['2011-01-05', '09:00:00']
2011-01-05
09:00:00
'''
datetime 피처는 object 타입이기 때문에 문자열처럼 다룰 수 있다.
날짜 문자열을 다시 연도, 월, 일로 나눠보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
print(train['datetime'][100].split()[0])
print(train['datetime'][100].split()[0].split('-'))
print(train['datetime'][100].split()[0].split('-')[0]) # 연도
print(train['datetime'][100].split()[0].split('-')[1]) # 월
print(train['datetime'][100].split()[0].split('-')[2]) # 일
'''
2011-01-05
['2011', '01', '05']
2011
01
05
'''
이어서 시간 문자열을 시, 분, 초 로 나눠보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
print(train['datetime'][100].split()[1])
print(train['datetime'][100].split()[1].split(':'))
print(train['datetime'][100].split()[1].split(':')[0])
print(train['datetime'][100].split()[1].split(':')[1])
print(train['datetime'][100].split()[1].split(':')[2])
'''
09:00:00
['09', '00', '00']
09
00
00
'''
판다스 apply() 함수로 로직을 datetime에 적용해
날짜(date), 연도(year), 월(month), 일(day), 시(hour), 분(minute), 초(second) 피처를 생성한다.
이처럼 기존 피처에서 파생된 피처를 ‘파생 피처’ 혹은 ‘파생 변수’라고 한다.
1
2
3
4
5
6
7
8
9
train['date'] = train['datetime'].apply(lambda x: x.split()[0])
train['year'] = train['datetime'].apply(lambda x: x.split()[0].split('-')[0])
train['month'] = train['datetime'].apply(lambda x: x.split()[0].split('-')[1])
train['day'] = train['datetime'].apply(lambda x: x.split()[0].split('-')[2])
train['hour'] = train['datetime'].apply(lambda x: x.split()[1].split(':')[0])
train['minute'] = train['datetime'].apply(lambda x: x.split()[1].split(':')[1])
train['second'] = train['datetime'].apply(lambda x: x.split()[1].split(':')[2])
요일 feature 생성
요일 feature는 calendar와 datetime 라이브러리를 활용해 만들 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from datetime import datetime
import calendar
print(train['date'][100]) # 날짜
print(datetime.strptime(train['date'][100], "%Y-%m-%d")) # datetime 타입으로 변경 (string parse time)
# 정수로 요일 반환
print(datetime.strptime(train['date'][100], '%Y-%m-%d').weekday())
# 문자열로 요일 반환
print(calendar.day_name[datetime.strptime(train['date'][100], '%Y-%m-%d').weekday()])
'''
2011-01-05
2011-01-05 00:00:00
2
Wednesday
'''
요일(weekday) 피처 추가
1
2
3
train['weekday'] = train['date'].apply(lambda dateString: calendar.day_name[datetime.strptime(dateString, '%Y-%m-%d').weekday()]
)
season과 weather 피처는 범주형 데이터라 어떤 의미인지 파악하기 어려움으로
시각화 의미가 잘 드러나도록 map()함수를 사용하여 문자열로 바꾼다.
✅ map() (내장 함수) vs Series.map() vs Series.apply() 비교 정리표
| 구분 | 적용 대상 | 문법 | 기능 설명 | 예시 코드 |
|---|---|---|---|---|
파이썬 map() | iterable (list, tuple 등) | map(func, iterable) | 각 요소에 함수를 적용, map 객체 반환 (list로 감싸야 함) | list(map(lambda x: x*2, [1, 2, 3])) → [2, 4, 6] |
Series.map() | Pandas Series (1D 열) | series.map(func or dict) | 각 요소에 함수 적용 또는 딕셔너리로 값 매핑 | df['col'].map({1: 'A', 2: 'B'}) → 'A' or 'B' |
Series.apply() | Pandas Series (1D 열) | series.apply(func) | 각 요소에 함수 적용 (복잡한 조건, 분기 처리에 유리) | df['col'].apply(lambda x: x**2 if x > 0 else 0) |
map(func, iterable)→ 파이썬 기본 함수, 판다스 아님Series.map()→ 딕셔너리 매핑 또는 간단 함수에 최적Series.apply()→ 복잡한 로직이나 조건문이 포함된 함수에 적합
1
2
3
4
5
6
train['season'] = train['season'].map({1: 'Spring', 2: 'Summer', 3: 'Fall', 4: 'Winter'})
train['weather'] = train['weather'].map({1: 'Clear', 2: 'Mist, Few clouds', 3: 'Light Snow, Rain, Thunderstorm', 4: 'Heavy Rain, Thunderstorm, Snow, Fog'})
train.head()
| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | date | year | month | day | hour | minute | second | weekday | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | Spring | 0 | 0 | Clear | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 | 2011-01-01 | 2011 | 01 | 01 | 00 | 00 | 00 | Saturday |
| 1 | 2011-01-01 01:00:00 | Spring | 0 | 0 | Clear | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 | 2011-01-01 | 2011 | 01 | 01 | 01 | 00 | 00 | Saturday |
| 2 | 2011-01-01 02:00:00 | Spring | 0 | 0 | Clear | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 | 2011-01-01 | 2011 | 01 | 01 | 02 | 00 | 00 | Saturday |
| 3 | 2011-01-01 03:00:00 | Spring | 0 | 0 | Clear | 9.84 | 14.395 | 75 | 0.0 | 3 | 10 | 13 | 2011-01-01 | 2011 | 01 | 01 | 03 | 00 | 00 | Saturday |
| 4 | 2011-01-01 04:00:00 | Spring | 0 | 0 | Clear | 9.84 | 14.395 | 75 | 0.0 | 0 | 1 | 1 | 2011-01-01 | 2011 | 01 | 01 | 04 | 00 | 00 | Saturday |
data feature가 제공하는 정보는 모두 year, month, day 피처에도 존재하므로 추후 제거한다.
또한 세 달씩 ‘월’을 묶으면 ‘계절’이 된다. 즉, 세분화된 month 피처를 세 달씩 묶으면 season 피처와 의미가 같아진다. 지나치게 세분화된 피처를 더 큰 분류로 묶으면 성능이 좋아지는 경우가 있어 여기서는 season 피처만 남기고 month feature를 제거한다.
4. 데이터 시각화
시각화는 탐색적 데이터 분석에서 가장 중요한 부분이다. 데이터 분포나 데이터간 관계를 한눈에 파악할 수 있기 때문이다.
1
2
3
import seaborn as sns
import matplotlib as mpl
import matplitlib as plt
분포도
분포도(distribution plot)는 수치형 데이터의 집계 값을 나타내는 그래프이다. 집계 값은 총 개수나 비율 등을 의미한다. 아래는 target값인 count의 분포도를 그린다. target값의 분포를 알면 훈련 시 target값을 그대로 사용할지 변환해 사용할지 파악할 수 있기 때문이다.
1
2
3
mpl.rc('font', size = 10) # 폰트 크기를 10으로 설정
sns.displot(train['count']) # 분포도 출력
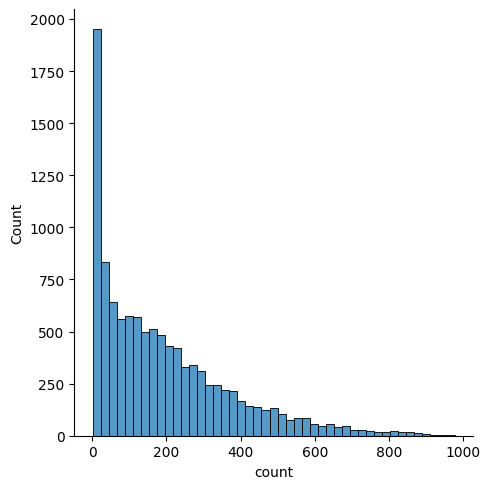
x축은 target값인 count를 나타내고, y축은 총 개수를 나타낸다. 분포도를 보면 target값인 count가 0 근처에 몰려있다. 즉, 분포가 왼쪽으로 많이 편향되어 있다.
회귀 모델이 좋은 성능을 내려면 데이터가 정규분포를 따라야 하는데, 현재 target값 count는 정규 분포를 따르지 않으므로 target 값을 그대로 사용해 모델링 하면 좋은 성능을 기대하기 어렵다.
데이터 분포를 정규분포에 가깝게 만들기 위해 가장 많이 사용하는 방법은 로그변환이다. 로그 변환은 count 분포와 같이 데이터가 왼쪽으로 편향되어 있을 때 사용한다.
⚠️ 데이터에 로그를 취하면 정규분포에 가까워지는 이유
로그 변환이 데이터의 스케일을 압축하기 때문이다. 특히, 값이 큰 데이터의 변화를 더 많이 줄이고, 값이 작은 데이터의 변화를 덜 줄이는 특성이 있다. 이를 통해 데이터의 분포가 더 대칭적으로 변하게 된다.
1. 편향된 데이터의 특징
- 편향된 데이터는 특정 값 근처에 데이터가 몰려 있고, 한쪽으로 긴 꼬리를 가지는 형태(예: 오른쪽으로 긴 꼬리의 분포)를 보인다.
- 예를 들어, 자전거 대여 수량(count) 데이터가 대부분 0~100 근처에 몰려 있고, 일부 값이 500 이상으로 크게 나타난다면, 이는 오른쪽으로 편향된 분포이다.
2. 로그 변환의 효과
로그 변환은 다음과 같은 수식을 사용한다:
\[\hat{y} = \log_{e}(y + 1)\]여기서 $+1$은 $y=0$인 경우를 처리하기 위해 추가된다.
큰 값의 압축: 로그 함수는 값이 커질수록 증가율이 점점 작아진다. 예를 들어:
- $\log(10) = 1$, $\log(100) = 2$, $\log(1000) = 3$로, 값이 10배씩 증가해도 로그 값은 선형적으로 증가한다.
- 따라서, 큰 값들이 상대적으로 더 작아져 분포의 꼬리가 짧아진다.
작은 값의 보존: 작은 값(예: 1, 2, 3 등)은 로그 변환 후에도 상대적으로 큰 변화를 겪지 않으므로, 데이터의 밀집된 부분이 유지된다.
3. 결과적으로 정규분포에 가까워짐
- 로그 변환은 데이터의 스케일을 조정하여 분포의 비대칭성을 줄이고, 꼬리를 짧게 만들어 대칭적인 형태로 변환한다.
- 이는 데이터가 정규분포에 가까워지도록 도와준다.
4. 왜 정규분포가 중요한가?
- 많은 머신러닝 모델(특히 회귀 모델)은 데이터가 정규분포를 따를 때 더 좋은 성능을 보인다.
- 정규분포는 평균과 분산을 기반으로 데이터를 잘 설명할 수 있기 때문에, 모델이 데이터를 더 잘 학습할 수 있다.
예시
편향된 데이터: [1, 2, 3, 10, 100, 1000]
로그 변환 후 (자연로그 ln 기준): [0, 0.69, 1.1, 2.3, 4.6, 6.9]
- 큰 값(1000)이 상대적으로 더 작아지고, 데이터가 더 대칭적으로 변한다.
1
sns.displot(np.log(train['count']))
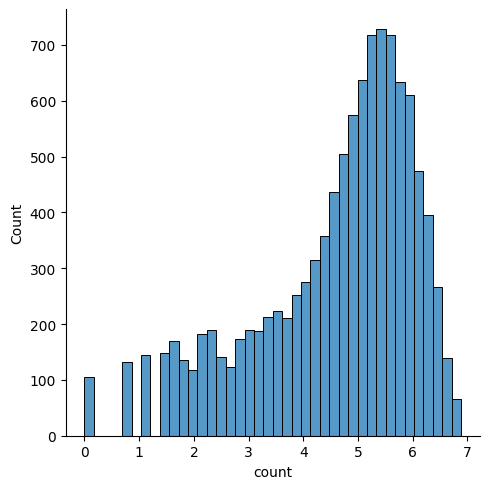
변환 전보다 정규분포에 가까워진것을 확인할 수 있다.
target값 분포가 정규분포에 가까울수록 회귀 모델 성능이 좋아진다. 즉 feature를 바로 활용해 count를 예측하는 것보다 log(count)를 예측하는 편이 더 정확하다.
다만, 마지막에 지수변환을 하여 실제 target값인 count로 복원해야 한다.
\[y=e^{log(y)}\]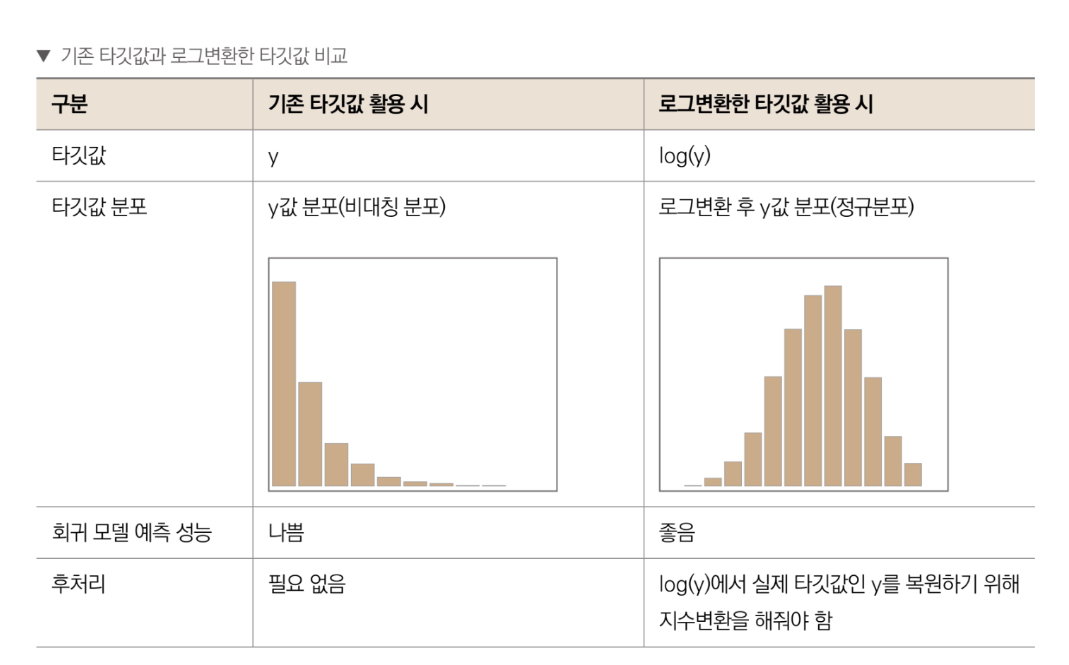
막대 그래프
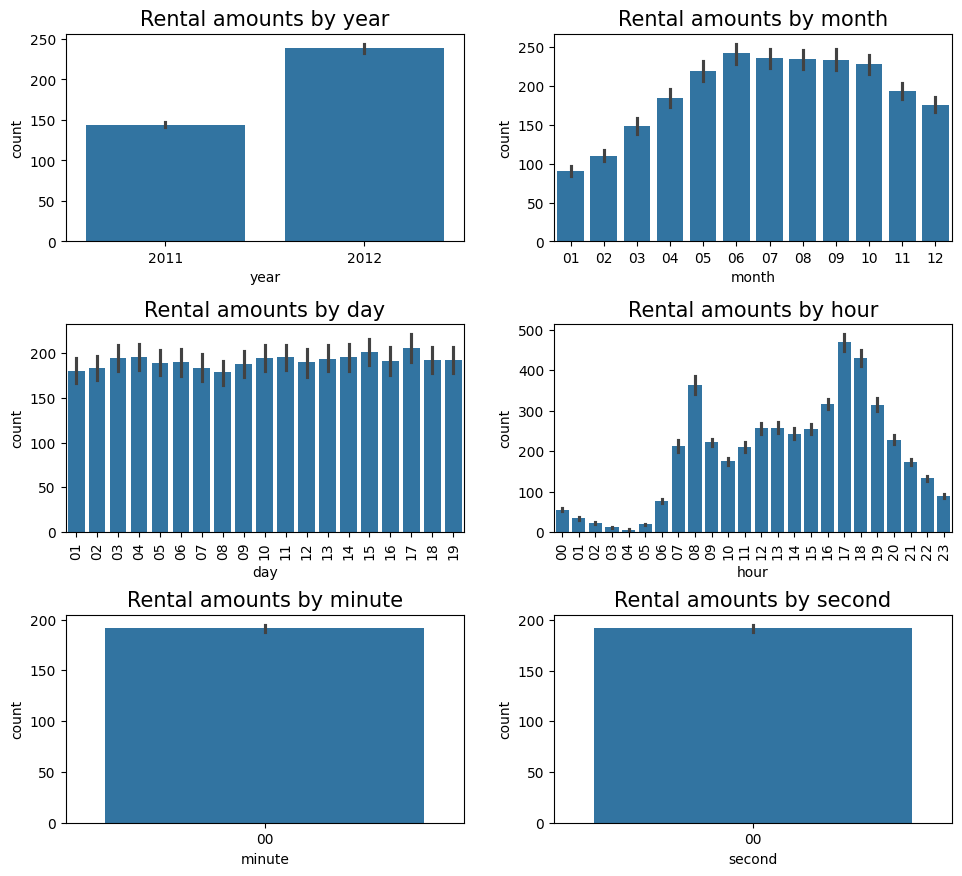
연도, 월, 일, 시, 분, 초 별 데이터들은 범주형 데이터로 각 데이터에 따라 평균 대여 수량이 어떻게 다른지 파악하려고 한다. 그래야 어떤 feature가 중요한지 알 수 있다. 이럴 때 막대 그래프를 이용한다.
스탭 1~3 코드는 한 셀에서 실행해야 정상작동함
시각화 도구별 역할 구분
plt (matplotlib.pyplot)
- 용도: Figure 전체 레벨의 설정
- 주요 메서드:
1
2
3
4
5
# Figure와 axes 생성
figure, axes = plt.subplots(nrows=3, ncols=2)
# Figure 레이아웃 조정
plt.tight_layout()
figure 객체
- 용도: 전체 Figure 레벨의 설정
- 주요 메서드:
1
2
# Figure 전체 크기 설정
figure.set_size_inches(10, 9)
axes 객체
- 용도: 개별 서브플롯(축)의 속성 설정
- 주요 메서드:
1
2
3
4
5
# 개별 축 제목 설정
axes[0, 0].set(title='Rental amounts by year')
# 개별 축 눈금 설정
axes[1, 0].tick_params(axis='x', labelrotation=90)
sns (seaborn)
- 용도: 실제 데이터 시각화 및 통계적 플로팅
- 주요 메서드:
1
2
# 데이터 시각화
sns.barplot(x='year', y='count', data=train, ax=axes[0, 0])
요약
1
2
3
4
5
6
7
8
9
10
11
12
matplotlib.pyplot (plt)
├── Figure (figure)
│ ├── Axes (axes)
│ │ └── Seaborn (sns)
│ │ ├── barplot
│ │ ├── scatterplot
│ │ ├── lineplot
│ │ └── ...기타 플롯
│ └── Figure 레벨 요소
└── 전역 설정 (rc)
데이터 → sns → axes → figure → plt → 화면 출력
| 도구 | 주요 용도 | 적용 범위 |
|---|---|---|
| plt | 구조적 설정 | Figure 생성, 레이아웃 |
| figure | 전체 설정 | Figure 크기 조정 |
| axes | 개별 설정 | 서브플롯 속성 |
| sns | 데이터 시각화 | 그래프 그리기 |
Step1: m행 n열 Figure 준비
첫번째로 총 6개의 그래프(서브플롯)를 품는 3행 2열짜리 Figure를 준비한다.
1
2
3
4
5
6
mpl.rc('font', size=10) # 폰트 크기 설정
mpl.rc('axes', titlesize=15) # 각 축의 제목 크기 설정
figure, axes = plt.subplots(nrows=3, ncols=2) # 3행 2열 Figure 생성
plt.tight_layout() # 그래프 사이에 여백 확보
figure.set_size_inches(10, 9) # 전체 Figure 크기를 10x9인치로 설정
Step2: 각 축에 서브플롯 할당
1
2
3
4
5
6
7
8
sns.barplot(x='year', y='count', data=train, ax=axes[0, 0])
sns.barplot(x='month', y='count', data=train, ax=axes[0, 1])
sns.barplot(x='day', y='count', data=train, ax=axes[1, 0])
sns.barplot(x='hour', y='count', data=train, ax=axes[1, 1])
sns.barplot(x='minute', y='count', data=train, ax=axes[2, 0])
sns.barplot(x='second', y='count', data=train, ax=axes[2, 1])
Step3: 세부 설정
각 서브 플롯에 제목을 추가하고, x축 라벨이 겹치지 않게 개선
1
2
3
4
5
6
7
8
9
10
11
12
axes[0, 0].set(title = 'Rental amounts by year')
axes[0, 1].set(title = 'Rental amounts by month')
axes[1, 0].set(title = 'Rental amounts by day')
axes[1, 1].set(title = 'Rental amounts by hour')
axes[2, 0].set(title = 'Rental amounts by minute')
axes[2, 1].set(title = 'Rental amounts by second')
# 1 행에 위치한 서브플롯들의 x축 라벨 90도 회전
axes[1, 0].tick_params(axis = 'x', labelrotation = 90)
axes[1, 1].tick_params(axis = 'x', labelrotation = 90)
전체 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# Step 1: m행 n열 Figure 준비
mpl.rc('font', size=10) # 폰트 크기 설정
mpl.rc('axes', titlesize=15) # 각 축의 제목 크기 설정
figure, axes = plt.subplots(nrows=3, ncols=2) # 3행 2열 Figure 생성
plt.tight_layout() # 그래프 사이에 여백 확보
figure.set_size_inches(10, 9) # 전체 Figure 크기를 10x9인치로 설정
# Step 2: 각 축에 서브플롯 할당
# 각 축에 연도, 월, 일, 시, 분, 초별 평균 대여 수량 막대 그래프 할당
sns.barplot(x='year', y='count', data=train, ax=axes[0, 0])
sns.barplot(x='month', y='count', data=train, ax=axes[0, 1])
sns.barplot(x='day', y='count', data=train, ax=axes[1, 0])
sns.barplot(x='hour', y='count', data=train, ax=axes[1, 1])
sns.barplot(x='minute', y='count', data=train, ax=axes[2, 0])
sns.barplot(x='second', y='count', data=train, ax=axes[2, 1])
# Step 3: 세부 설정
# 3-1: 서브플롯에 제목 달기
axes[0, 0].set(title = 'Rental amounts by year')
axes[0, 1].set(title = 'Rental amounts by month')
axes[1, 0].set(title = 'Rental amounts by day')
axes[1, 1].set(title = 'Rental amounts by hour')
axes[2, 0].set(title = 'Rental amounts by minute')
axes[2, 1].set(title = 'Rental amounts by second')
# 3-2 : 1 행에 위치한 서브플롯들의 x축 라벨 90도 회전
axes[1, 0].tick_params(axis = 'x', labelrotation = 90)
axes[1, 1].tick_params(axis = 'x', labelrotation = 90)
박스플롯
박스플롯은 범주형 데이터에 따른 수치형 데이터 정보를 나타내는 그래프이다. 막대 그래프보다 더 많은 정보를 제공하는 특징이 있다.
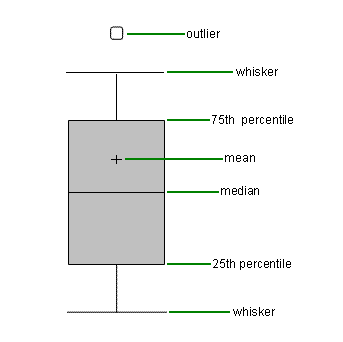
- median - 중앙값
- 데이터들을 정렬했을 때 중앙값 위치 선으로 표시
- 예를들어 데이터 [1, 5, 9, 10 ,15, 20, 34] 일 때, 중앙값은 10
- IQR - 25% ~ 75%에 해당한 부분
- 75th Percentile - 제 3사분위수
- 25th Percentile - 제 1사분위수
Whisker - 최댓값, 최솟값
- Outlier - 이상치
계절, 날씨, 공휴일, 근무일(범주형 데이터)별 대여수량(수치형 데이터)을 박스플롯으로 그려보면, 각 범주형 데이터에 따라 타겟값인 대여 수량이 어떻게 변하는지 알 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# Step 1: m행 n열 Figure 준비
mpl.rc('font', size=10)
figure, axes = plt.subplots(nrows=2, ncols=2)
plt.tight_layout()
figure.set_size_inches(10, 10)
# Step 2: 서브플롯 할당
# 계절, 날씨, 공휴일, 근부일별 대여 수량 박스플롯
sns.boxplot(x='season', y='count', data=train, ax=axes[0, 0])
sns.boxplot(x='weather', y='count', data=train, ax=axes[0, 1])
sns.boxplot(x='holiday', y='count', data=train, ax=axes[1, 0])
sns.boxplot(x='workingday', y='count', data=train, ax=axes[1, 1])
# Step 3: 세부 설정
# 3-1 : 서브플롯에 제목 달디
axes[0, 0].set(title="Box Plot On Count Across Season")
axes[0, 1].set(title="Box Plot On Count Across Weather")
axes[1, 0].set(title='Box Plot On Count Across Holiday')
axes[1, 1].set(title='Box Plot On Count Across Working Day')
# 3-2 : x축 라벨 겹침 해결
axes[0, 1].tick_params(axis = 'x', labelrotation=10)
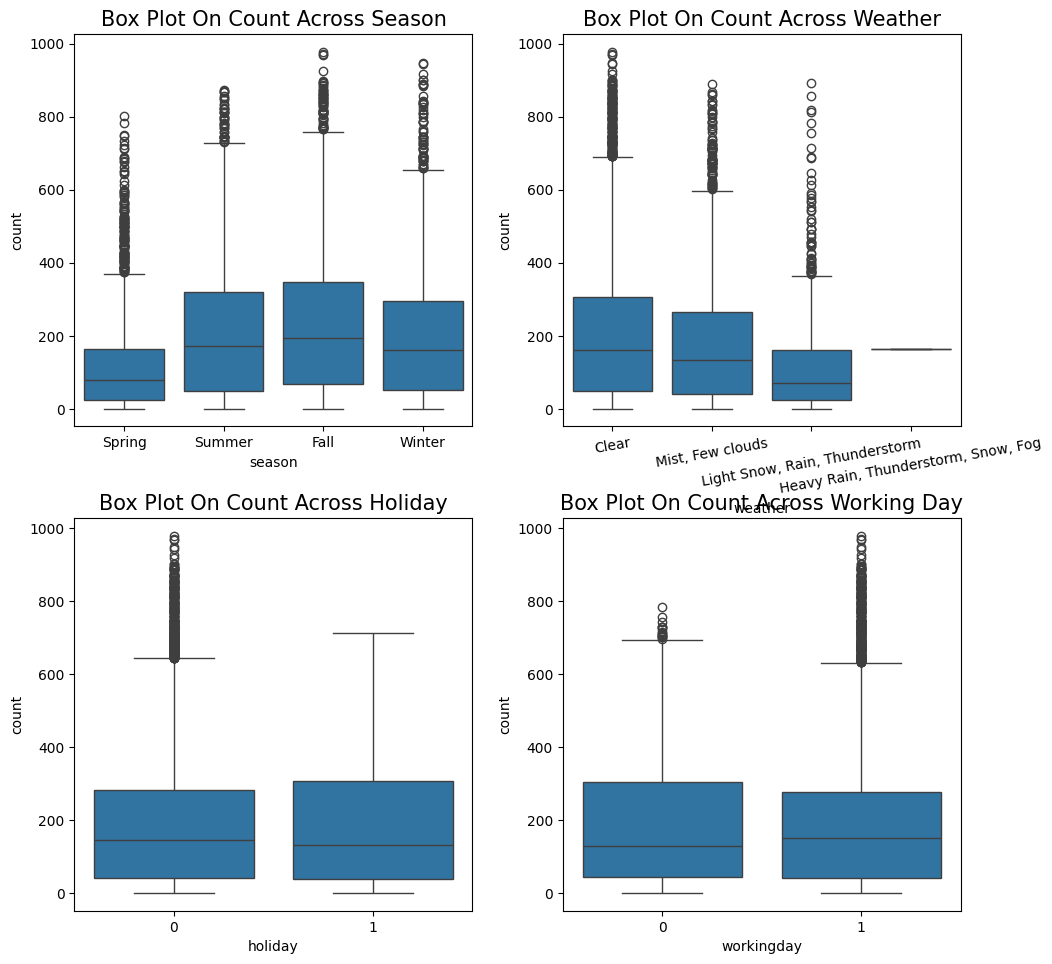
계절별 대여 수량은 봄에 가장 적고, 가을에 가장 많은것을 확인할 수 있다.
날씨별 대여 수량은 날씨가 좋을 때 대여 수량이 가장 많고, 안 좋을수록 수량이 적다.
공휴일 여부에 따른 대여 수량은 공휴일일 때와 아닐 때 자전거 대여 수량의 중앙값은 거의 비슷하지만 공휴일이 아닐 때는 이상치가 많다.
근무일 여부에 따른 대여 수량 또한 근무일일 때 이상치가 많다.
포인트플롯
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Step 1: m행 n열 Figure 준비
mpl.rc('font', size=10)
figure, axes = plt.subplots(nrows=5) # 5행 1열
figure.set_size_inches(12, 18)
# Step 2: 서브플롯 할당
# 근무일, 공휴일, 요일, 계절, 날씨에 따른 시간대별 평균 대여 수량 포인트플롯
sns.pointplot(x='hour', y='count', data=train, hue='workingday', ax=axes[0])
sns.pointplot(x='hour', y='count', data=train, hue='holiday', ax=axes[1])
sns.pointplot(x='hour', y='count', data=train, hue='weekday', ax=axes[2])
sns.pointplot(x='hour', y='count', data=train, hue='season', ax=axes[3])
sns.pointplot(x='hour', y='count', data=train, hue='weather', ax=axes[4])
# 포인트플롯의 hue파라미터에 비교하고 싶은 feature를 전달할 수 있다. hue 파라미터에 전달한 피처를 기준으로 그래프가 나뉜다.
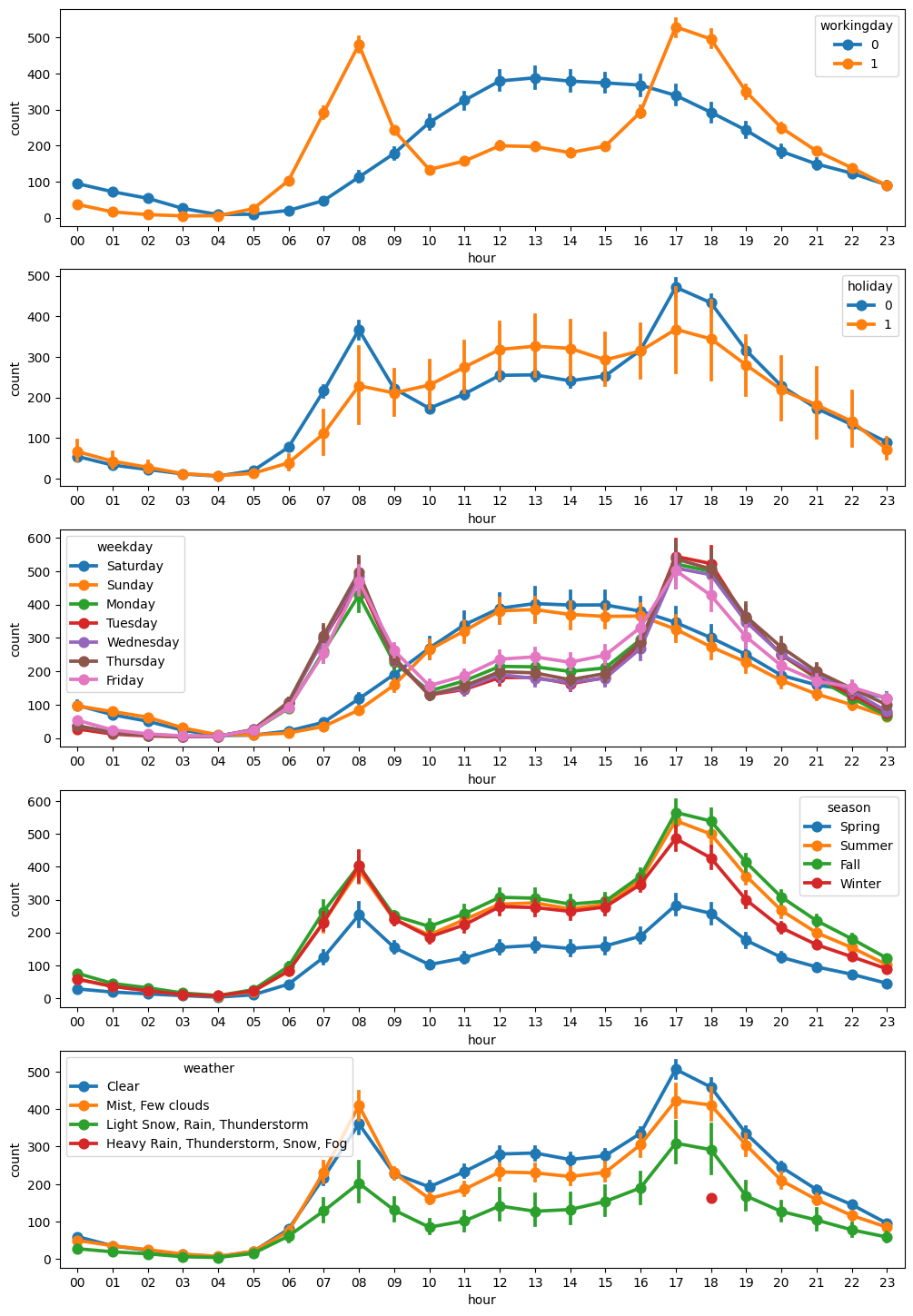
1번 그래프를 보면 근무일에는 출퇴근 시간에 대여 수량이 많고 쉬는 날에는 오후 12~2시에 가장 많은것을 확인할 수 있다.
공휴일 여부, 요일에 따른 포인트플롯도 근무일 여부에 따른 포인트플롯(1번 그래프)와 비슷한 양상을 보인다.
계절에 따른 시간대별 포인트 플롯을 보면, 대여 수량은 가을에 가장 많고, 봄에 가장 적다.
마지막 그래프는 날씨에 따른 시간대별 포인트 플롯으로 날씨가 좋은 때 대여량이 가장 많은것을 확인할 수 있다.
그런데 폭우, 폭설이 내릴 때 18시에 대여 건수가 있다. 이런 이상치는 제거를 고려해보는 것도 좋다.
실제로 이 데이터를 제거한 경우 최종모델의 성능이 더 좋았다.
weather == 4 인 데이터 제거
회귀선을 포함한 산점도 그래프
회귀선을 포함한 산점도 그래프는 수치형 데이터 간 상관관계를 파악하는 데 사용한다. 아래는 수치형 데이터인 온도, 체감 온도, 풍속, 습도별 대여 수량을 그리는 코드이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Step 1: m행 n열 Figure 준비
mpl.rc('font', size=15)
figure, axes = plt.subplots(nrows=2, ncols=2)
plt.tight_layout()
figure.set_size_inches(7, 6)
# Step 2: 서브플롯 할당
# 온도, 체감 온도, 풍속, 습도 별 대여 수량 산점도 그래프
sns.regplot(x='temp', y='count', data=train, ax=axes[0, 0],
scatter_kws={'alpha': 0.2}, line_kws={'color': 'blue'})
sns.regplot(x='atemp', y='count', data=train, ax=axes[0, 1],
scatter_kws={'alpha': 0.2}, line_kws={'color': 'blue'})
sns.regplot(x='windspeed', y='count', data=train, ax=axes[1, 0],
scatter_kws={'alpha': 0.2}, line_kws={'color': 'blue'})
sns.regplot(x='humidity', y='count', data=train, ax=axes[1, 1],
scatter_kws={'alpha': 0.2}, line_kws={'color': 'blue'})
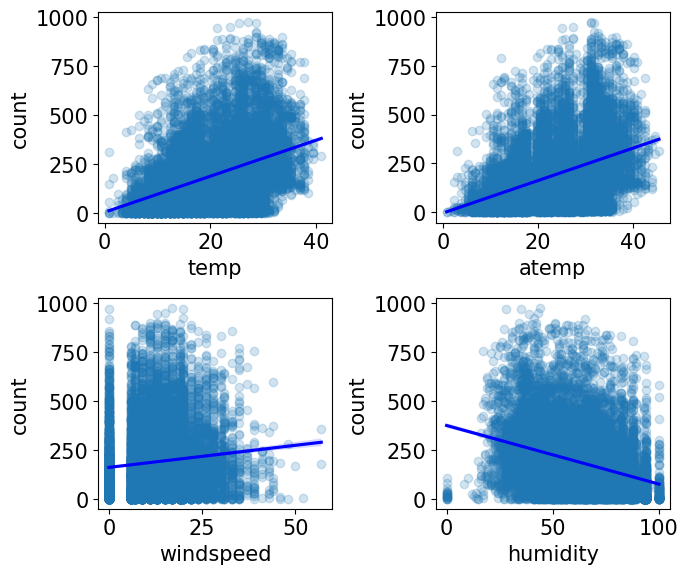
회귀선 기울기로 대략적인 추세를 파악할 수 있다. 1과 2 그래프로부터 보면, 온도와 체감온도가 높을수록 대여 수량이 많다. 습도는 낮을수록 대여를 많이하는것을 확인할 수 있다.
즉 , 대여 수량은 추울 때보다 따뜻할 때 많고, 습할 때보다 습하지 않을 때 많다.
3번 그래프의 회귀선을 보면 풍속이 셀수록 대여 수량이 많다. 이유는 windspeed feature에 결측값이 많기 때문이다. 자세히보면 풍속이 0인 데이터가 꽤 많은 것을 확인할 수 있다. 실제 풍속이 0이 아니라 관측치가 없거나 오류로 인해 0으로 기록됐을 가능성이 높다.
따라서 그래프만으로 풍속과 대여 수량의 상관관계를 파악하기 힘드므로 결측값을 다른값으로 대체하거나 windspeed feature 자체를 삭제하면 된다.
windspeed feature 제거
히트맵
DataFrame 슬라이싱 [[ ]]
1. DataFrame 전용 문법
이중 대괄호 [[ ]] 슬라이싱은 pandas DataFrame에서만 사용할 수 있는 특별한 문법이다.
2. DataFrame 사용 예시
DataFrame에서만 가능한 이중 대괄호 사용
1
2
3
4
5
6
7
8
9
import pandas as pd
df = pd.DataFrame({
'A': [1,2,3],
'B': [4,5,6],
'C': [7,8,9]
})
selected = df[['A', 'B']] # 여러 열 선택
이중 대괄호 문법은 pandas가 DataFrame을 위해 특별히 구현한 기능으로, 다른 데이터 구조에서는 사용할 수 없다.
temp, atemp, humidity, windspeed, count는 수치형 데이터이다. 수치형 데이터끼리 어떤 상관관계가 이는지 확인해보자. corr() 함수는 DataFrame 내의 피처 간 상관계수를 계산해 반환한다.
1
train[['temp', 'atemp', 'humidity', 'windspeed', 'count']].corr()
| temp | atemp | humidity | windspeed | count | |
|---|---|---|---|---|---|
| temp | 1.000000 | 0.984948 | -0.064949 | -0.017852 | 0.394454 |
| atemp | 0.984948 | 1.000000 | -0.043536 | -0.057473 | 0.389784 |
| humidity | -0.064949 | -0.043536 | 1.000000 | -0.318607 | -0.317371 |
| windspeed | -0.017852 | -0.057473 | -0.318607 | 1.000000 | 0.101369 |
| count | 0.394454 | 0.389784 | -0.317371 | 0.101369 | 1.000000 |
조합이 많아 어느 feature들 간의 관계가 깊은지 한눈에 들어오지 않는다. 이때 히트맵을 사용한다. 히트맵은 데이터 간 관계를 색상으로 표현하여, 여러 데이터를 한눈에 비교하기에 좋다.
1
2
3
4
5
6
7
# 피처 간 상관관계 매트릭스
corrMat = train[['temp', 'atemp', 'humidity', 'windspeed', 'count']].corr()
fig, ax = plt.subplots()
fig.set_size_inches(10, 10)
sns.heatmap(corrMat, annot=True) # 상관관계 히트맵 그리기
ax.set(title='Heatmap of Numerical Data')
corr() 함수로 구한 상관관계 매트릭스 corrMat를 heatmap() 함수에 인수로 넣어주면 된다.
이때 annot 파라미터를 True로 설정하면 상관계수가 숫자로 표시된다.
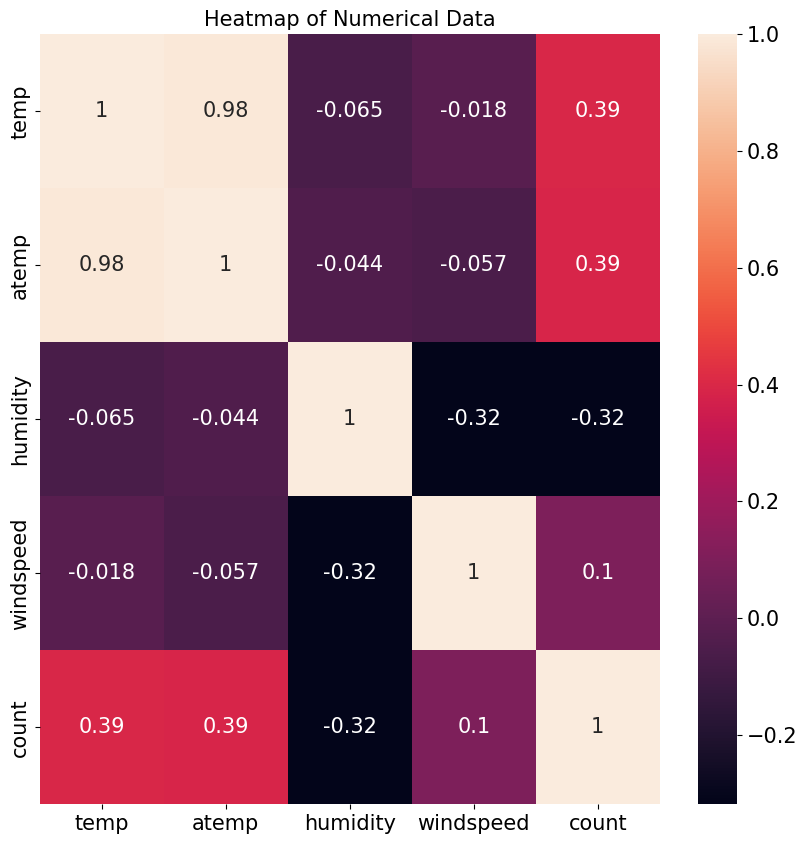
온도(temp)와 대여 수량(count)는 0.39로 양의 상관관계를 보인다.
온도가 높을수록 대여 수량이 많다는 의미이다. 반면, 습도(humidity)와 대여 수량은 음수이니 습도가 ‘낮을수록’ 대여 수량이 많다는 뜻이다. 앞서 산점도 그래프에서 분석한 내용과 동일하다.
풍속(windspeed)와 대여 수량의 상관계수는 0.1이다. 상관계수가 매우 약하다.
windspeed feature 제거
분석 정리 및 모델링 전략
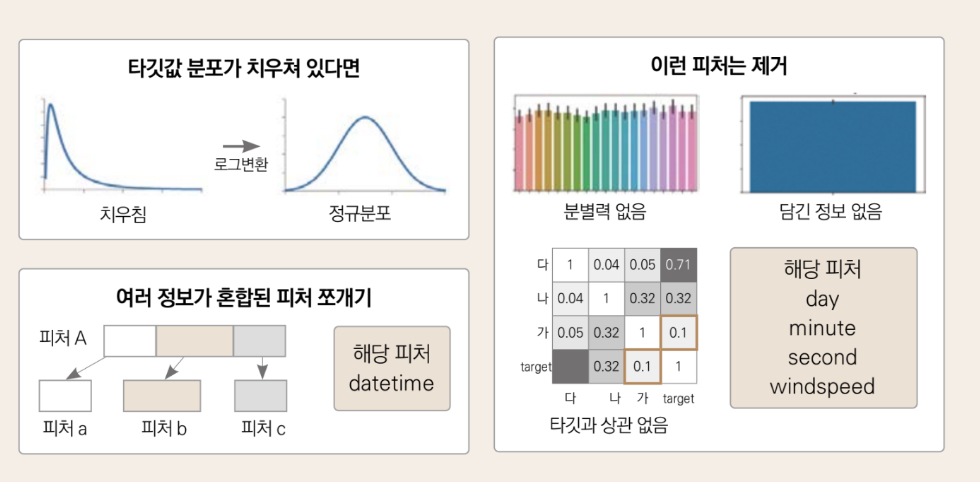
타겟값 변환: 분포도 확인 결과 타겟값인 count가 0 근처로 치우쳐 있으므로 로그 변홚여 정규 분포에 가깝게 만들어야 한다. 타겟값을 count가 아닌 log(count)로 변환해 사용할 것으므로 마지막에 다시 지수변환해 count로 복원해야 한다.
파생 피처 추가: datetime 피처는 여러 가지 정보의 혼합체이므로 각각을 분리해 year, month, day, hour, minute, second 피처를 생성할 수 있었다.
파생 피처 추가: datetime에 숨어 있는 또 다른 정보인 요일(weekday) 피처를 추가했다.
피처 제거: 테스트 데이터에 없는 피터는 훈련에 사용해도 큰 의미가 없다. 따라서 훈련 데이터에만 있는 casual과 registered 피처는 제거한다.
피처 제거: datetime feature는 인덱스 역할만 하므로 타겟값 예측에 아무런 도움이 되지 않는다.
피처 제거: date feature가 제공하는 정보는 year, month, day feature에 담겨 있다.
피처 제거: month는 season 피처의 세부 분류로 볼 수 있다. 데이터가 지나치게 세분화 되어 있으면 분류별 데이터 수가 적어서 오히려 학습에 방해가 되기도 한다.
피처 제거: 막대 그래프 확인 결과 파생 피처인 day는 분별력이 없다.
피처 제거: 막대 그래프 확인 결과 파생 피처인 minute와 second에는 아무런 정보가 담겨있지 않다.
이상치 제거: 포인트 플롯 확인 결과 weather가 4인 데이터는 이상치이다.
피처 제거: 산점도 그래프와 히트맵 확인 결과 windspeed 피처에는 결측값이 많고 대여 수량과의 상관관계가 매우 약하다.
모델링 전략
베이스라인 모델: 가장 기본적인 회귀 모델인 LinearRegression 채택
성능 개선: 릿지, 라쏘, 랜덤 포레스트 회귀 모델
피처 엔지니어링: 앞의 분석 수준에서 모든 모델에서 동일하게 수행
하이퍼파라미터 최적화: 그리드서치
기타: 타겟값이 count가 아닌 log(count)임
5. 베이스라인 모델
베이스라인 모델 전체 프로세스

데이터 로드
1
2
3
4
5
6
7
8
import numpy as np
import pandas as pd
data_path = 'datasets/'
train = pd.read_csv(data_path + 'train.csv')
test = pd.read_csv(data_path + 'test.csv')
submission = pd.read_csv(data_path + 'sampleSubmission.csv')
피처 엔지니어링
보통은 훈련 데이터와 테스트 데이터에 공통으로 반영해야 하기 때문에, 피처 엔지니어링 전에 두 데이터를 합쳤다가 다 끝나면 도로 나눠준다.
이상치 제거
포인트 플롯에서 확인한 결과 훈련 데이터에서 weather가 4인 데이터(폭우, 폭설이 내리는날 저녁 6시에 대여)는 이상치였으므로 제거한다.
1
2
# 훈련 데이터에서 weather가 4가 아닌 데이터만 추출
train = train[train['weather'] != 4]
pandas에서만 적용되는 DataFrame 필터링 문법
train['weather'] != 4
→weather컬럼에서 값이 4가 아닌 불리언 시리즈 (True/False 시리즈) 를 만듦train[...](train[[True] * len(train)] 하면 다 나옴) → 위에서 만들어진 불리언 시리즈를 사용해, True인 행만 선택함
결과적으로 weather 값이 4인 행은 제외하고 나머지만 필터링
데이터 합치기
1
2
3
all_data = pd.concat([train, test], ignore_index=True) # 원 데이터의 인덱스를 무시하고 이어 붙힘
all_data
| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0000 | 3.0 | 13.0 | 16.0 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0000 | 8.0 | 32.0 | 40.0 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0000 | 5.0 | 27.0 | 32.0 |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0000 | 3.0 | 10.0 | 13.0 |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0000 | 0.0 | 1.0 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 17373 | 2012-12-31 19:00:00 | 1 | 0 | 1 | 2 | 10.66 | 12.880 | 60 | 11.0014 | NaN | NaN | NaN |
| 17374 | 2012-12-31 20:00:00 | 1 | 0 | 1 | 2 | 10.66 | 12.880 | 60 | 11.0014 | NaN | NaN | NaN |
| 17375 | 2012-12-31 21:00:00 | 1 | 0 | 1 | 1 | 10.66 | 12.880 | 60 | 11.0014 | NaN | NaN | NaN |
| 17376 | 2012-12-31 22:00:00 | 1 | 0 | 1 | 1 | 10.66 | 13.635 | 56 | 8.9981 | NaN | NaN | NaN |
| 17377 | 2012-12-31 23:00:00 | 1 | 0 | 1 | 1 | 10.66 | 13.635 | 65 | 8.9981 | NaN | NaN | NaN |
17378 rows × 12 columns
테스트 데이터에 casual, registered feature와 target값이 없으므로 NaN 으로 표시됨
파생 피처 추가
훈련 데이터는 매달 1일부터 19일까지의 기록이고, 테스트 데이터는 매달 20일부터 월말까지의 기록이다. 따라서 대여 수량을 예측할 때 일(day) feature는 사용할 필요가 없다.
minute와 second feature도 모든 기록에서 값이 같으므로 예측에 사용할 필요가 없다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
''' 문자열 조작 방식 '''
from datetime import datetime
# 날짜 피처 생성
all_data['date'] = all_data['datetime'].apply(lambda x: x.split()[0])
# 연도 피처 생성
all_data['year'] = all_data['datetime'].apply(lambda x: x.split()[0].split('-')[0])
# 월 피처 생성
all_data['month'] = all_data['datetime'].apply(lambda x: x.split()[0].split('-')[1])
# 시 피처 생성
all_data['hour'] = all_data['datetime'].apply(lambda x: x.split()[1].split(':')[0])
# 요일 피처 생성
all_data['weekday'] = all_data['date'].apply(lambda dateString: datetime.strptime(dateString, '%Y-%m-%d').weekday())
둘 중 하나 사용하면 됨
1
2
3
4
5
6
7
8
9
10
11
12
''' datetime 타입 방식 '''
# datetime 타입으로 바꾸기
all_data['datetime'] = pd.to_datetime(all_data['datetime'])
all_data['year'] = all_data['datetime'].dt.year
all_data['month'] = all_data['datetime'].dt.month
all_data['hour'] = all_data['datetime'].dt.hour
all_data['weekday'] = all_data['datetime'].dt.weekday
필요 없는 피처 제거
causl, registered, datetie, date, month, windspped 제거
1
2
3
drop_features = ['casual', 'registered', 'datetime', 'date', 'month', 'windspeed']
all_data = all_data.drop(drop_features, axis=1)
피처 선택이란?
모델링 시 데이터의 특징을 잘 나타내는 주요 피처만 선택하는 작업을 피처 선택 이라고 한다.
타겟값 예측과 관련 없는 피처가 많다면 예측 성능이 떨어진다.
피처가 많다고 무조건 좋은게 아니라 타겟값과 관련 있는 피처가 필요하다.
탐색적 데이터 분석, 피처 중요도, 상관관계 매트릭스 등을 활용해 종합적으로 판단해야 한다.
데이터 나누기
타겟값이 있으면 훈련데이터고, 없으면 테스트 데이터이다.
1
2
3
4
5
6
7
8
9
10
11
# 훈련 데이터와 테스트 데이터 나누기
X_train = all_data[~pd.isnull(all_data['count'])]
X_test = all_data[pd.isnull(all_data['count'])]
# 타겟값 count 제거
X_train = X_train.drop(['count'], axis = 1)
X_test = X_test.drop(['count'], axis = 1)
y = train['count'] # 타겟값
X_train.head()
| season | holiday | workingday | weather | temp | atemp | humidity | year | hour | weekday | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 2011 | 00 | 5 |
| 1 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 2011 | 01 | 5 |
| 2 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 2011 | 02 | 5 |
| 3 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 2011 | 03 | 5 |
| 4 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 2011 | 04 | 5 |
datetime, windspeed, casual, registered, count가 빠졌고, 대신 year, hour, weekday가 추가된 것을 확인할 수 있다.
평가지표 계산 함수 작성
본 경진대회 평가지표인 RMSLE 계산 함수 작성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import numpy as np
def rmsle(y_true, y_pred, convertExp=True):
# 지수변환
if convertExp:
y_true = np.exp(y_true)
y_pred = np.exp(y_pred)
# 로그변환 후 결측값을 0으로 변환
log_true = np.nan_to_num(np.log(y_true + 1))
log_pred = np.nan_to_num(np.log(y_pred + 1))
# RMSLE 계산
output = np.sqrt(np.mean((log_true - log_pred)**2))
# np.mean -> 다 더해서 갯수로 나눔
return output
지수변환을 사용하는 이유는 target 값으로 count가 아닌 log(count)를 사용하기 때문이다.
만약 타겟값이 정규분포를 따른다면 타겟값으로 count를 그대로 사용해도 된다. 그럴경우 RMSLE를 계산할 때 지수변환을 하지 않아도 된다.
y_true와 y_pred를 로그변환하고 결측값은 0으로 변환한다.
\[\sqrt{ {1\over{N} } \sum\limits_{i=1}^n (log(y_{i} + 1) - log({\hat{y_{i} } + 1}))^2}\]sklearn.metrics.mean_squared_log_error(y_true, y_pred, squared=False) 메서드를 이용하면 RMSLE를 구할 수 있다.
모델 훈련
사이킷런이 제공하는 가장 간단한 선형회귀 모델인 LinearRegression을 임포트하고, 훈련 데이터로 모델을 훈련시킨다.
1
2
3
4
5
6
7
from sklearn.linear_model import LinearRegression
linear_reg_model = LinearRegression()
log_y = np.log(y)
linear_reg_model.fit(X_train, log_y)
훈련 전에 타겟값을 로그변환 했다. y는 타겟값인 train[‘count’]를 할당한 변수.
선형 회귀 모델을 훈련한다는 것은 독립변수(피처)인 X_train과 종속변수(타겟값)인 log_y에 대응하는 최적의 선형회귀 계수를 구한다는 의미이다.
\[Y = \theta_{0} + \theta_{1}x_{1} + \theta_{2}x_{2} + \theta_{3}x_{3}\]독립변수 $x_{1}, x_{2}, x_{3}$ 와 종속변수 $Y$를 활용하여 선형회귀 모델을 훈련하면 독립변수와 종속변수에 대응하는 최적의 선형 회귀계수 $\theta_{1}, \theta_{2}, \theta_{3}$ 를 구할 수 있다. 이 과정이 훈련이다.
$\theta_{1}, \theta_{2}, \theta_{3}$ 값을 아는 상태에서 새로운 독립변수 $x_{1}, x_{2}, x_{3}$가 주어진다면 종속변수 $Y$를 구할 수 있다. 이 과정이 예측이다. 훈련 단계에서 한번도 보지 못한 독립변수가 주어지더라도 회귀계수를 알고 있기 때문에 종속변수를 예측할 수 있다.
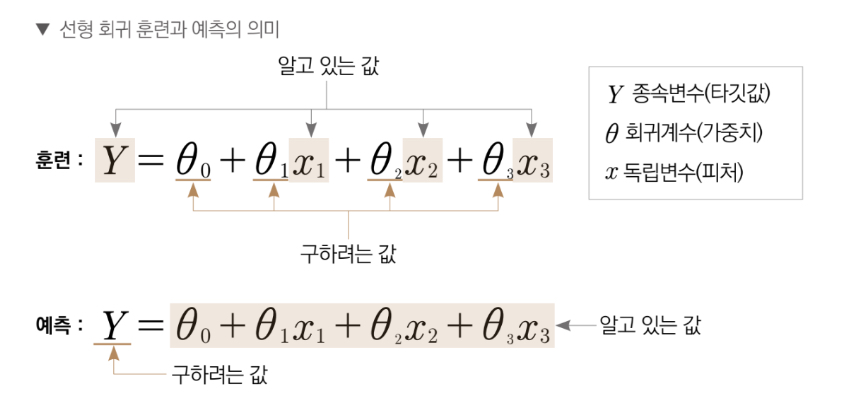
훈련: 피처(독립변수)와 타겟값(종속변수)이 주어졌을 때 최적의 가중치(회귀계수)를 찾는 과정
예측: 최적의 가중치를 아는 상태(훈련된 모델)에서 새로운 독립변수(데이터)가 주어졌을 때 타겟값을 추정하는 과정
탐색적 데이터 분석: 예측에 도움이 될 피처를 추리고, 적절한 모델링 방법을 탐색하는 과정
피처 엔지니어링: 추려진 피처들을 훈련에 적합하도록, 성능 향상에 도움이되도록 가공하는 과정
예측 및 결과 제출
테스트 데이터로 예측한 결과를 이용해야 한다.
현재 예측값이 count가 아니라 log(count)이기 때문에 예측한 값에 지수변환을 해줘야 한다.
1
2
3
4
5
linearreg_preds = linear_reg_model.predict(X_test) # 테스트 데이터로 예측
submission['count'] = np.exp(linearreg_preds) # 지수변환
submission.to_csv('submission.csv', index=False) # 파일로 저장
index = False로 설정해야 DataFrame 인덱스를 제외하고 저장한다.
성능개선 I : 릿지 회귀 모델
릿지 회귀 모델은 L2 규제를 적용한 선형 회귀 모델이다. 규제(regularization) 란 모델이 훈련 데이터에 과대적합 (overfitting) 되지 않도록 해주는 방법이다.
릿지 회귀 모델은 성능이 좋은 편은 아님. 단순 선형 회귀 모델보다 과대적합이 적은 모델 정도로 생각하면 된다.
베이스라인 모델과 모델 성능 개선 프로세스 비교
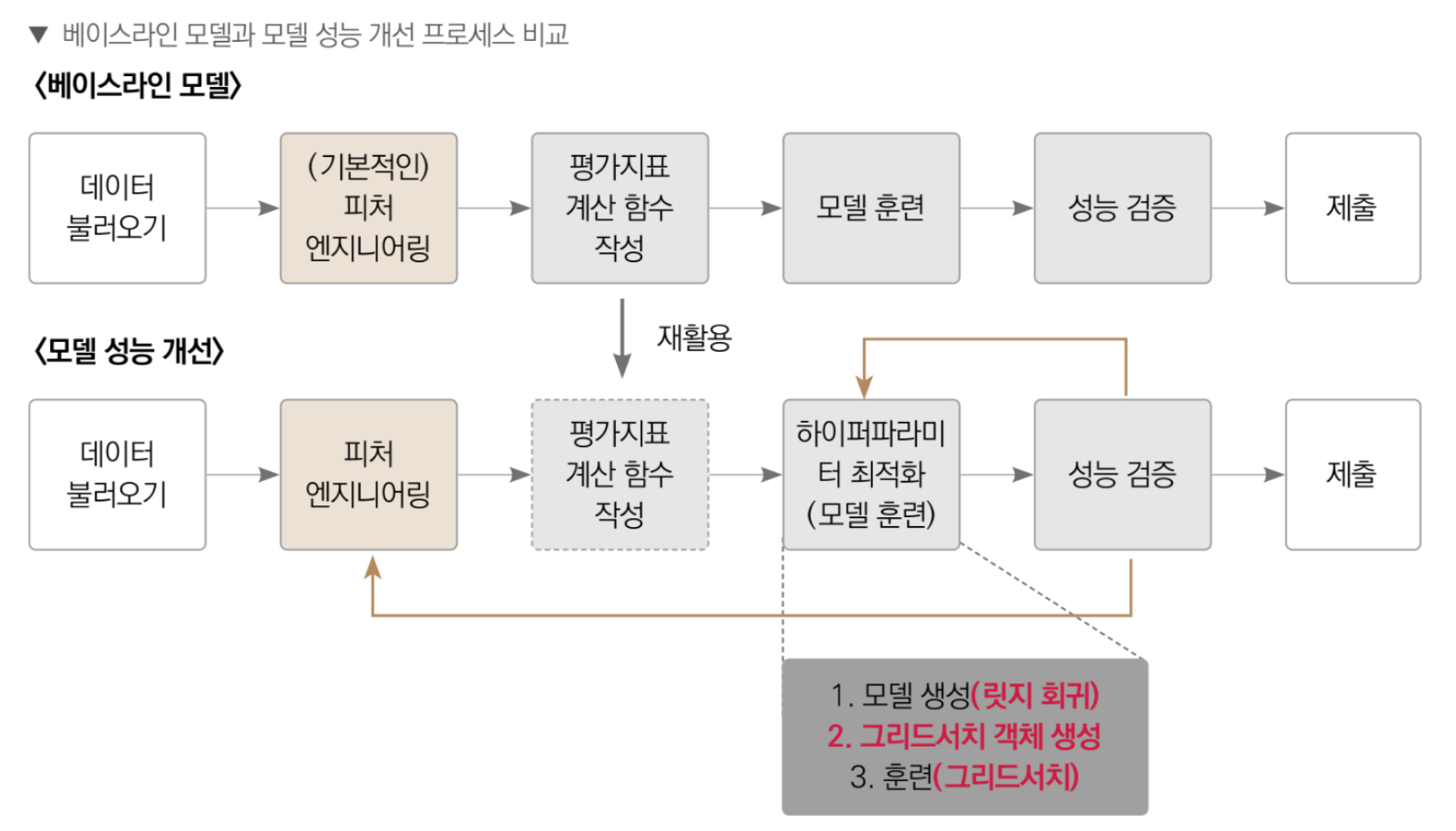
하이퍼파라미터 최적화(모델 훈련)
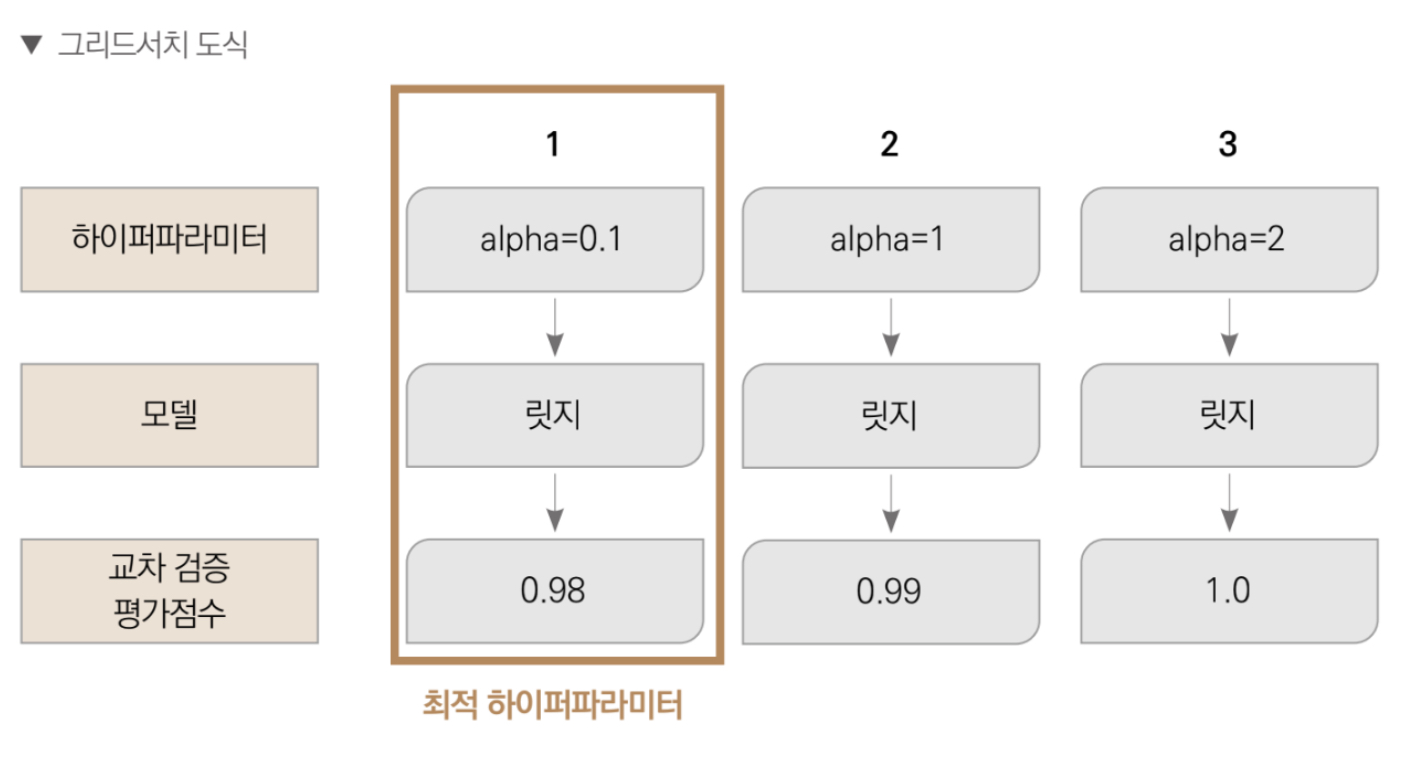
모델 훈련 단계에서 그리드서치 기법을 사용한다. 그리드서치는 하이퍼파라미터를 격자 처럼 촘촘하게 순회하며 최적의 하이퍼파라미터 값을 찾는 기법이다. 각 하이퍼파라미터를 적용한 모델마다 교차 검증 cross-validation 하며 성능을 측정하여 최종적으로 성능이 가장 좋았을 때의 하이퍼파라미터 값을 찾아준다.
교차 검증 평가점수는 보통 에러 값이기 때문에 낮을수록 좋다.
그리드 서치는 자동으로 테스트 하려는 하이퍼파라미터와 값의 범위만 전달하면 알아서 모든 가능한 조합을 순회하며 교차 검증한다.
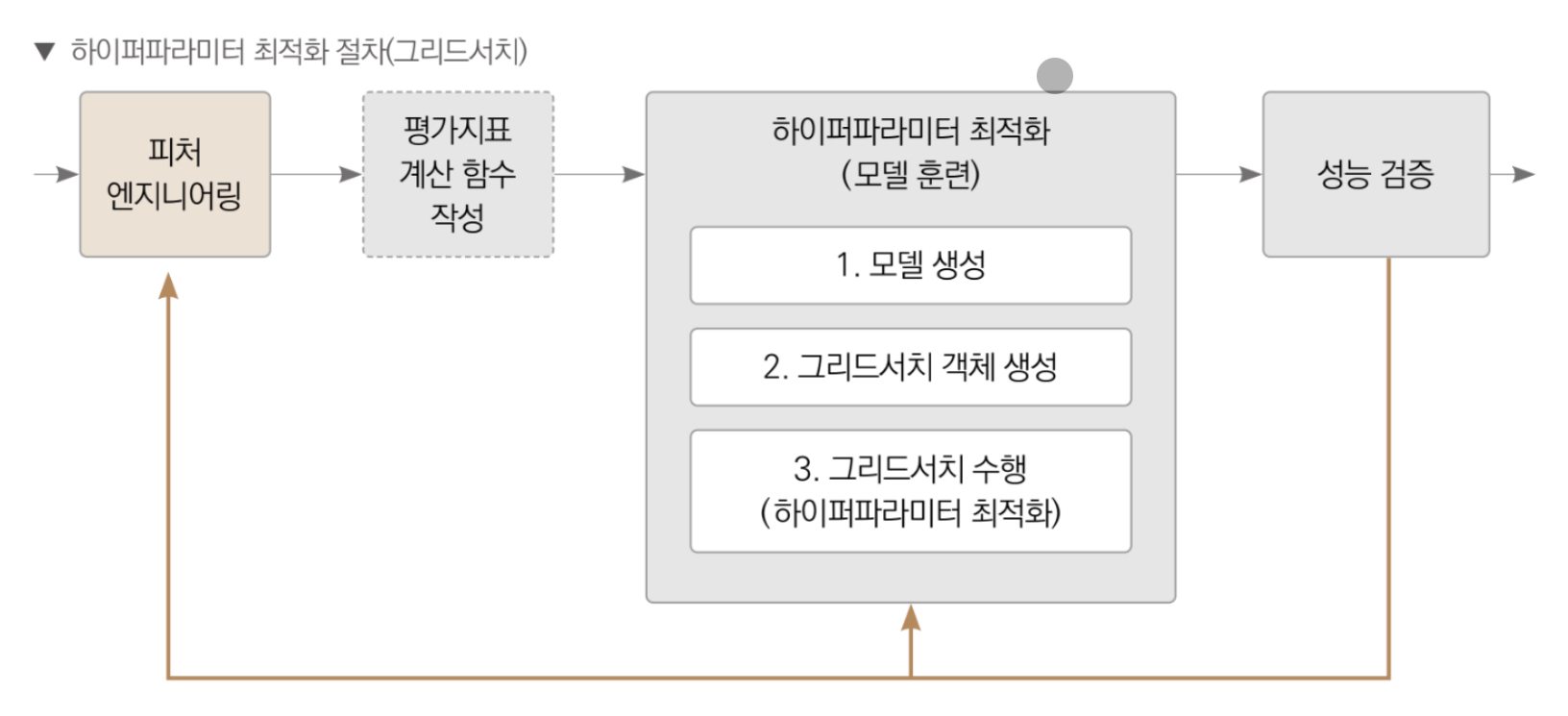
모델 생성
1
2
3
4
5
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
ridge_model = Ridge()
그리드서치 객체 생성
그리드 서치는 ‘하이퍼파라미터의 값’을 바꿔가며 ‘모델’의 성능을 교차 검증으로 ‘평가’해 최적의 하이퍼파라미터 값을 찾아준다. 이는 그리드서치 객체가 다음의 세 가지를 알고 있어야 한다는 뜻이다.
- 비교 검증해볼 하이퍼파라미터 값 목록
- 대상 모델
- 교차 검증용 평가 수단(평가 함수)
1
2
3
4
5
6
7
8
9
10
11
# 하이퍼파라미터 값 목록
ridge_params = {'max_iter': [3000], 'alpha': [0.1, 1, 2, 3, 4, 10, 30, 100, 200, 300, 400, 800, 900, 1000]}
# 교차 검증용 평가 함수(RMSLE 점수 계산)
rmsle_scorer = metrics.make_scorer(rmsle, greater_is_better=False)
# 그리드서치(with 릿지) 객체 생성
gridsearch_ridge_model = GridSearchCV(estimator=ridge_model, # 릿지 모델
param_grid=ridge_params, # 값 목록
scoring=rmsle_scorer, # 평가지표
cv=5) # 교차 검증 분할 수
그리드서치 객체를 생성하는 GridSearchCV()함수의 주요 파라미터는 다음과 같다.
estimator : 분류 및 회귀 모델
param_grid : 딕셔너리 형태로 모델의 하이퍼파라미터명과 여러 하이퍼파라미터 값을 지정
scoring : 평가 지표. 사이킷런에서 기본적인 평가 지표를 문자열 형태로 제공함
예를 들어, 정확도는 ‘accuracy’, F1점수는 ‘f1’, ROC-AUC는 ‘roc_auc’, 재현율은 ‘recall’ 로 표시함.
물론 별도로 만든 평가지표 사용해도 됨.
make_scorer는 평가지표 계산 함수와 평가지표 점수가 높으면 좋은지 등을 인수로 받는 교차 검증용 평가함수임.cv : 교차검증 분할 갯수(기본값은 5)
하이퍼파라미터 값 목록에서 max_iter는 3000으로 고정했고, alpha는 0.1에서 1000까지 설정했다. 그리드서치 객체는 param_grid로 전달된 모든 하이퍼파라미터를 대입해 교차 검증으로 모델 성능 점수를 계산하여 어떤 값일 때 점수가 가장 좋은지 찾아준다.
하나의 하이퍼파라미터 조합 (예: alpha = 0.1)을 평가하기 위해서는 5번의 모델 학습(cv=5) 을 수행하고, 각 학습에서는 최대 3000번까지 반복(max_iter=3000) 하며 학습할 수 있음.
- 실제 반복 횟수는 조기 수렴 때문에 3000보다 작을 수 있음.
따라서
3000 언더 x 5번 이 수행돼야 해당 하이퍼파라미터 조합에 대한 최종 점수 나옴.
총 70(5 x 14)번의 독립된 모델 훈련이 발생하고, 각 훈련은 최대 3000번까지 반복 가능
교차 검증 시에는 해당 경진대회의 평가지표를 그대로 사용해야 한다. 평가 방식이 다르면 최적의 하이퍼파라미터 예상하지 못한 결과를 낼 수 있다.
그리드서치 수행
1
2
3
4
5
6
7
gridsearch_ridge_model.fit(X_train, log_y) # 훈련(그리드서치)
print('최적의 하이퍼파라미터: ', gridsearch_ridge_model.best_params_)
'''
최적의 하이퍼파라미터: {'alpha': 0.1, 'max_iter': 3000}
'''
fit()을 실행하면 객체 생성 시 param_grid에 전달된 값들을 순회하면서 교차 검증으로 평가지표 점수를 계산한다. 이때 가장 좋은 성능을 보인 값을 best_params_ 속성에 저장하며, 이 최적 값으로 훈련한 모델을 best_estimator_ 속성에 저장한다.
성능 검증
그리드서치를 완료하고 나면 그리드서치 객체의 best_estimator_ 속성에 최적 예측기가 저장되어 있다. 따라서 예측은 그리드서치 객체의 best_estimator_ 속성에 저장된 모델로 수행하면 된다.
1
2
3
4
5
6
7
8
9
10
# 예측
preds = gridsearch_ridge_model.best_estimator_.predict(X_train)
# 평가
print(f'릿지 회귀 RMSLE 값 : {rmsle(log_y, preds, True):.4f}')
'''
릿지 회귀 RMSLE 값 : 1.0205
'''
성능 개선 II : 라쏘 회귀 모델
라쏘 회귀모델은 L1규제를 적용한 선형 회귀 모델이다. 앞서 다룬 릿지 회귀 모델과 마찬가지로 성능이 좋은 편은 아니다.
하이퍼파라미터 최적화 (모델 훈련)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from sklearn.linear_model import Lasso
# 모델 생성
lasso_model = Lasso()
# 하이퍼파라미터 값 목록
lasso_alpha = 1 / np.array([0.1, 1, 2, 3, 4, 10, 30, 100, 200, 300, 400, 800, 900, 1000])
lasso_params = {'max_iter':[3000], 'alpha':lasso_alpha}
# 그리드서치(with 라쏘) 객체 생성
gridsearch_lasso_model = GridSearchCV(estimator=lasso_model,
param_grid=lasso_params,
scoring=rmsle_scorer,
cv=5)
# 그리드서치 수행
log_y = np.log(y)
gridsearch_lasso_model.fit(X_train, log_y)
print('최적 하이퍼파라미터: ', gridsearch_lasso_model.best_params_)
'''
최적 하이퍼파라미터: {'alpha': 0.00125, 'max_iter': 3000}
'''
성능 검증
1
2
3
4
5
6
7
8
9
10
# 예측
preds = gridsearch_lasso_model.best_estimator_.predict(X_train)
# 평가
print(f'라쏘 회귀 RMSLE 값: {rmsle(log_y, preds, True):.4f}')
'''
라쏘 회귀 RMSLE 값: 1.0205
'''
성능 개선 III : 랜덤 포레스트 회귀 모델
랜덤 포레스트 회귀는 간단하게 훈련 데이터를 랜덤하게 샘플링한 모델 n개를 각각 훈련하여 결과를 평균하는 방법이다.
Decision Tree 이해
Decision Tree (분류)
[전체 데이터]
|
[나이 < 30세?]
/ \
Yes No
/ \
[소득 > 5000만원?] [구매 = No]
/ \
Yes No
[구매 = Yes] [구매 = No]
- 각 내부 노드는
조건(ex: 나이, 소득 등)을 기준으로 데이터를 나눔 - 각 분기(branch) 는 조건의 참/거짓에 따라 나뉘는 경로
- 각 리프 노드(끝점) 는 최종 예측 결과를 담고 있음
| 용어 | 뜻 |
|---|---|
| 루트 노드 (Root) | 트리의 시작점 (예: 전체 데이터에서 나이 기준 분기) |
| 내부 노드 (Internal Node) | 조건에 따라 데이터를 나누는 노드 |
| 리프 노드 (Leaf) | 예측값이 나오는 최종 노드 |
| 가지/분기 (Branch) | 조건의 결과에 따른 경로 (Yes/No 등) |
Decision Tree (회귀)
[전체 데이터]
|
[온도 < 10℃?]
/ \
Yes No
/ \
[예측값 = 10명] [예측값 = 30명]
하이퍼파라미터 최적화(모델 훈련)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from sklearn.ensemble import RandomForestRegressor
# 모델 생성
randomforest_model = RandomForestRegressor()
# 그리드서치 객체 생성
rf_params = {'random_state':[42], 'n_estimators': [100, 120, 140]}
gridsearch_ramdom_forest_model = GridSearchCV(estimator=randomforest_model,
param_grid=rf_params,
scoring=rmsle_scorer,
cv = 5)
# 그리드서치 수행
log_y = np.log(y)
gridsearch_ramdom_forest_model.fit(X_train, log_y)
print('최적 하이퍼파라미터: ', gridsearch_ramdom_forest_model.best_params_)
'''
최적 하이퍼파라미터: {'n_estimators': 140, 'random_state': 42}
'''
- 그리드서치를 수행할 때 사용한 랜덤 포레스트 회귀 모델의 파라미터는 random_state와 n_estimators이다.
random_state는 랜덤 시드값으로, 값을 명시하면 코드를 다시 실행해도 같은 결과를 얻을 수 있다.
- n_estimators는 랜덤 포레스트를 구성하는 결정 트리 개수를 의미한다.
- 그리드서치는 각 트리 개수에 대해 모델을 따로 학습하고 평가
- 트리의 깊이 (
max_depth)는?- 기본값은
None→ 끝까지 분기 - 트리 하나하나가 노드가 더 이상 나눠지지 않을 때까지 분기함
- 과적합 방지를 위해
max_depth,min_samples_leaf등 설정 가능
- 기본값은
- 예측 방식
| 모델 종류 | 예측 방식 |
|---|---|
RandomForestClassifier | 각 트리의 예측값 중 가장 많은 클래스(다수결) |
RandomForestRegressor | 각 트리의 예측값의 평균 |
Random Forest 학습 흐름
1
2
3
4
5
6
7
1. 학습용 데이터(fold 4개)를 랜덤 포레스트에 입력
2. 각 결정 트리는 아래처럼 독립적으로 학습됨:
- 복원 추출(Bootstrap)로 데이터 샘플 선택
- 특성도 무작위로 일부만 사용 (랜덤성 추가)
- max_depth 등 조건까지 만족하며 트리 생성
3. 이렇게 학습된 n개의 트리의 예측값을 모아
4. 회귀면 평균, 분류면 다수결 → 최종 예측!
랜덤 포레스트 요약
| 항목 | 내용 |
|---|---|
| 트리 개수 | n_estimators |
| 트리 깊이 | 기본은 무제한 (max_depth=None) |
| 트리 학습 데이터 | 각 트리마다 복원 추출 (Bootstrap) |
| 예측 방식 | 회귀 → 평균 / 분류 → 다수결 |
| CV 동작 | fold별로 랜덤 포레스트 모델 따로 학습 & 검증 |
모델 성능 검증
1
2
3
4
5
6
7
8
9
# 예측
preds = gridsearch_ramdom_forest_model.best_estimator_.predict(X_train)
# 평가
print(f'랜덤 포레스트 회귀 RMSLE 값: {rmsle(log_y, preds, True):.4f}')
'''
랜덤 포레스트 회귀 RMSLE 값: 0.1127
'''
선형 회귀, 릿지 회귀, 라쏘 회귀 모델들의 RMSLE 값은 모두 1.02 였음에 반해 랜덤 포레스트 회귀 모델은 0.11로 성능이 가장 좋은것을 확인할 수 있다.
예측 및 결과 제출
성능 측정을 훈련 데이터로 했기 때문에 테스트 데이터에서도 성능이 좋다고 보장할 수 없다. 다행히 본 경진대회는 훈련 데이터와 테스트 데이터의 분포가 비슷하다. 두 데이터 분포가 비슷하면 과대적합 문제가 상대적으로 적기 때문에 훈련 데이터에서 성능이 좋다면 테스트 데이터에서도 좋을 가능성이 크다.
test 데이터셋 예측 결과 분포도 비교
일반적으로는 분포도를 그릴 때 활용 범위가 넓은 displot()을 사용하지만 여기서는 ax 파라미터를 이용하려고 histplot() 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
import seaborn as sns
import matplotlib.pyplot as plt
randomforest_preds = gridsearch_ramdom_forest_model.best_estimator_.predict(X_test)
figure, axes = plt.subplots(ncols=2)
figure.set_size_inches(10, 4)
sns.histplot(y, bins=50, ax=axes[0])
axes[0].set_title('Trian Data Distribution')
sns.histplot(np.exp(randomforest_preds), bins = 50, ax=axes[1])
axes[1].set_title('Predicted Test Data Distribution')
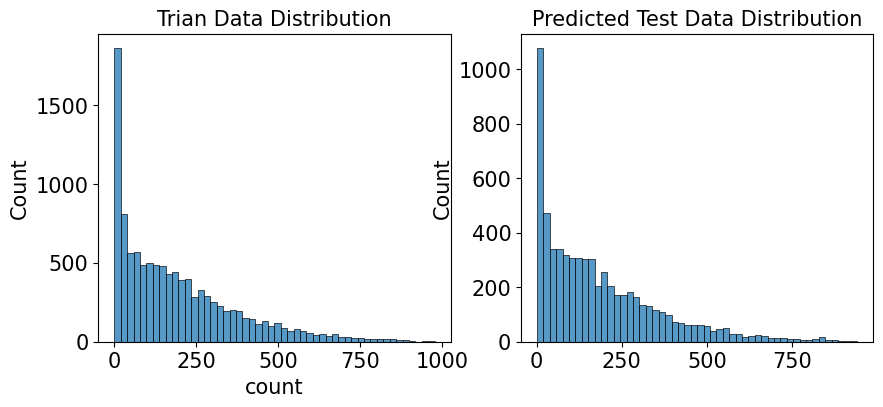
랜덤 포레스트로 예측한 결과를 파일로 저장하고 커밋 후 제출
1
2
3
submission['count'] = np.exp(randomforest_preds) # 지수변환
submission.to_csv('submission.csv', index=False)
1
2
3
4
kaggle competitions submit -c bike-sharing-demand -f submission.csv -m "RandomForest Regression"
100%|█████████████████████████████████████████| 243k/243k [00:02<00:00, 123kB/s]
Successfully submitted to Bike Sharing Demand
정리
| 항목 | Ridge 회귀 | Lasso 회귀 | Random Forest 회귀 |
|---|---|---|---|
| 기본 구조 | 선형 회귀 + L2 정규화 | 선형 회귀 + L1 정규화 | 여러 결정 트리(트리 앙상블) |
| 목적 | 계수 크기 줄이기 (과적합 방지) | 계수 일부를 0으로 만들어 변수 선택 | 다양한 트리 조합으로 성능 향상 |
| 정규화 방식 | L2 (제곱합 규제) | L1 (절댓값 합 규제) | 없음 (정규화 자체는 없음) |
| 예측 방식 | y = wx + b | y = wx + b (일부 계수는 0) | 여러 트리 예측값의 평균 |
| 랜덤성 | 없음 | 없음 | 있음 (데이터 + 특성 랜덤 샘플링) |
| 해석력 | 높음 (계수 확인 가능) | 매우 높음 (특성 선택됨) | 낮음 (블랙박스, 중요도는 확인 가능) |
| 과적합 방지 방식 | 정규화로 모델 복잡도 제한 | 정규화 + 변수 제거 | 다수 트리 앙상블 + 무작위성으로 과적합 방지 |
| 비선형 문제 처리 | 어려움 | 어려움 | 강함 (트리 구조 특성상 비선형 잘 잡음) |
| 실행 속도 | 빠름 (수학적 최적화) | 빠름 | 느림 (트리 여러 개 학습) |
Random Forest 회귀 모델 구조
Decision Tree (회귀) 모델이 n_estimators 만큼 있음
[전체 데이터]
|
[온도 < 10℃?]
/ \
Yes No
/ \
[예측값 = 10명] [예측값 = 30명]
Random Forest
[전체 데이터]
|
+------------------------+
| | |
[Bootstrap] [Bootstrap] [Bootstrap] Bootstrap 샘플링: 복원 추출로 데이터를 랜덤하게 뽑는 방식 (랜덤포레스트 핵심))
샘플링1 샘플링2 샘플링3
| | |
[결정트리1] [결정트리2] [결정트리3] ... (n_estimators 개)
| | |
예측값1 예측값2 예측값3
\ | /
\ | /
[평균 or 다수결]
|
[최종 예측값]
핵심 요약
캐글 경진대회 프로세스는 크게 ‘경진대회 이해’ -> ‘탐색적 데이터 분석’ -> ‘베이스라인 모델’ -> ‘성능 개선’ 순으로 진행된다. 일반적인 머신러닝/딥러닝 문제를 해결할 때도 그대로 적용할 수 있다.
경진대회 이해 단게에서는 대회의 취지와 문제 유형을 정확히 파악하고, 평가지표를 확인한다.
탐색적 데이터 분석 단계에서는 시각화를 포함한 각종 기법을 동원해 데이터를 분석하여, 피처 엔지니어링과 모델링 전략을 수립한다.
베이스라인 모델 단계에서는 본격적인 최적화에 앞서 기본 모델을 제작한다. 유사한 문제를 풀 때 업계에서 흔히 쓰는 모델이나 직관적으로 떠오르는 모델을 선택한다.
성능 개선 단계에서는 베이스라인 모델보다 나은 성능을 목표로 각종 최적화를 진행한다.
- 타겟값이 정규분포에 가까울수록 회귀 모델의 성능이 좋다. 한쪽으로 치우친 타겟값은 로그변환하면 정규분포에 가까워지고, 결과값을 지수변환하면 원래 타겟값 형태로 복원된다(타겟값 변환).
- 훈련 데이터에서 이상치를 제거하면 일반화 성능이 좋아질 수 있다(이상치 제거).
- 기존 피처를 분해/조합하여 모델링에 도움되는 새로운 피처를 추가할 수 있다(파생피처 추가).
- 반대로 불필요한 피처를 제거해주면 성능도 좋아지고, 훈련 속도도 빨라진다(피처 제거).
- 선형 회귀, 릿지, 라쏘 모델은 회귀 문제를 푸는 대표적인 모델이지만, 너무 기본적이라 실전에서 단독으로 최상의 성능을 기대하기는 어렵다.
- 랜덤 포레스트 회귀 모델은 여러 모델을 묶어(대체로) 더 나은 성능을 이끌어내는 간단하고 유용한 모델이다.
- 그리드서치는 교차 검증으로 최적의 하이퍼파라미터 값을 찾아주는 기법이다.